Haproxy-Keepalived not starting haproxy (multiple errors)
Hi I have a couple of errors using this image and I was wondering if it can be updated to support vrrp_track_process haproxy.
Receiving the following error message Keepalived_vrrp[20]: WARNING - the kernel does not support proc events - track_process will not work
Additionally when I specify my own haproxy.conf as stated in the ReadMe section. The Haproxy does not seem to start. Here's my docker run command
docker run -it -d --cap-add=NET_ADMIN --name haproxy-keepalived --net=host --privileged --userns=host --restart on-failure -v /home/da/.haproxy-keepalived/haproxy:/usr/local/etc/haproxy.cfg:ro -v /home/da/.haproxy-keepalived/keepalived/keepalived.conf:/etc/keepalived/keepalived.conf:ro instantlinux/haproxy-keepalived:latest
If I map /home/da/.haproxy-keepalived/haproxy:/usr/local/etc/haproxy.d haproxy works just fine but then it throws other errors regarding the stats section.
[NOTICE] (24) : haproxy version is 2.6.0-a1efc04
[ALERT] (24) : config : Parsing [/usr/local/etc/haproxy.d/haproxy.cfg.old:13]: frontend 'stats' has the same name as proxy 'stats' declared at /usr/local/etc/haproxy/haproxy.cfg:18
My haproxy.conf
stats socket /var/run/api.sock user haproxy group haproxy mode 660 level admin expose-fd listeners
stats socket ipv4@*:9999 level admin expose-fd listeners
log stdout format raw local0 notice emerg
defaults
mode http
timeout client 120s
timeout connect 5s
timeout server 10s
timeout http-request 120s
log global
frontend stats
bind *:9000
stats enable
stats uri /stats
stats refresh 10s
stats auth statsadmin:password
frontend eth-mainnet
bind *:18545
mode http
default_backend eth-mainnet
timeout client 120s
timeout http-request 120s
backend eth-mainnet
option httpchk
balance roundrobin
mode http
timeout server 120s
server host1 192.168.1.10:8545 check
server host2 192.168.1.11:8545 check
Can you check the path name of the haproxy.cfg mount? I see this in your command line:
docker run -it -d --cap-add=NET_ADMIN --name haproxy-keepalived \
--net=host --privileged --userns=host --restart on-failure \
-v /home/da/.haproxy-keepalived/haproxy:/usr/local/etc/haproxy.cfg:ro \
-v /home/da/.haproxy-keepalived/keepalived/keepalived.conf:/etc/keepalived/keepalived.conf:ro \
instantlinux/haproxy-keepalived:latest
Path name to override the haproxy.cfg file is /usr/local/etc/haproxy/haproxy.cfg. That, I think, is why you're encountering the conflict with frontend stats. I'll fix the README (which had the path name /etc/haproxy, from an earlier version of the container before the package moved this to /usr/local/etc).
I will spin up my dev environment to test again. Also can you please look into this error Keepalived_vrrp[20]: WARNING - the kernel does not support proc events - track_process will not work I think it is related to the version of the image being used. Details on how to use track_process just in case https://www.redhat.com/sysadmin/advanced-keepalived
Also can you please update both keepalived and haproxy to the latest version.
Keepalived is already current at 2.2.7; I bumped haproxy from 2.6.0 to 2.6.4 (version 2.7 is still in development). The author of keepalived had this to say about track_process in Jan 2021:
Since I do not get the warning, it is difficult to work out why you are getting it.
When I wrote the code, the only way I could discover to be able to detect of the kernel supported the proc events connector was to check if after opening the connector a PROC_EVENTS_NONE message was received. keepalived allows 1/10 second after opening the connector to receive the message and if it is not received in that time logs the warning.
If you run keepalived and add the -D command line option, you should get a log message "proc_events has confirmed it is configured". With the -D option, do you get such a message, and if so is it before or after the warning message?
You ask two questions: Is the error message correct - you appear to answer that yourself by saying that proc events is working. Should it raise an error rather than a warning - what would you expect keepalived to do differently if it raised an error? It can't treat it as a config error, since keepalived can't detect the problem until after it has started running the configuration.
