Playbooks (solves #628)
Description
Playbooks are simple JSON configs that help scan observables/files in mass properly.
- [x] New feature (non-breaking change which adds functionality).
Checklist
- [x] I have read and understood the rules about how to Contribute to this project
- [x] The pull request is for the branch
develop - [x] If external libraries/packages with restrictive licenses were used, they were added in the Legal Notice section.
- [ ] The tests gave 0 errors.
- [x] Linters (
Black,Flake,Isort) gave 0 errors. If you have correctly installed pre-commit, it does these checks and adjustments on your behalf. - [ ] If changes were made to an existing model/serializer/view, the docs were updated and regenerated (check CONTRIBUTE.md).
Important Rules
- If your changes decrease the overall tests coverage (you will know after the Codecov CI job is done), you should add the required tests to fix the problem
- Everytime you make changes to the PR and you think the work is done, you should explicitly ask for a review
Real World Example
This pull request introduces 9 alerts when merging 6696e39412bb2da0714e54f378eaeec9793baba1 into 0ed59ef9a06e80bc4cd99c803ba4b09db26634cb - view on LGTM.com
new alerts:
- 8 for Unused import
- 1 for Unused local variable
This pull request introduces 3 alerts when merging 45762ed21ce35e4655a5a6f6f71086eb4a7cf648 into 0ed59ef9a06e80bc4cd99c803ba4b09db26634cb - view on LGTM.com
new alerts:
- 3 for Unused import
Just an overall comment on the code: i really like the structure, it follows all the other IntelOwl code, and it is well structured. Nothing to change on that side, is very legit. The most important issue that I see anyway, is shared code. There are a lot of code that you took from other parts of IntelOwl, copy-pasted it in the app, and made some slight changes here and there. The issue with that is now we have
- double the code to maintain.
- if you make a change in the shared code, you have to remember to make the same change in the other part As you can see, in the long run this will create a lot of issues. The best solution for this problem is to wrap the copied function and, if there is necessary, make some changes/extend this function to suit your use case.
I will give 0 comments on the frontend, @drosetti will review that, since I have pretty much zero knowledge on that and I do not want to say useless/wrong stuff
You forgot to make the database migrations and analysis don't work. Pleas solve this problem, in this way I can run the analysis and check also the UX.
As far as I am aware, it should work by itself if you start IntelOwl in a fresh environment. Database migrations are something you would need to fix for your specific environment right? Once that's taken care of, The analysis does work.
No: when IntelOwl starts it applies the existing migrations, but it doesn't create the migrations. You can check the list of migrations in api_app/migrations folder. When you create you migration please give to it a name related to this feature.
Edit: However after applying the new migration the playbook works, after you fix the migration issue, I will proceed with the code review.
@drosetti Hey, I have put the migrations together. Please see if this works. After I merged the code with that of the new version, I have been having some troubles with the UX working. As in, The toasts for my code aren't activating when I want them to. I would recommend that you take a look and help me with that.
Other than that, I showed the basic look to @eshaan7 and we came to the conclusion that for now, I can proceed to make a quick PR so that at least we can move forward to working on the rest with @devmrfitz
Also, @0ssigeno or @mlodic I have made all the changes requested. You should be able to make another review. Thank you for your kind feedback.
This pull request introduces 1 alert when merging e72a8a87841a3fc0290dc277d5d4ac807b6d950e into f039cec2c392581eb47f6a9631e228b52393a2ee - view on LGTM.com
new alerts:
- 1 for Unused import
Thank you for the code review. It's a nice learning experience to have your code criticized to make it as readable as possible by someone as experienced as you folks!
This pull request introduces 3 alerts when merging 89d845e5222d9e5099d561fefd76b66f009cb1b9 into 9a82ac93ef4c966c8a73f384ff17c60a66b9cebe - view on LGTM.com
new alerts:
- 2 for Unused local variable
- 1 for Unused import
Please review for the last time @mlodic @drosetti @0ssigeno. All bugs are fixed. Only docs are left (I don't want this PR to be stuck. The more stuck it gets, the more merge conflicts I would have to take care of). I would open a separate PR for it and do it with the SDK support work at PyIntelOwl.
please pull recent changes from develop because there are still inconsistencies. We won't merge anything else before this PR so I assure you this is the last time you need to pull from there.
One example is that there are incosistent migrations:
intelowl_uwsgi | CommandError: Conflicting migrations detected; multiple leaf nodes in the migration graph: (0010_custom_config, 0010_playbooks in api_app).
You can just put 0010_playbooks in api_app after 0010_custom_config. This problem was raised by the Tests.
Could you also fix the CodeFactor issues and all the Django Doctor raised issues?
Once all of that is done, I can do a proper review of the result. Thank you!
Also please populate the PR template cause there are other things to be handled like the docs.
(Please add to the PR name the issue/s that this PR would close if merged by using a Github keyword. Example: closes #999. If your PR is made by a single commit, please add that clause in the commit too. This is all required to automate the closure of related issues.)
Description
Please include a summary of the change.
Type of change
Please delete options that are not relevant.
- [ ] Bug fix (non-breaking change which fixes an issue).
- [ ] New feature (non-breaking change which adds functionality).
- [ ] Breaking change (fix or feature that would cause existing functionality to not work as expected).
Checklist
- [ ] I have read and understood the rules about how to Contribute to this project
- [ ] The pull request is for the branch
develop - [ ] A new analyzer or connector was added, in which case:
- [ ] Usage file was updated.
