Basic ISBN hyphenation on edition view
Test branch to demonstrate ISBN hyphenation already present in isbnlib.
Uses the already present isbnlib to hyphenate ISBNs on the edition view template.
Technical
Before merging, this will need to handle un-hyphenatable ISBNs (just return the raw string, but possibly notify that there is likely a problem with the ISBN).
Perhaps move it into a util / helper function.
Relates to #6634
A helper function which hyphenates would also be useful for #6516
Testing
An ISBN like number (with validating checkdigit) which cannot be hyphenated using the current (@ June 2022) official ISBN rangefiles is: 9786400042628
isbnlib.mask('9786400042628')
returns None, not an exception.
Invalid check digit ISBNs :
>>> mask('9786400042621')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.6/dist-packages/isbnlib/_ext.py", line 20, in mask
return msk(isbn, separator)
File "/usr/local/lib/python3.6/dist-packages/isbnlib/_msk.py", line 28, in msk
raise NotValidISBNError(isbn)
isbnlib._exceptions.NotValidISBNError: (9786400042621) is not a valid ISBN
This case will also need to be handled.
Screenshot
What the Book details page of an edition page looks like with this change:
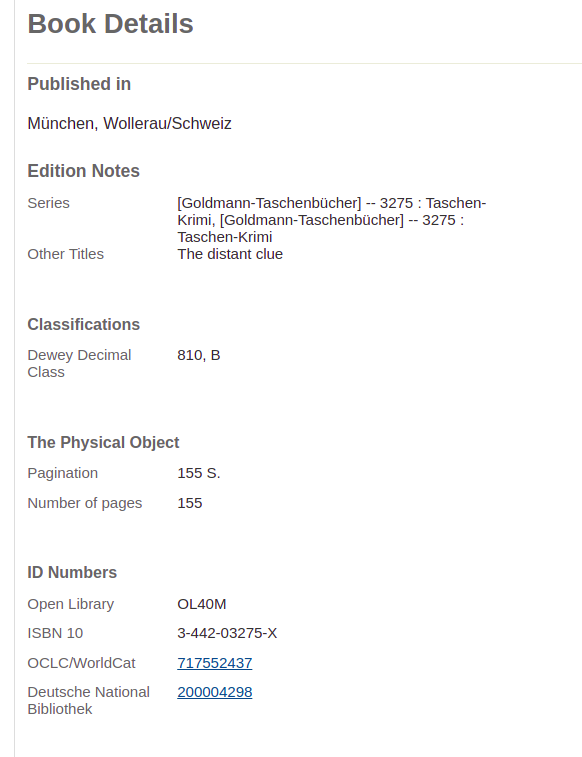
(local URL: http://localhost:8080/books/OL40M )
Updated testing Showing invalid ISBNs left alone:
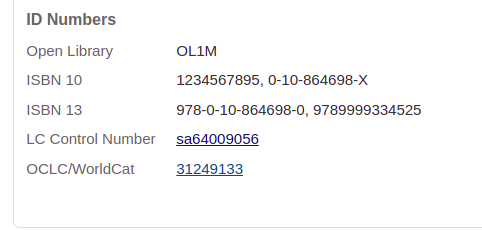
Stakeholders
@seabelis
Do we have a sample list of invalid ISBNs along with some sense of how this code should handle them?
Here's one published but 'bad' ISBN: 7204051613 (https://worldcat.org/isbn/7204051613)
In a separate thing I am working on, I used isbnlib to find 'bad' ISBNs in the Open Library editions dump, there are around 140k editions with bad ISBNs, but there are a number of identical bad ISBNs. I've attached the output, but here's a sampling of 'bad' ISBNs per isbnlib:
2022-09-06 19:27:07.266863: Invalid ISBNs for OL20889210M: ['050'] None
2022-09-06 19:27:07.294719: Invalid ISBNs for OL14334755M: ['915502175'] None
2022-09-06 19:27:07.295268: Invalid ISBNs for OL16280533M: ['9754148194'] None
2022-09-06 19:27:07.295616: Invalid ISBNs for OL22026037M: ['085480045'] None
2022-09-06 19:27:07.296608: Invalid ISBNs for OL22041640M: ['906193086'] None
2022-09-06 19:27:07.297331: Invalid ISBNs for OL16300049M: ['multi046'] None
2022-09-06 19:27:07.297885: Invalid ISBNs for OL21299995M: ['081210420'] None
2022-09-06 19:27:07.298976: Invalid ISBNs for OL16321861M: ['9990881344'] None
2022-09-06 19:27:07.299906: Invalid ISBNs for OL22102597M: ['0860941569'] None
Here's the lot of them: report_bad_isbns.txt
Rather than calling isbnlib.mask() directly, what about calling a function that attempts to hyphenate an ISBN, and if that doesn't work, simply returns the ISBN. E.g.:
import isbnlib
from isbnlib._exceptions import NotValidISBNError
def hyphenate_isbn(isbn: str) -> str:
"""Return a hypenated ISBN, or the input ISBN if it can't be hypenated"""
try:
return isbnlib.mask(isbn)
except NotValidISBNError:
return isbn
Output:
In [2]: hyphenate_isbn("multi046") # invalid
Out[2]: 'multi046'
In [3]: hyphenate_isbn("915502175") # invalid
Out[3]: '915502175'
In [4]: hyphenate_isbn("344203275X") # valid
Out[4]: '3-442-03275-X'
@xlcnd Do you have any advise for us on testing these ISBN data quality and hyphenation issues?
There are a lot of 'bad' ISBNs in databases and catalogues, usually because of an error in the printing of a book, errors in applying the hyphenation rules, and even because a publisher goes rogue! Since the ISBN is used as an identifier for logistics and sales, the publishers normally don't correct the mistake.
So you need to be careful in correcting these mistakes.
Thanks for the reviews all, I have used the invalid examples to add tests for a new util function.
I've imported ISBNLibException because that is the public interface, and handled the case
Where isbnlib.mask() returns an empty string if the checkdigit and ISBN are otherwise valid, but no rules exist to hyphenate it , e.g.:
isbnlib.mask('9789999334525')
''
That's a made up example, I think 9786400042628 is a "real" example found in the wild. I don't really trust these ISBNs as they have been chosen from unallocated therefore unofficial blocks, and may be reallocated in future.
isbnlib won't hyphenate invalid checkdigit ISBNs, even if rules exist to otherwise hyphenate them. I've added a xfail test to make that behaviour explicit, if isbnlib changes, or Open Library wants to handle it differently.
This was discussed today. The fixes the the catalog are absolutely appreciated though @seabelis, @cdrini, myself, and others feel that adding formatting to the ISBN presentation makes it more difficult for many librarians to work with. Goodreads, worldcat, and several other prominent platforms don't stylize ISBNs with hyphens.
Given these details, I'd appreciate if we can hold off on making the UI part of this change-set for now.
Ok @mekarpeles this was meant to be an experiment to show what it would look like and prompt discussion, and demonstrate that the existing isbnlib tool used can do the job, so the effort to add the feature is not high.
It has shown isbnlib can do the task, and has prompted discussion, so that' s good :)