influxdb
 influxdb copied to clipboard
influxdb copied to clipboard
Data not deleted by retenion policy in Influx2
I have a bucket with a retention policy of 7 days and a shard group duration of 1 day. I would expect that data is deleted after at most 8 days. But as you can see from the following output, they are persisted at least 10 days:
~ # influx query 'from(bucket: "bucky") |> range(start: 0) |> keep(columns: ["_time"]) |> first(column: "_time")'
Result: _result
Table: keys: []
_time:time
------------------------------
2022-11-14T00:00:00.000000000Z
~ # influx bucket ls
ID Name Retention Shard group duration Organization ID Schema Type
7e02f9ae1c13e893 _monitoring 168h0m0s 24h0m0s 8b488c9c54ae5e94 implicit
056cba28a1421ad1 _tasks 72h0m0s 24h0m0s 8b488c9c54ae5e94 implicit
3aa35dd885a61aa7 bucky 168h0m0s 24h0m0s 8b488c9c54ae5e94 implicit
~ # date
Thu Nov 24 08:55:01 UTC 2022
Environment info:
I use the the official docker image set to latest.
~ # influxd version
InfluxDB v2.5.1 (git: 5b6fdbf05d) build_date: 2022-11-02T18:06:28Z
~ # influx version
Influx CLI 2.5.0 (git: 3285a03) build_date: 2022-11-01T16:32:06Z
I know that there are a lot of reports on similar behavior but all that I found were with regard to v1.x and I couldn't apply any tips from there to my problem. If you can give me any pointers on how else to obtain helpful information, that would be great.
Hi, facing the same issue, I am on version 2.6. Deb package using Linux systems to deploy
same on debian and v2.6