- [ ] Advanced-Usage was updated (in case the analyzer/connector provides additional optional configuration).
- [ ] Secrets were added in env_file_app_template, env_file_app_ci and in the Installation docs, if necessary.
- [ ] If the analyzer/connector requires mocked testing,
_monkeypatch()was used in its class to apply the necessary decorators. - [ ] If a File analyzer was added, its name was explicitly defined in test_file_scripts.py (not required for Observable Analyzers).
- [ ] If external libraries/packages with restrictive licenses were used, they were added in the Legal Notice section.
- [ ] The tests gave 0 errors.
- [ ] Linters (
Black,Flake,Isort) gave 0 errors. If you have correctly installed pre-commit, it does these checks and adjustments on your behalf. - [ ] If changes were made to an existing model/serializer/view, the docs were updated and regenerated (check CONTRIBUTE.md).
Important Rules
- If your changes decrease the overall tests coverage (you will know after the Codecov CI job is done), you should add the required tests to fix the problem
- Everytime you make changes to the PR and you think the work is done, you should explicitly ask for a review
Real World Example
Please delete if the PR is for bug fixing. Otherwise, please provide the resulting raw JSON of a finished analysis (and, if you like, a screenshot of the results). This is to allow the maintainers to understand how the analyzer works.
Without any error that broke the build, I finally managed to review the GUI and the user experience. This PR has been broken for a about a month and we wasted a lot of time without doing any progress. It is time to make this PR right so we can finally merge it.
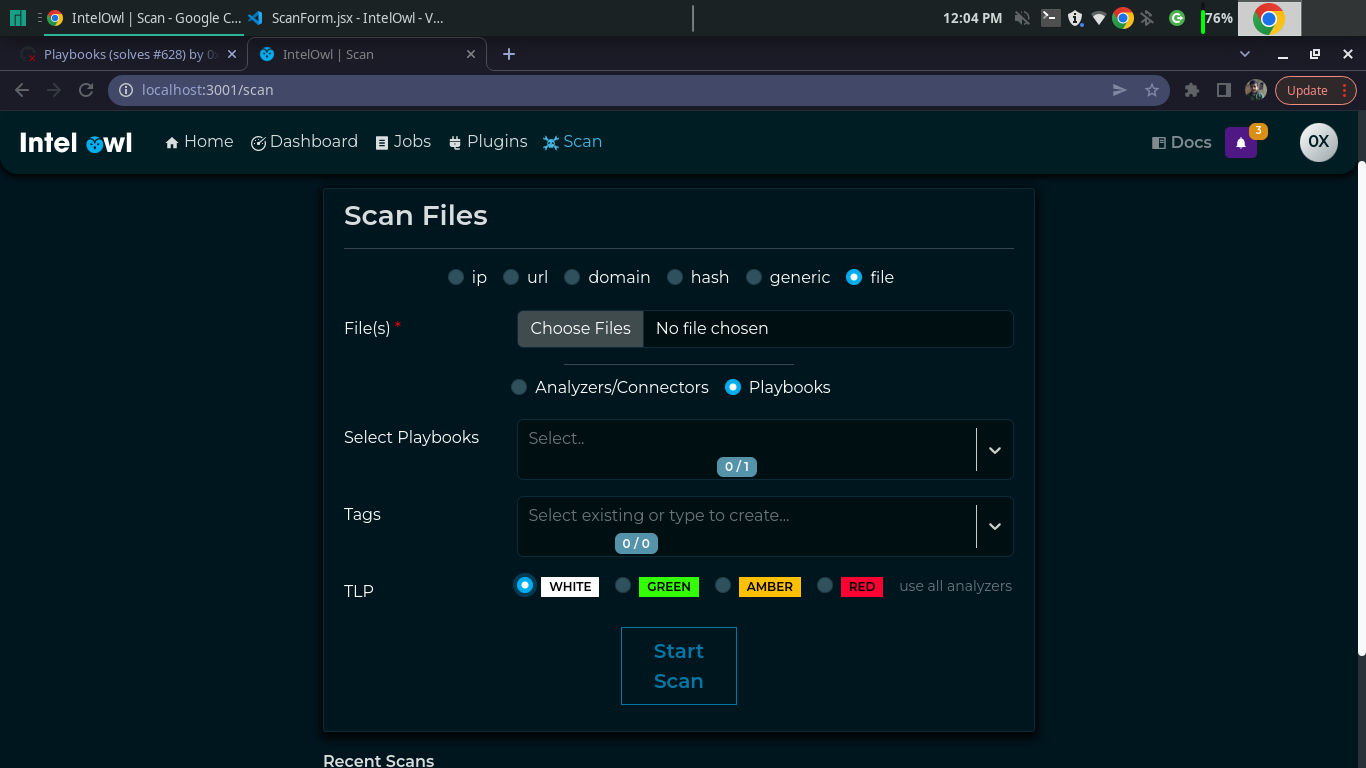
- [x] Unfortunately, I am sad to say that the overall user experience imho is really bad. We cluttered the "Scan" page with unnecessary content and we never thought about optimizing it.
Adding the following lines is not good at all:
 The result for the user is complete chaos and the overall result is worse than before. Better not having this feature than having it put in the GUI in this way.
So, now we need to find a right way optimize this page and avoid to make it impossible to use.
First: the "Launch playbooks" button should not exist. The "Start Scan" button should do the job. "But there are 2 different APIs, one for the playbooks and one for the normal scan". We need to handle this. If the user selected at least a playbook, the playbooks would be run. Otherwise the analyzers/connectors. Plus, it makes no sense to set as default that all the playbooks are triggered. Playbooks are a combination of analyzers/connectors that could overlap over each other so basically it makes absolutely no sense. The user should explicitly select them.
