Invalid Tables of Contents with json encoding
e.g. https://openlibrary.org/books/OL15978767M/This_strange_new_feeling
{'level': 0, 'label': '', 'pagenum': '', 'title': 'This strange, new feeling'} {'level': 0, 'label': '', 'pagenum': '', 'title': 'Where the sun lives'} {'level': 0, 'label': '', 'pagenum': '', 'title': 'A Christmas love story.'}
Introduced by Workbot November 5, 2011: https://dev.openlibrary.org/books/OL15978767M/This_strange_new_feeling?b=9&a=8&_compare=Compare&m=diff
@mekarpeles Here's another case: https://openlibrary.org/books/OL5582571M/Understanding_physics.?b=4&a=3&_compare=Compare&m=diff
@mekarpeles One more, dated Oct 17, 2011: https://openlibrary.org/books/OL19395611M/Krokotiili?b=4&a=3&_compare=Compare&m=diff
Here's the JSON for the bad rev (which is slightly different from the first example):
[
{
title: "{'level': 0, 'label': '', 'pagenum': '', 'title': 'Kroktiili'}",
label: "",
pagenum: "",
level: 0
},
{
title: "{'level': 0, 'label': '', 'pagenum': '', 'title': u'Ilke\xe4 tapaus'}",
label: "",
pagenum: "",
level: 0
},
{
title: "{'level': 0, 'label': '', 'pagenum': '', 'title': u'Heikko syd\xe4n.'}",
label: "",
pagenum: "",
level: 0
}
],
They should be pretty easy to find and fix. I can at least do a quick survey to see how prevalent the problem is. I doubt it's very common.
I found a bunch of these in Dostoyevsky editions. One record was done twice: https://openlibrary.org/books/OL16388190M/The_eternal_husband_and_other_stories?b=6&a=5&_compare=Compare&m=diff and then: https://openlibrary.org/books/OL16388190M/The_eternal_husband_and_other_stories?b=8&a=7&_compare=Compare&m=diff
@mekarpeles @tfmorris I've now seen a lot of these. They have a few things in common:
- They were all created by ImportBot (I thing in 2011)
- They all contain non-Latin characters in the table of contents.
- They were all correctly spelled in the MARC records and the pre-revision edition TOC
- The post-revision TOC escaped the non-Latin characters, so Ö became \xd6 e.g. https://openlibrary.org/books/OL14000990M/The_collected_works_of_Henrik_Ibsen?b=8&a=7&_compare=Compare&m=diff
- They can be rescued by copypasting the TOC from the MARC (record 505)
I think part of the context/reason for this is that Bookreader is able to pull tables of contents from the corresponding OpenLibrary book json.
Either way, we should be displaying the tables of contents to users in a human readable way, e.g. like the google books ui:
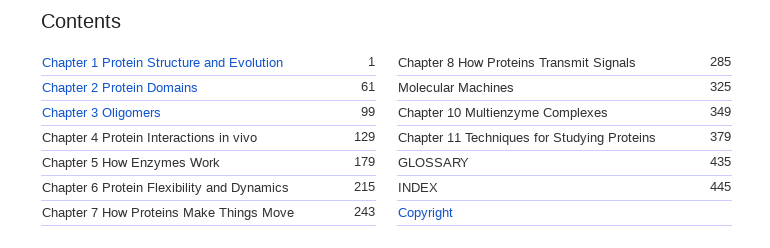
(and not break bookreader's seek-to-chapter feature)
@hornc, if you happen to know:
- Is there a way to look through the data dumps and see how many books are effected?
- And if so, is there a way to easily iterate over affected editions and fix them?
- Is there still an issue which could be causing these issues to happen?
The problem with these records is that the toc_item's title should be a string, but instead is a JSON object (which almost duplicates the toc_item).
# command to list these from a data dump:
zgrep '"table_of_contents": \[[^\]]*"title": "{' ol_dump_editions_2024-03-31.txt.gz
There are 1364 editions with this problem in the ol_dump_editions_2024-03-31.txt.gz dump.
Some of these errors have multiple levels of title nesting, this example has three levels of nesting:
https://openlibrary.org/books/OL13734513M/Samlede_skuespil
I have fixed these by pulling the title and pagenumber out of the inner JSON, and writing to the correct place.
There were also some very broken TOCs with single characters split into multiple entries. I couldn't see an obvious way to repair this class, so I simply removed them.
examples of fixes:
- https://openlibrary.org/books/OL15139312M/The_nineteen_tragedies_and_fragments_of_Euripides?_compare=Compare&b=9&a=8&m=diff
- https://openlibrary.org/books/OL249766M/Heinrich_Heine's_gesammelte_Werke?_compare=Compare&b=11&a=10&m=diff
- https://openlibrary.org/books/OL14032575M/Orations_delivered_at_Harvard_College_1848-1853_i.e._1842-1853?_compare=Compare&b=6&a=5&m=diff
Thanks for tackling this cleanup! I didn't do a comprehensive survey, but it looks like one of the works mentioned in the bug report was missed: https://openlibrary.org/books/OL14000990M/The_collected_works_of_Henrik_Ibsen?b=8&a=7&_compare=Compare&m=diff
Rather than attempting to repair the TOCs, I think it might be easier to just re-import them. For example, your (@hornc ) first example was corrupted multiple times during work merges, but the original MARC 505 is still available at https://openlibrary.org/show-records/marc_miami_univ_ohio/allbibs0116.out:2619524:1546
@tfmorris thanks for spotting the missing records -- there was an error in my regex for finding them.
I've just found about 8000 more records that need TOC clean up!
I had an unnecessary backslash trying to escape a ] which didn't need it.
The correct command to locate these records from a data dump is:
zgrep '"table_of_contents": \[[^]]*"title": "{' ol_dump_editions_2024-03-31.txt.gz
I'll test how reimporting works, and whether they all have contents in the source data. I think I'd have to delete table_of_contents and re-import, and even then I'm not 100% sure TOCs get written when we match, I thought there was some level of selection on which fields can get added.
The above regex picks up a lot of false positives (table of contents with { somewhere in the plain text)
zgrep "\"table_of_contents\": \[[^]]*\"title\": \"{'level" ol_dump_editions_2025-01-08.txt.gz
catches real examples that were missed the first time, e.g. https://openlibrary.org/books/OL2714871M/Five_Complete_Novels_of_Murder_and_Detection