retention was set to 60 days and was working fine, but now seems to be 6 months
the growth seems to coincide with v2.4 release date
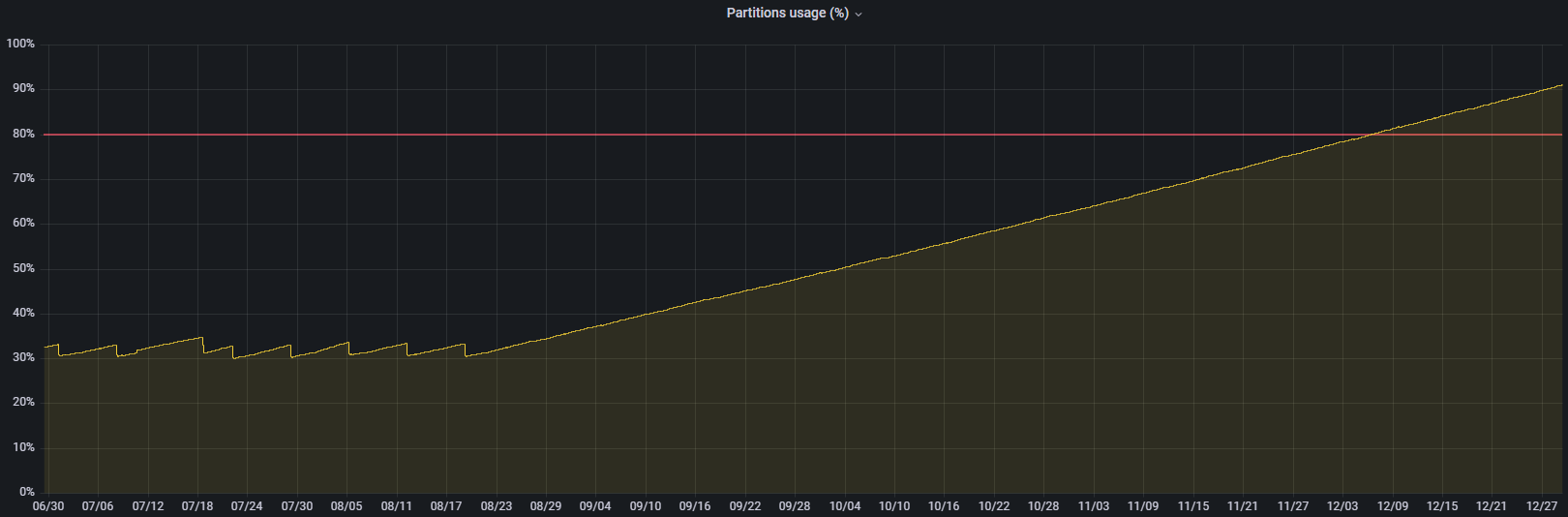 just downgraded to
just downgraded to v2.3, ~no drop in usage for now~ it's going down
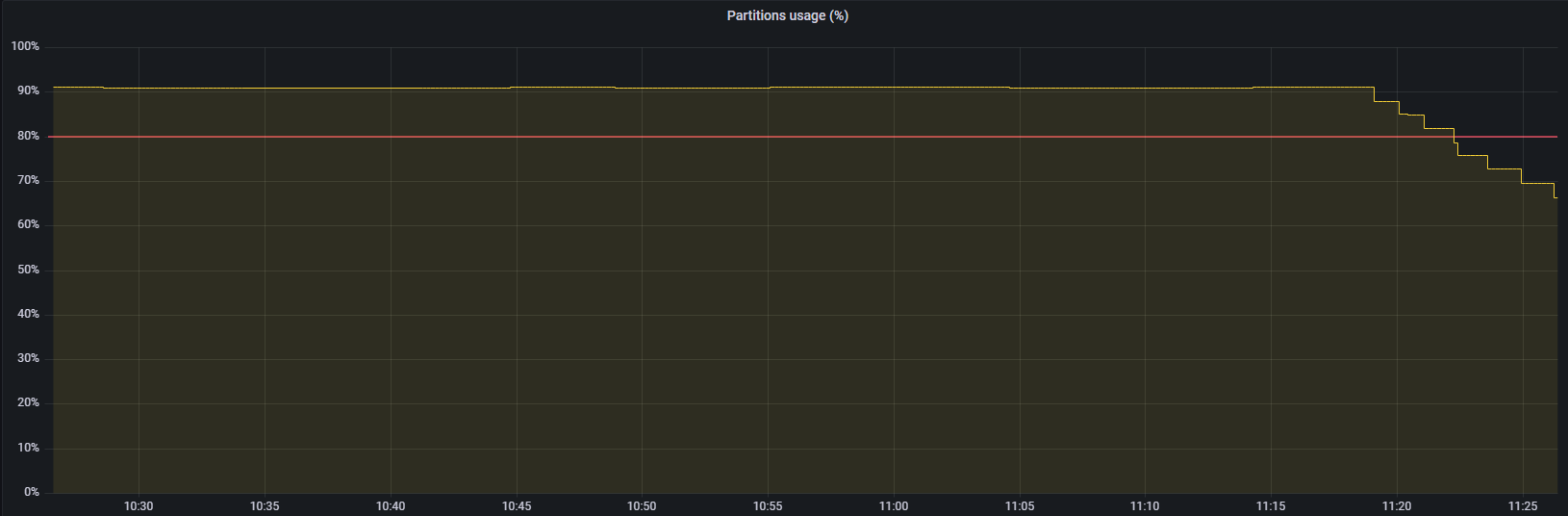
@Sergio-IME Just to clarify, you made no other changes to the instance other than downgrading to 2.3 and you saw retention begin to succeed?
@jeffreyssmith2nd
the original install and config were done with v2.0 (or maybe v2.1), the further upgrades were done regularly without changes to the config
the downgrade was: v2.6 > v2.3 that does not work because of v2.6 metadata > back to v2.6 + influxd downgrade 2.3 > v2.3
I gave it like 5 minutes, nothing was being removed, I tried flipping bucket retention between 60 and 90 days (also infinity but it was still showing 60 and 90 days, I think I saw a ticket about that though), nothing happened for another ~15 minutes and then it started
And what does the Partition Usage(%) represent exactly in you graphs? Do you have any logs that you can share? The important parts of the log would match one of these patterns:
Failed to delete shard group
Failed to delete shard
Problem pruning shard groups
One or more errors occurred during shard deletion and will be retried on the next check
Deleted shard group
Deleted shard
Starting retention policy enforcement service
Retention policy deletion check
It's the partition where bolt-path and engine-path live and represent 95%+ of the occupied space.