Then, how to avoid to have all of this together?
The result for the user is complete chaos and the overall result is worse than before. Better not having this feature than having it put in the GUI in this way.
So, now we need to find a right way optimize this page and avoid to make it impossible to use.
First: the "Launch playbooks" button should not exist. The "Start Scan" button should do the job. "But there are 2 different APIs, one for the playbooks and one for the normal scan". We need to handle this. If the user selected at least a playbook, the playbooks would be run. Otherwise the analyzers/connectors. Plus, it makes no sense to set as default that all the playbooks are triggered. Playbooks are a combination of analyzers/connectors that could overlap over each other so basically it makes absolutely no sense. The user should explicitly select them.
Then, how to avoid to have all of this together?
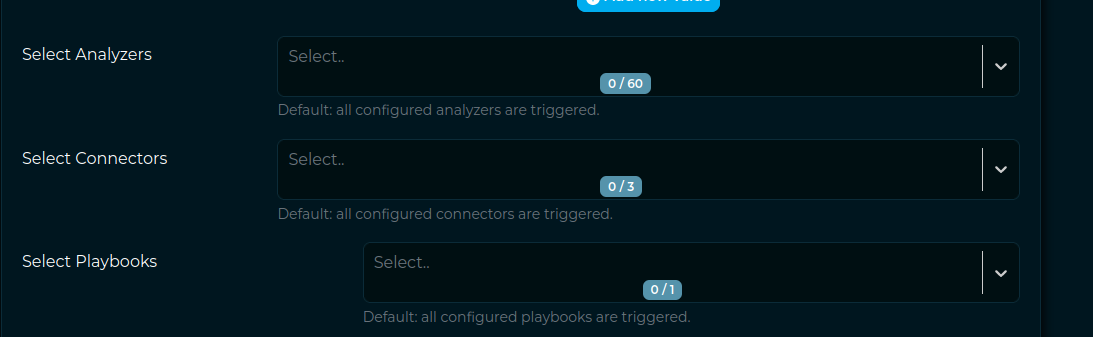 Analyzers and connectors together make sense but Playbooks does not. Either you select playbooks or you select analyzers/connectors so logically we should split the view.
The very basic idea that I have is to do something similar to what we already do for the observables/files radio button.
I would add a new radio button with 2 options: 1-analyzers/connectors 2-playbooks
In the first case, the user would see only the selectors of analyzers and connectors. In the second case it would see only the playbook selector.
I'll edit this as soon as I complete my review.
Analyzers and connectors together make sense but Playbooks does not. Either you select playbooks or you select analyzers/connectors so logically we should split the view.
The very basic idea that I have is to do something similar to what we already do for the observables/files radio button.
I would add a new radio button with 2 options: 1-analyzers/connectors 2-playbooks
In the first case, the user would see only the selectors of analyzers and connectors. In the second case it would see only the playbook selector.
I'll edit this as soon as I complete my review.
EDIT Other todos:
-
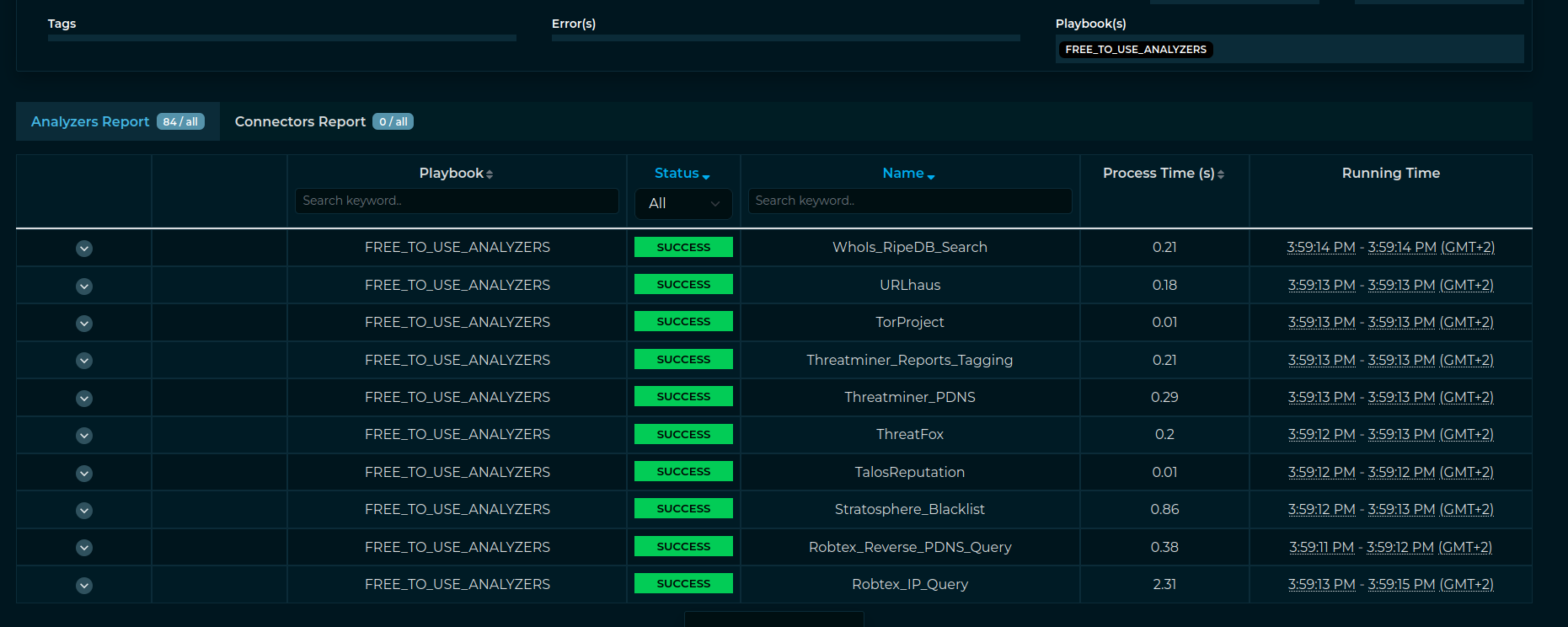
[x] The "Name" column is obviously too little if compared to the Description section. We need to fix this.

