Makara Version 0.4.0 upgrade resulted in most requests going to master
Today we tried upgrading Makara to 0.4.0. For some reason, in our case, it resulted in what appeared to be a lot more queries going to master than before. I am providing two graphs of particular interest:
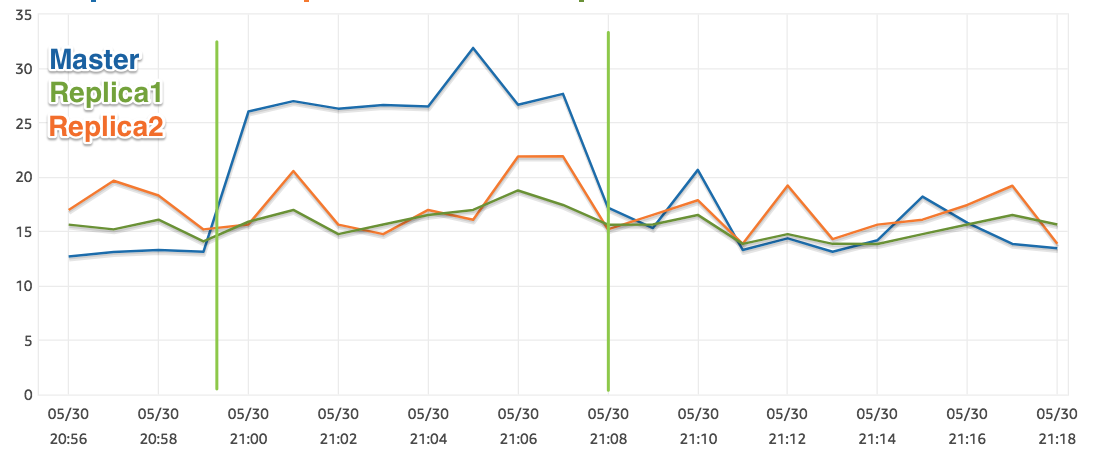
The first one is the CPU of the databases: one master and two replicas. Two vertical lines are deploys: first turning Makara 0.4.0 on, and then second one, reverting back to 0.3.10.
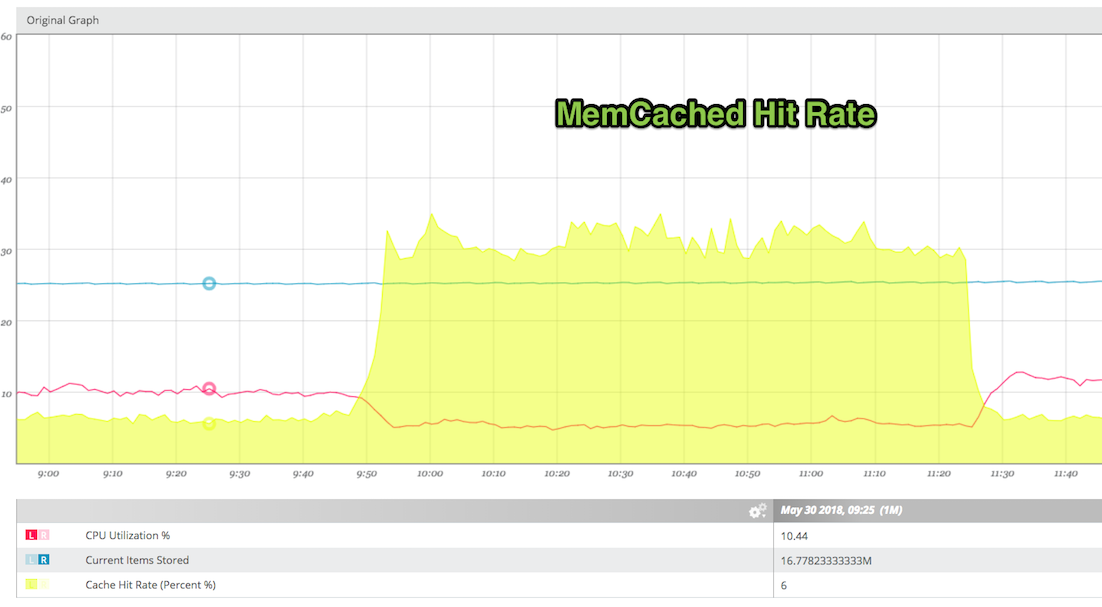
The second is the cache hit rate for our memcached server (which we use as a Rails cache, and would have been used for context storing with Makara < 0.4.0). You can see that once we switch, hit rate went up considerably, likely indicating that memcached is now only used for caching, not caching + makara context.
I looked through the code trying to understand how does Makara decide on whether to stick a connection, and found it to be a bit confusing. If I choose force_master! with sticky disabled, would it send the query to the master or not? See this issue #205 for additional context. In our case, however, stickiness was enabled. Here is the config file:
production:
adapter: postgresql_makara
encoding: utf8
host: localhost
username: XXXX
password: XXXX
reconnect: true
pool: 25
port: 5432
prepared_statements: false
makara:
blacklist_duration: 30
master_ttl: 5
master_strategy: round_robin
sticky: true
connection_error_matchers:
- !ruby/regexp '/pg::error: : select/'
- !ruby/regexp '/no more connections allowed/'
- !ruby/regexp '/result has been cleared/'
- !ruby/regexp '/no connection to the server/'
- !ruby/regexp '/the database system is (starting up|shutting down)/'
- !ruby/regexp '/reset has failed/'
- !ruby/regexp '/connection not open/i'
connections:
- name: master
role: master
database: master
- name: replica1
role: slave
database: replica1
weight: 1
- name: replica2
role: slave
database: replica2
weight: 1
So I wanted to document our case, because it nearly took our site down, as the master got quickly overloaded. Perhaps stickiness was broken in our case to begin with, and then perhaps it started working? Or, maybe we always run under an active record transaction within a request context? Not sure.
We can try again with a much shorter ttl, like 1 sec. I found this discussion in #162 relevant.
My thinking is that choosing to use stickiness or not, should probably be separate from whether or not it's possible to force master connection in a given context within the app. Perhaps I am missing something there.
Down the road I am thinking about adding a helper or two of this sort:
def try_master_if_blank(connection, &block)
yield(connection) || with_master(connection) { |connection| block.call(connection) }
end
I was thinking lately about this as well, but also because it'd be useful to have the opposite too. That is, a way of forcing some queries to go always to the secondary/replica, independently of the context. Perhaps something like:
proxy.on_master(sticky: false) do # sticky: true by default, if the config is set to stick
# Stuff that will always go to primary
end
proxy.on_slave do
# Stuff that will always go to read replicas
end
The one for the read replicas might be useful in cases you don't care about staleness and have to perform heavy load read queries that you don't want the primary to be busy with.
Intersecting idea, though makara always sends SELECT queries to replica unless it’s stuck to master.