I checked the logs, they go back to October 23rd 2022 (so after upgrading from v2.3 the first time unfortunately):
- the first matching patterns from your list are
Deleted shard groupandDeleted shard(right after), from Dec 29th (post downgrade tov2.3) - same with
Starting retention policy enforcement serviceandRetention policy deletion check (start/end)(the latter appears regularly between Dec 29th and now) - no other mention of
shardorpolicybetween Oct 23rd and Dec 29th (other than multiples lines withts=2022-10-23T23:59:59.360368Z lvl=info msg="Reindexing TSM data" log_id=0blCYZP0000 service=storage-engine engine=tsm1 db_shard_id=xxxand on Dec 29th onlyOpened shard)
So your first 2 bullets indicate the retention policy is running healthily (which is no big surprise given that you're seeing the usage match that).
It's odd that you didn't even see the retention policy start/end messages before Dec 29th, that would imply retention wasn't even running at all. That shouldn't ever happen, it is enabled by default with a 30 minute interval and can be set in the config but must be a positive value.
Are you able to upgrade to 2.6.1 again and see if it still exhibits the issue?
Just noting: I restarted and updated the docker container in the meantime and it seems like the issue is gone with version 2.6.1 for me. Sadly I don't have any logs from the time when I had the problems anymore.
Interesting, I wonder if @Sergio-IME's was resolved too by the restart rather than by the downgrade to 2.3. That would imply that the retention service is getting blocked somewhere, my assumption would be in walking the filesystem to delete shards.
I also tried restarting prior to downgrading, but since it takes a while to start deleting shards, maybe I didn't give it enough time...
For now I upgraded back to 2.6.1 as per your suggestion, under 2.3 daily shard delete took place at night around same time, so we'll see tomorrow how that goes.
And speaking of restarting, does it not need restarting after upgrading? There was nothing about that in the logs until I manually restarted the service
looks like deletion still takes place after upgrading 2.3 to 2.6.1
...
ts=2023-01-11T00:14:21.006813Z lvl=info msg="Deleted shard group" service=retention op_name=retention_delete_check
...
That's good to hear, I was concerned why it would work on 2.3 and not 2.6.1 when we haven't touched that code in awhile.
I'm going to leave this issue open in case further issues are encountered with the current recommendation being to restart influxdb if this issue appears. I'm also going to look and see where we can add more logging to be able to diagnose it better in the future.
Thanks to @Sergio-IME and @NicholasTNG for the reports/help on this.
EDIT You can probably ignore the following, I just noticed that I had the retention period set incorrectly. I'll leave it here because I find the question I posed interesting in general.
I have run into the problem again. The logs show me that the deletion actually happens (see below), but there are still entries older than the retention period. Interestingly my oldest datapoints are 9 days old (the retention period is 7 days). I have a recurring check (via a systemd timer, so externally) that looks if there are datapoints older than 9 days (retention period + shard group duration + a bit buffer). Can these queries somehow inhibit the deletion? This check is there since we had issues with deletion not being carried out. It is linked to some other checks and hence carried out pretty frequently (every 10 minutes).
Current Infos: Influx in via docker influxdb:latest, info on image:
"Created": "2023-01-11T17:51:34.167405605Z",
"GOSU_VER=1.12",
"INFLUXDB_VERSION=2.6.1",
"INFLUX_CLI_VERSION=2.6.1",
A part of the logs:
ts=2023-01-18T15:51:48.135181Z lvl=info msg="Retention policy deletion check (start)" log_id=0fTNOrSW000 service=retention op_name=retention_delete_check op_event=start
ts=2023-01-18T15:51:48.136197Z lvl=info msg="Deleted shard group" log_id=0fTNOrSW000 service=retention op_name=retention_delete_check db_instance=3aa35dd885a61aa7 db_shard_group=174 db_rp=autogen