-
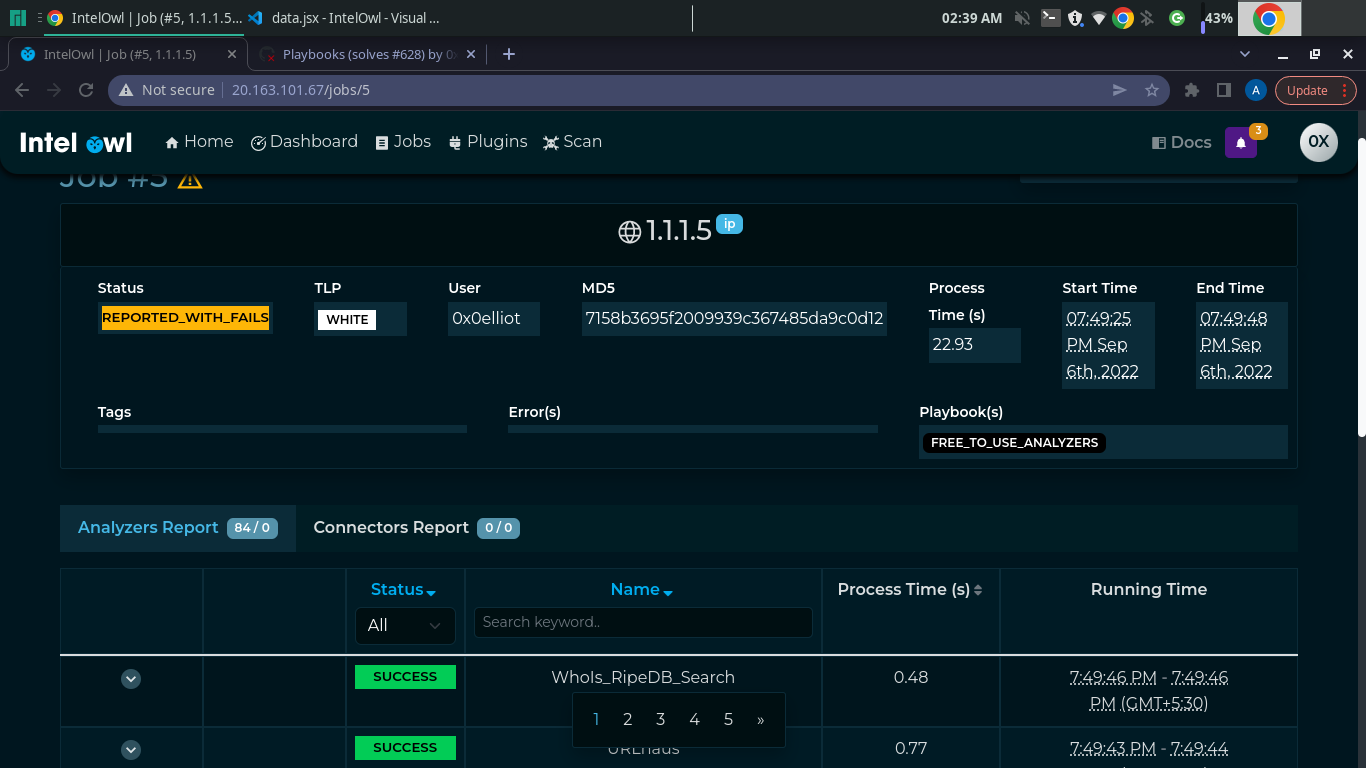
[x] While it is cool to have a section in the header with the playbook selected, it is not cool at all to have a huge column with the name of playbooks selected. In the majority of cases the user would run either no playbooks or a single playbook. So, if we run less than 2 Playbooks at the same time, we should hide the "Playbooks" column from the results because it just clutter the page.
-
[x] This is a little tweak but in case there are Playbooks executed we should show in the Job Result page the real number of the analyzers/connectors run instead of "all" that is the default

-
[ ] I also noticed that if I execute the "FREE_TO_USE_ANALYZERS" playbook for an IP, the Job Would try to execute also non-supported analyzers, like the ones for files.