If you build keepalived with the --enable-track-process-debug configure option, and then when you run keepalived add the --debug=OA option, then keepalived will log all messages received on the proc event connector, and it should then be possible to see what it happening.
If we are to investigate the problem beyond that, we will need the following information:
- What distro you are using and the version
- The kernel version
- The kernel configuration
- Your keepalived configuration
- The output of: keepalived -v
I hope that helps,
Quentin Armitage
As with the author's assessment, I cannot reproduce the issue. There is something about the kernel environment you're running that differs from mine (Ubuntu 20.04, kernel version 5.4.0-121, docker-ce 19.03.13) that is triggering the track_process warning.
Here's a report of this similar issue with track_process https://github.com/acassen/keepalived/issues/1469#issuecomment-575577542
My environment is:
Linux version 5.15.0-41-generic (buildd@lcy02-amd64-105) (gcc (Ubuntu 9.4.0-1ubuntu1~20.04.1) Docker version 20.10.17, build 100c701
Can you check the path name of the haproxy.cfg mount? I see this in your command line:
docker run -it -d --cap-add=NET_ADMIN --name haproxy-keepalived \ --net=host --privileged --userns=host --restart on-failure \ -v /home/da/.haproxy-keepalived/haproxy:/usr/local/etc/haproxy.cfg:ro \ -v /home/da/.haproxy-keepalived/keepalived/keepalived.conf:/etc/keepalived/keepalived.conf:ro \ instantlinux/haproxy-keepalived:latestPath name to override the haproxy.cfg file is
/usr/local/etc/haproxy/haproxy.cfg. That, I think, is why you're encountering the conflict withfrontend stats. I'll fix the README (which had the path name/etc/haproxy, from an earlier version of the container before the package moved this to/usr/local/etc).
It is not happy /usr/local/bin/entrypoint.sh: line 10: can't create /usr/local/etc/haproxy/haproxy.cfg: Read-only file system
docker run -it -d --cap-add=NET_ADMIN --name haproxy-keepalived --net=host --pid=host --privileged --userns=host -v /home/da/.haproxy-keepalived/haproxy/haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg:ro -v /home/da/.haproxy-keepalived/keepalived/keepalived.conf:/etc/keepalived/keepalived.conf:ro instantlinux/haproxy-keepalived:latest
@instantlinux Finally got somewhere with this. Using --pid=host I was able to get track_process to work; however, I am still unable to get the image to allow me to use my own /usr/local/etc/haproxy/haproxy.cfg file without conflicting with the frontend stats or complaining about the error below. It seems as if line 10 on the entrypoint.sh is triggered even though the script should create if the file does not exist.
For now, I have no choice but to use the frontend stats from the entrypoint.sh script by mounting my haproxy.cfg file to haproxy.d instead. If you can help me get around that it would be great. Also, can you make the frontend stats user a variable as well. Everybody uses haproxy as the user. It could be the default and if someone wants to use something else they can set it 😀
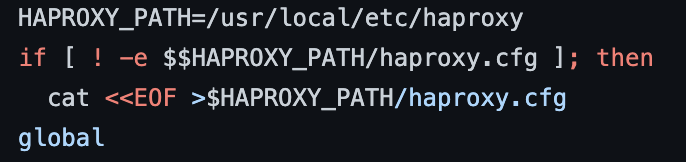
The issue lies on line 9 actually. Two $$ if [ ! -e $$HAPROXY_PATH/haproxy.cfg ]; then
Thanks so much for finding the offending $! Fixed that, and added your comments about --pid=host to the README. Pull the image and see if you can now run it the way you wanted.
I just did and it returned the same error. When I looked at the repo I saw the issue remains
/usr/local/bin/entrypoint.sh: line 10: can't create /usr/local/etc/haproxy/haproxy.cfg: Read-only file system
Sorry, looks like I missed saving out that file -- watch this pipeline run and its sub-jobs, once it finishes you can re-try.
No worries. Haproxy no longer errors out and works fine. But now keepalived does not start.
I experienced the same exact behavior earlier when I modified the script locally and mounted the edited copy in my dockder-compose using entrypoint: /usr/local/bin/entrypoint.sh
Have I addressed your issues fully? Let me know if there's anything else that will improve this image.