ts=2023-01-18T15:51:48.136728Z lvl=info msg="Deleted shard group" log_id=0fTNOrSW000 service=retention op_name=retention_delete_check db_instance=3aa35dd885a61aa7 db_shard_group=177 db_rp=autogen
ts=2023-01-18T15:51:48.137268Z lvl=info msg="Deleted shard group" log_id=0fTNOrSW000 service=retention op_name=retention_delete_check db_instance=3aa35dd885a61aa7 db_shard_group=180 db_rp=autogen
ts=2023-01-18T15:51:48.137762Z lvl=info msg="Deleted shard group" log_id=0fTNOrSW000 service=retention op_name=retention_delete_check db_instance=3aa35dd885a61aa7 db_shard_group=183 db_rp=autogen
ts=2023-01-18T15:51:48.138486Z lvl=info msg="Cannot retrieve measurement cardinality" log_id=0fTNOrSW000 service=storage-engine service=store db_instance=3aa35dd885a61aa7 error="engine is closed"
ts=2023-01-18T15:51:48.140400Z lvl=info msg="Deleted shard" log_id=0fTNOrSW000 service=retention op_name=retention_delete_check db_instance=3aa35dd885a61aa7 db_shard_id=174 db_rp=autogen
ts=2023-01-18T15:51:48.142354Z lvl=info msg="Deleted shard" log_id=0fTNOrSW000 service=retention op_name=retention_delete_check db_instance=3aa35dd885a61aa7 db_shard_id=183 db_rp=autogen
ts=2023-01-18T15:51:48.144240Z lvl=info msg="Deleted shard" log_id=0fTNOrSW000 service=retention op_name=retention_delete_check db_instance=3aa35dd885a61aa7 db_shard_id=177 db_rp=autogen
ts=2023-01-18T15:51:48.145759Z lvl=info msg="Deleted shard" log_id=0fTNOrSW000 service=retention op_name=retention_delete_check db_instance=3aa35dd885a61aa7 db_shard_id=180 db_rp=autogen
ts=2023-01-18T15:51:48.145847Z lvl=info msg="Retention policy deletion check (end)" log_id=0fTNOrSW000 service=retention op_name=retention_delete_check op_event=end op_elapsed=10.690ms
I would not expect queries to cause data to be held onto for a significant length of time past scheduled deletion.
We do grab a lock on the Shard that is set to be deleted. So if you had very long running queries that were constantly stacking up against that shard and winning the lock contention race, then it's possible but unlikely.
I can now confirm, that the retention policy works as expected when I don't fail at configuring.
Influxdb 2.6.1, retention 1 day
"Retention policy deletion check (start)" and "Retention policy deletion check (end)" are appeared in the log every 30 minutes at the begining. But after 2 or 3 days, They are never appeared again. The last "Retention policy deletion check (start)" in the log is without following "Deleted shard" and "Retention policy deletion check (end)" .
ts=2023-03-22T05:17:42.853558Z lvl=info msg="Retention policy deletion check (start)" log_id=0ggTwD2G000 service=retention op_name=retention_delete_check op_event=start
ts=2023-03-22T05:17:42.982092Z lvl=info msg="Deleted shard group" log_id=0ggTwD2G000 service=retention op_name=retention_delete_check db_instance=22626916da9871ce db_shard_group=3145 db_rp=autogen
ts=2023-03-22T06:00:00.923236Z lvl=info msg="index opened with 8 partitions" log_id=0ggTwD2G000 service=storage-engine index=tsi
ts=2023-03-22T06:00:00.923561Z lvl=info msg="loading changes (start)" log_id=0ggTwD2G000 service=storage-engine engine=tsm1 op_name="field indices" op_event=start
ts=2023-03-22T06:00:00.923609Z lvl=info msg="loading changes (end)" log_id=0ggTwD2G000 service=storage-engine engine=tsm1 op_name="field indices" op_event=end op_elapsed=0.064ms
ts=2023-03-22T06:00:00.923938Z lvl=info msg="Reindexing TSM data" log_id=0ggTwD2G000 service=storage-engine engine=tsm1 db_shard_id=3172
ts=2023-03-22T06:00:00.923952Z lvl=info msg="Reindexing WAL data" log_id=0ggTwD2G000 service=storage-engine engine=tsm1 db_shard_id=3172
ts=2023-03-22T06:00:01.084323Z lvl=info msg="TSI log compaction (start)" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=6 op_name=tsi1_compact_log_file tsi1_log_file_id=1 op_event=start
ts=2023-03-22T06:00:01.084459Z lvl=info msg="TSI log compaction (start)" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=4 op_name=tsi1_compact_log_file tsi1_log_file_id=1 op_event=start