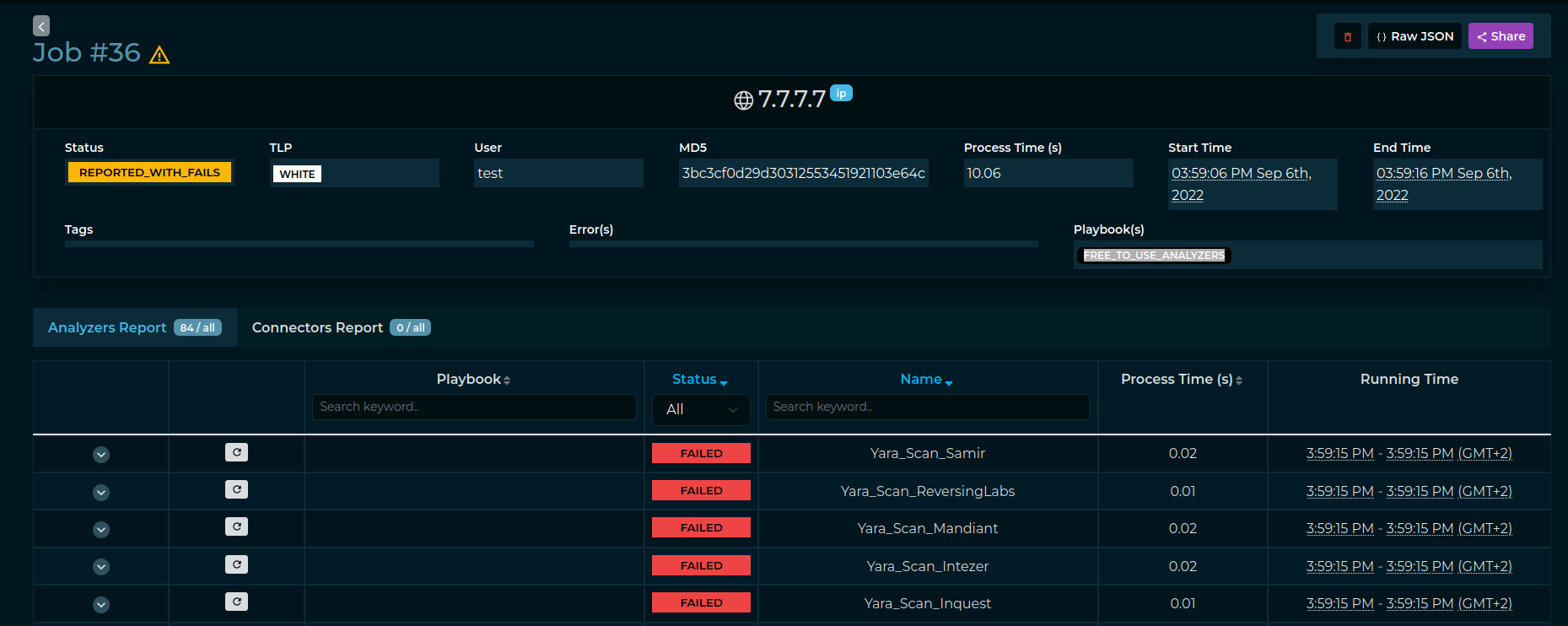
-
[ ] In the
_multi_analysis_requestfunction there are basically 2 different flows for playbooks and non-playbooks. While this could make sense on one side, on the other we are skipping the validation that we implemented in the Observable and File Serializers and complicate everything. Playbooks should just be an abstraction of a normal Job so it does not make sense to separate the flows. This is what causes the previously mentioned problem. Playbooks analysis skip all the observables/files checks in the serializers, while, on the contrary, we should leverage them. One idea could be to rewrite the_multi_analysis_requestto avoid using if/else and leveraging the same flows. -
first, transform the
filter_playbooksin Playbook Serializers which would extend the already existingObservableSerializerandFileSerializer -
then remove the other if/else available on the code. Remove the "start_playbooks" task and just leverage the "start_analyzers" with the pre-configured analyzers
-
ultimately merge PlaybookAnalysisResponseSerializer and AnalysisResponseSerializer in a single response serializer
the feedback is duly noted and appreciated. would wrap up the frontend changes soon so that we can go on a call tomorrow to discuss the backend refactor and any UX improvements/specifications.
Will fix the test cases as I go. Don't worry. Focusing more on making the UX better for the time being.
