[Feature] Format all TI triggers
Just draft with thoughts.
Remove angle brackets from variables as this is format for prompt, not trigger itself(IMHO).
Remove angle brackets from frontend list, so now you can navigate TI list with keyboard characters.
Do case insensetive find to exclude local TIs from HF TIs(for example i have locally Style-Hamunaptra and HF style-hamunaptra)
Add angle brackets to inserted token. I don't know good idea or not, but by this we sure that only <trigger> and not trigger will refer to our TI.
Also looks like in match_trigger regexp has extra >, so remove it.
Thanks for this. It does at good job at regularizing the treatment of local and dynamically loaded embeds. A couple of problems need to be fixed:
- The textual inversion regression test is failing (see the Checks section). I haven't dug into this, but it looks like more tokens are being inserted than expected when a new trigger term is added. Is it possible that you are adding '<', 'term','>' as three tokens rather than one?
- The embed loading code is crashing when it tries to load a bad embed. Previously it would report the problem and continue. Here are my error messages (EasyNegative.pt is a deliberately corrupted file):
>> Loading embeddings from /data/lstein/invokeai-2.3/embeddings | Loading v1 embedding file: style-hamunaptra | Loading v4 embedding file: embeddings/learned_embeds-steps-500.bin | Loading v2 embedding file: lfa | Loading v3 embedding file: easynegative | Loading v1 embedding file: rem_rezero ** Notice: unrecognized embedding file format: /data/lstein/invokeai-2.3/embeddings/EasyNegative.pt: at position 0, opcode b'<' unknown ** An error occurred while attempting to initialize the model: "'NoneType' object is not subscriptable" ** This can be caused by a missing or corrupted models file, and can sometimes be fixed by (re)installing the models. Do you want to run invokeai-configure script to select and/or reinstall models? [y/N]:
-
Failed test
test_add_embedding_for_known_tokenwhich tests for situation when we already have such token in model, for exampledog, and we trying to load TI withdogtrigger. Old code will inject TI todogtoken and code from this branch will inject to<dog>. So, test see that here created new token -<dog>. As I already said - I don't know if this a god idea, but by this we will know that only<dog>will refer to our TI, while on old code we can refer to TI both bydogand<dog>(it's at least 3 tokens without token injection - '<', 'dog', '>'). So result differs for prompt like -happy dog with another <dog>In 2.3 branchdogand<dog>refers to TI. In this branchdogoriginal and<dog>refers to TI.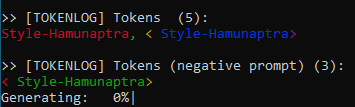
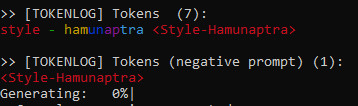
-
My bad, will fix
I've added checks related to < > and etc in #3139. If this PR is going to be merged, I think the necessary changes need to be made to the other one too.