Please see my response above to your last message. After you updated the script and published the new image, I can override /usr/local/etc/haproxy/haproxy.cfg and it works. Haproxy starts without any errors. So this particular issue is now resolved. However, another one arised. When I override the haproxy.cfg keeaplived service no longer starts. But if map to /usr/local/etc/haproxy.d, it works.
/usr/local/etc/haproxy/haproxy.cfg -> Haproxy works. Keepalived service does not start.
/usr/local/etc/haproxy.d -> Both haproxy and keepalived service starts. But I can't I must use the frontend statscreated by the entrypoint.sh script
I can't reproduce that issue. Here's what I did; please show me where your setup differs: docker-compose.yml
version: "3.1"
services:
app:
image: ${REGISTRY_URI:-instantlinux}/haproxy-keepalived:2.6.4-alpine-2.2.7-r1
# restart: always
environment:
KEEPALIVE_CONFIG_ID: ${KEEPALIVED_CONFIG_ID:-main}
TZ: ${TZ:-UTC}
volumes:
# - ${ADMIN_PATH:-/opt}/haproxy/etc:/usr/local/etc/haproxy.d:ro
# - ${ADMIN_PATH:-/opt}/keepalived/etc/keepalived.conf:/etc/keepalived/keepalived.conf:ro
- /var/tmp/haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg:ro
- /var/tmp/keepalived.conf:/etc/keepalived/keepalived.conf:ro
ports:
- ${PORT_HAPROXY_STATS:-8080}:8080
secrets:
- haproxy-stats-password
network_mode: host
# Uncomment if you want to use vrrp_track_process
# pid: host
cap_add:
- NET_ADMIN
secrets:
haproxy-stats-password:
file: /var/tmp/haproxy-stats-password
haproxy.cfg
defaults
mode http
timeout client 120s
timeout connect 5s
timeout server 10s
timeout http-request 120s
log global
frontend stats
bind *:9000
stats enable
stats uri /stats
stats refresh 10s
stats auth statsadmin:password
# stats socket /var/run/api.sock user haproxy group haproxy mode 660 level admin expose-fd listeners
# stats socket ipv4@*:9999 level admin expose-fd listeners
# log stdout format raw local0 notice emerg
frontend eth-mainnet
bind *:18545
mode http
default_backend eth-mainnet
timeout client 120s
timeout http-request 120s
backend eth-mainnet
option httpchk
balance roundrobin
mode http
timeout server 120s
server host1 192.168.2.210:8545 check
server host2 192.168.2.211:8545 check
keepalived.conf
global_defs {
enable_script_security
}
vrrp_script chk_docker {
interval 5
script "/usr/bin/killall -0 dockerd"
fall 2
rise 2
}
vrrp_instance VI_1 {
interface br0
@main priority 101
@^main priority 100
track_script {
chk_docker
}
unicast_peer {
@main 192.168.2.230
@host2 192.168.2.220
}
@main unicast_src_ip 192.168.2.220
@host2 unicast_src_ip 192.168.2.230
virtual_ipaddress {
192.168.2.200
}
virtual_router_id 51
}
Did you fail to attach a keepalived.conf? I made this one up from the example.
I just tested using the same exact config that you above and it worked. However docker-compse logs -f does not provide any output so I don't know what's going on. Also, port 8080 worked for the stats page but 18545 did not.
Since I needed to move to production with this. I ended up modifying the entrypoint.sh script to accept username as an environment variable. If you ever decided to do it on your image as well since it is such a simple task, definitely let me know when that is done.
if [ $STATS_ENABLE == yes ]; then
cat <<EOF >>$HAPROXY_PATH/haproxy.cfg
listen stats
bind *:$PORT_HAPROXY_STATS
mode http
stats enable
stats hide-version
stats auth $STATS_USER:$STATS_PASSWORD
stats realm HAProxy\ Statistics
stats uri $STATS_URI
EOF
fi
STATS_USER variable was added in commit 696b90de75270a8bf33751029d9db266f0ff9c87 on 2-Jan-2023.