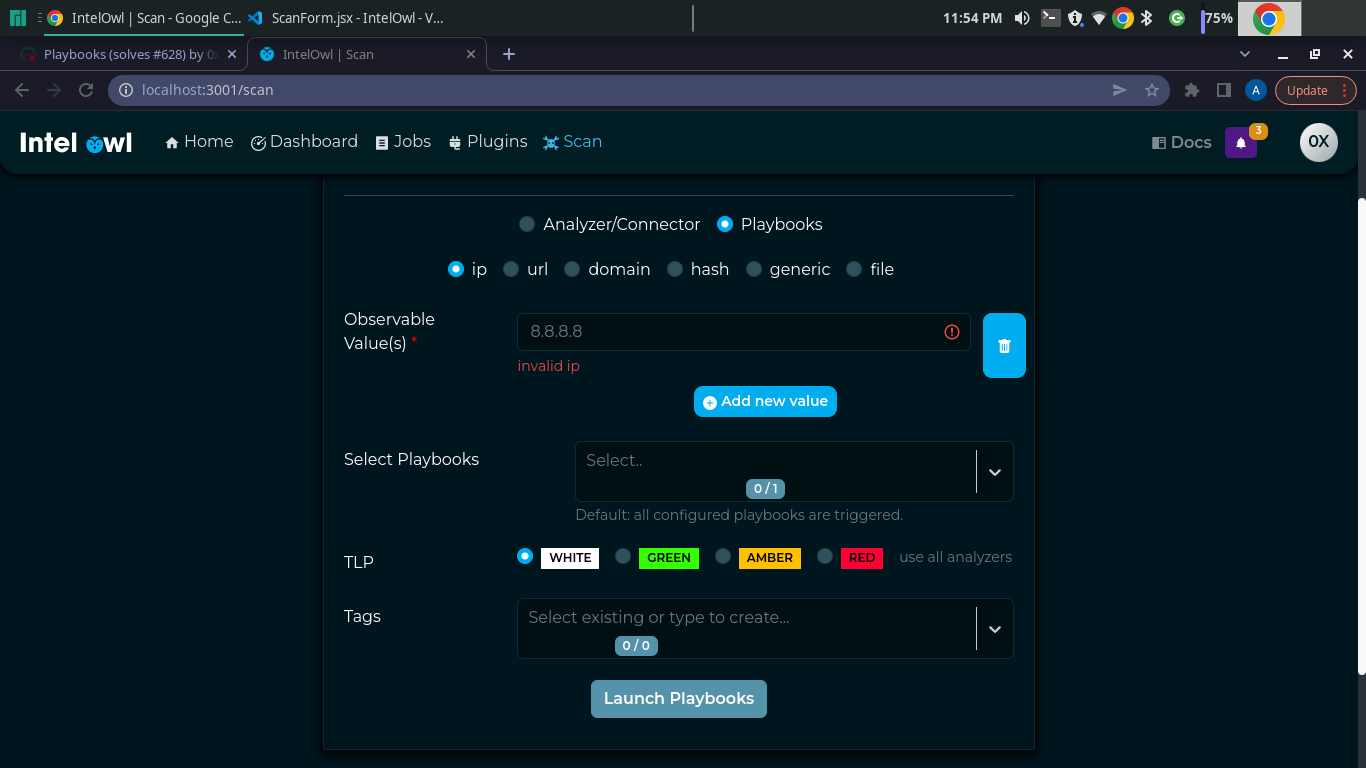
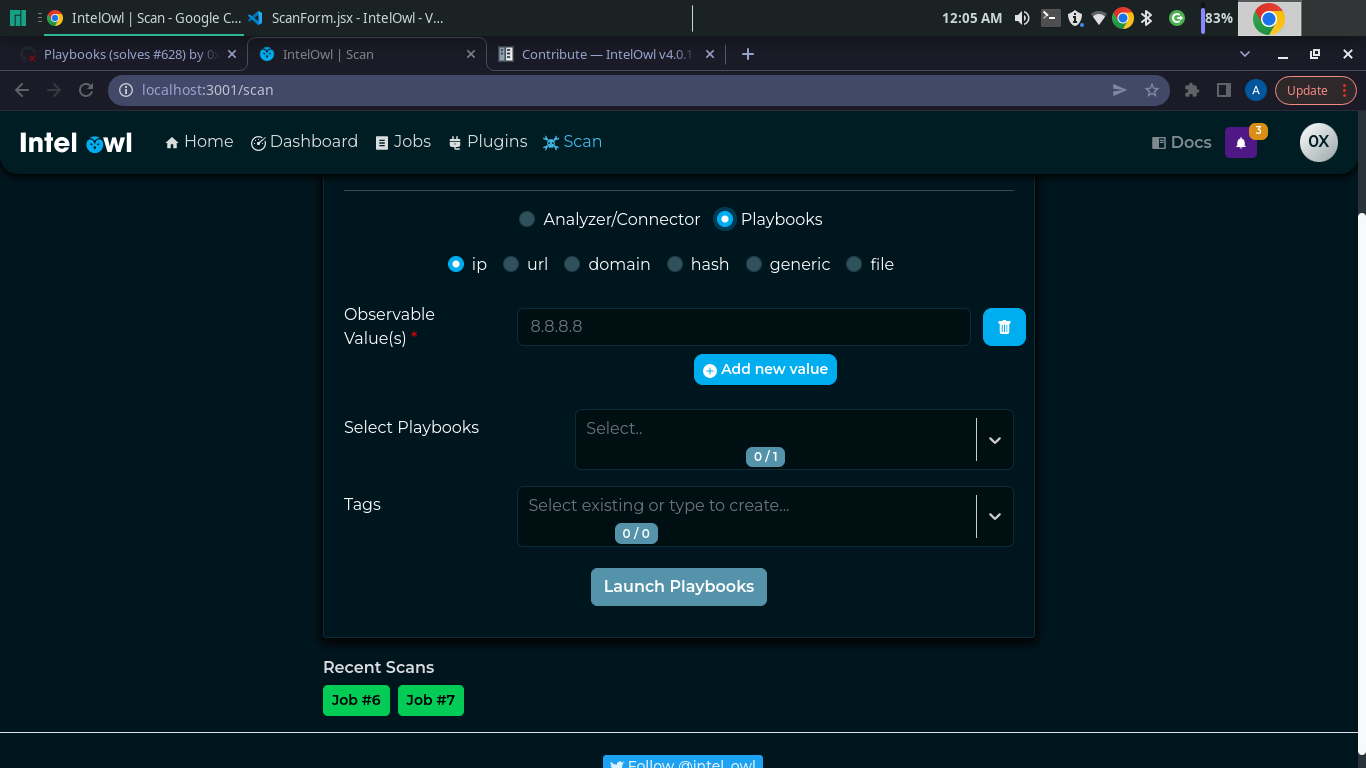
quick question, do i just let this warning stay?
> Line 155:67: '_quota' is assigned a value but never used no-unused-vars
https://github.com/intelowlproject/IntelOwl/blob/ba8a4f42bc60a3e5b6b6c286a540f38e6e6b9bfc/frontend/src/components/scan/ScanForm.jsx#L140 never really calls _quota again in this code.
i fixed all known frontend bugs from my side. fixed the UX as well. what's left is the backend now!! (and mentor reviews of course. there is always something new to fix there.) :tada: :tada: :tada: :tada:
More todos:
- [ ] modify test cases that support run_all for playbooks disabled
- [ ] fix failing test cases for backend tests after figuring out why
hey there! new changes mmmm looking into them :P
Progress on the UI
Great, so you separated playbooks and analyzers/connectors. Some little tweak to consider:
- [x]
sis missing in analyzers/connectors - [x] why "select playbooks" input field is not aligned with the others?
- [x] I would still use the same "Scan" button for both visualizations (analyzers and playbooks). It makes no sense for an user to have 2 different buttons there because they both start an analysis. Plus, in the playbook case it should be disabled if no playbooks are selected.
- [x] is there a reason why TLP is removed for playbook? Because it shouldn't. All the logic outside analyzer/connectors selection should be exactly the same between playbooks and classic analysis. Playbooks should only allow fast selection of analyzers/connectors, nothing else. All the rest should be the same
quick question, do i just let this warning stay?
that is something erronously left by copy/pasted Eshaan's code from Dragonfly. If it does not create any real problem you can leave it there because we will probably add some "quota" counter feature in the near future here too.
EDIT:
- [x] could you also move the "analyzers - plyabooks" radio button after the observables selection? Why? Because the user experience should be linear. The user should start from the top and then modify the form down to the bottom. In your case, you first select the analyzers/playbooks radio button but then you select the analyzers/playbooks later in the form. They should be kept one next to each other. Also, to allow a better understanding of the separated sections, a grey line between the observables/file selection and the analyzers/playbooks selection would help the user eyes.
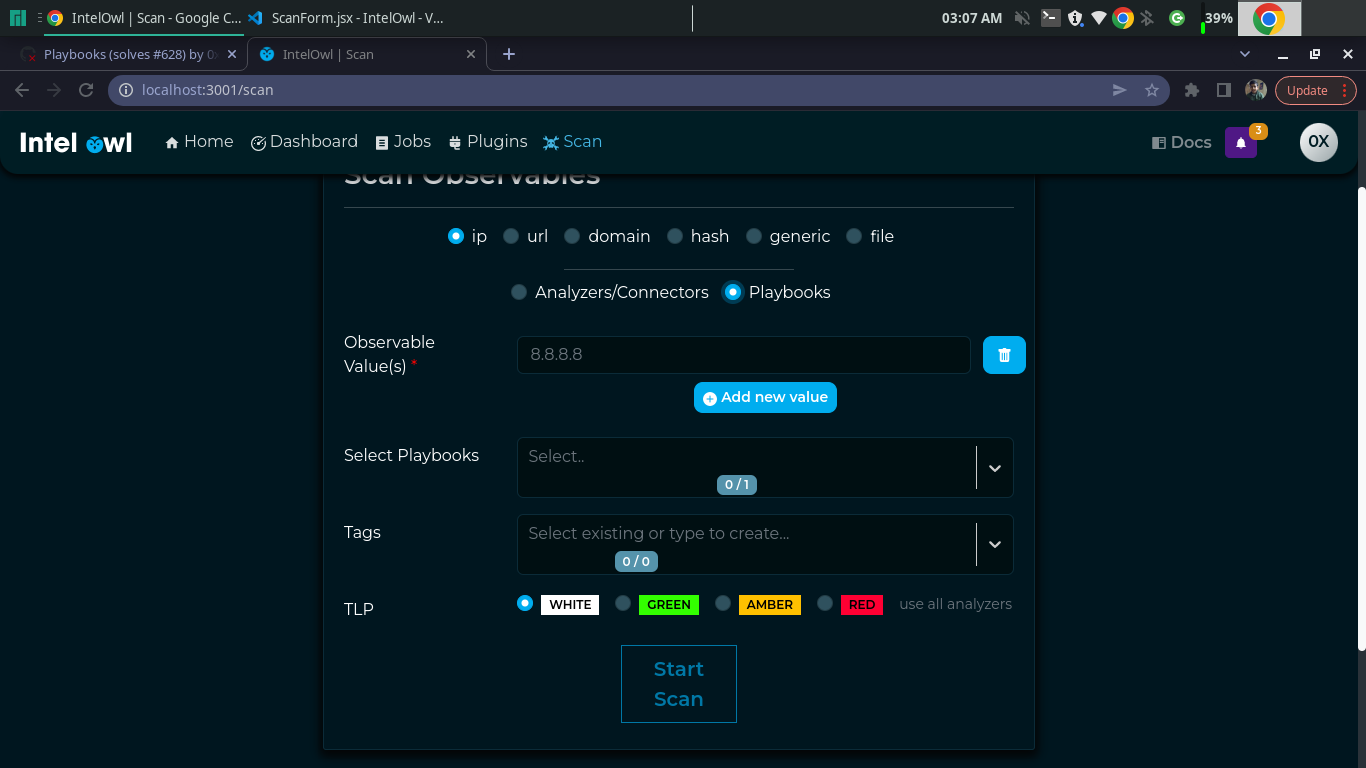
neat. time to work on the backend. feel free to review for improvements @mlodic
checking details on the frontend. Overall result: cool!
"Scan page":
- [x] I think my explanation wasn't the most comprehensible so I have a screenshot of how was my idea about the separation of the sections there
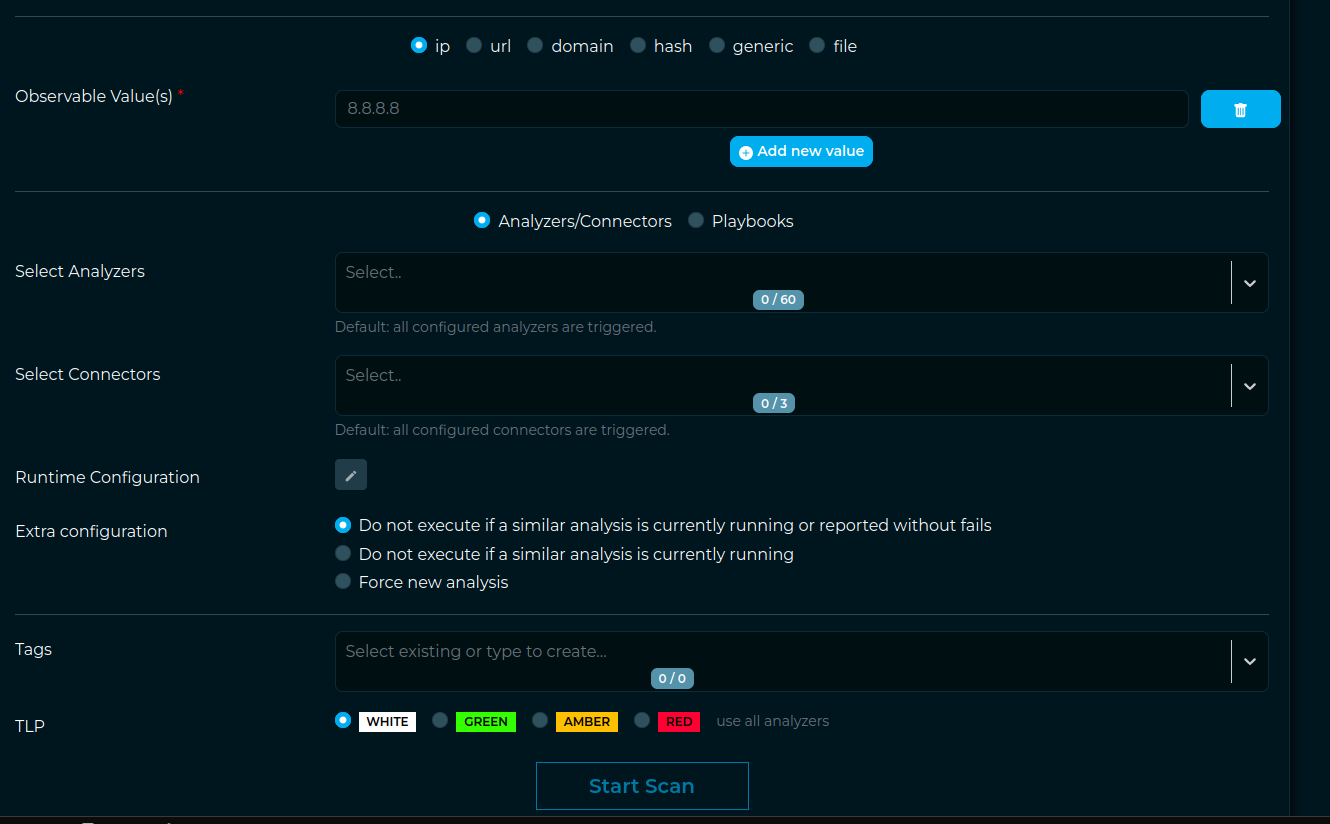 As you can see here I logically separated the 2 sections (observables and analyzers/connectors) that are modified if I change my selection in the radio buttons. In that way it is easier for the user to get what changes there are between visualizations. That's a fast change to do in the code I guess.
As you can see here I logically separated the 2 sections (observables and analyzers/connectors) that are modified if I change my selection in the radio buttons. In that way it is easier for the user to get what changes there are between visualizations. That's a fast change to do in the code I guess. - [x] Other question: I see that for playbooks the "Extra configuration" section was removed. This is because we are not doing a check for already existing playbooks running, right? I am talking about the
ask_multi_analysis_availabilityfunction that we call before running analyzers/connectors normaly. Logically, it would make sense to have the same check for playbooks. But I understand that this would add additional burden. Let's ignore this for now. I'll open an issue - [x] Tags selection in playbooks do not work but this is caused to the problem we already talked about (we need to use the same validation/serializers that we use for classic analysis)
I think my explanation wasn't the most comprehensible so I have a screenshot of how was my idea about the separation of the sections there
got it. i will just shift my code to that part.
Other question: I see that for playbooks the "Extra configuration" section was removed. This is because we are not doing a check for already existing playbooks running, right? I am talking about the ask_multi_analysis_availability function that we call before running analyzers/connectors normaly. Logically, it would make sense to have the same check for playbooks. But I understand that this would add an additional burden. Let's ignore this for now. I'll open an issue
yes doing it right now wouldn't be right. but speaking of this, i wanted to bring this up to your attention but i think we should make it so that instead of it using cached results for a whole playbook, this feature takes the cached result for individual analyzers. this is a better solution now that we are moving in the direction of bulk searching. this is of course for whenever it is done.
Tags selection in playbooks do not work but this is caused to the problem we already talked about (we need to use the same validation/serializers that we use for classic analysis)
yes of course. this will be fixed with the backend!