ts=2023-03-22T06:00:01.084517Z lvl=info msg="TSI log compaction (start)" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=5 op_name=tsi1_compact_log_file tsi1_log_file_id=1 op_event=start
ts=2023-03-22T06:00:01.084635Z lvl=info msg="TSI log compaction (start)" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=8 op_name=tsi1_compact_log_file tsi1_log_file_id=1 op_event=start
ts=2023-03-22T06:00:01.084323Z lvl=info msg="TSI log compaction (start)" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=2 op_name=tsi1_compact_log_file tsi1_log_file_id=1 op_event=start
ts=2023-03-22T06:00:01.084901Z lvl=info msg="TSI log compaction (start)" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=7 op_name=tsi1_compact_log_file tsi1_log_file_id=1 op_event=start
ts=2023-03-22T06:00:01.084323Z lvl=info msg="TSI log compaction (start)" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=1 op_name=tsi1_compact_log_file tsi1_log_file_id=1 op_event=start
ts=2023-03-22T06:00:01.085613Z lvl=info msg="TSI log compaction (start)" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=3 op_name=tsi1_compact_log_file tsi1_log_file_id=1 op_event=start
ts=2023-03-22T06:00:01.229628Z lvl=info msg="saving field index changes (start)" log_id=0ggTwD2G000 service=storage-engine engine=tsm1 op_name=MeasurementFieldSet op_event=start
ts=2023-03-22T06:00:01.385201Z lvl=info msg="saving field index changes (end)" log_id=0ggTwD2G000 service=storage-engine engine=tsm1 op_name=MeasurementFieldSet op_event=end op_elapsed=155.586ms
ts=2023-03-22T06:00:01.385282Z lvl=info msg="Log file compacted" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=1 op_name=tsi1_compact_log_file tsi1_log_file_id=1 elapsed=300ms bytes=3702 kb_per_sec=12
ts=2023-03-22T06:00:01.385288Z lvl=info msg="Log file compacted" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=2 op_name=tsi1_compact_log_file tsi1_log_file_id=1 elapsed=300ms bytes=3010 kb_per_sec=9
ts=2023-03-22T06:00:01.385348Z lvl=info msg="TSI log compaction (end)" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=1 op_name=tsi1_compact_log_file tsi1_log_file_id=1 op_event=end op_elapsed=301.048ms
ts=2023-03-22T06:00:01.385283Z lvl=info msg="Log file compacted" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=7 op_name=tsi1_compact_log_file tsi1_log_file_id=1 elapsed=300ms bytes=3402 kb_per_sec=11
ts=2023-03-22T06:00:01.385356Z lvl=info msg="TSI log compaction (end)" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=2 op_name=tsi1_compact_log_file tsi1_log_file_id=1 op_event=end op_elapsed=301.053ms
ts=2023-03-22T06:00:01.385351Z lvl=info msg="Log file compacted" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=5 op_name=tsi1_compact_log_file tsi1_log_file_id=1 elapsed=300ms bytes=3242 kb_per_sec=10
ts=2023-03-22T06:00:01.385355Z lvl=info msg="Log file compacted" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=4 op_name=tsi1_compact_log_file tsi1_log_file_id=1 elapsed=300ms bytes=3565 kb_per_sec=11
ts=2023-03-22T06:00:01.385404Z lvl=info msg="TSI log compaction (end)" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=7 op_name=tsi1_compact_log_file tsi1_log_file_id=1 op_event=end op_elapsed=300.512ms
ts=2023-03-22T06:00:01.385407Z lvl=info msg="TSI log compaction (end)" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=5 op_name=tsi1_compact_log_file tsi1_log_file_id=1 op_event=end op_elapsed=300.893ms
ts=2023-03-22T06:00:01.385407Z lvl=info msg="TSI log compaction (end)" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=4 op_name=tsi1_compact_log_file tsi1_log_file_id=1 op_event=end op_elapsed=300.972ms
ts=2023-03-22T06:00:01.385440Z lvl=info msg="Log file compacted" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=8 op_name=tsi1_compact_log_file tsi1_log_file_id=1 elapsed=300ms bytes=3624 kb_per_sec=11
ts=2023-03-22T06:00:01.385298Z lvl=info msg="Log file compacted" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=6 op_name=tsi1_compact_log_file tsi1_log_file_id=1 elapsed=300ms bytes=3132 kb_per_sec=10
ts=2023-03-22T06:00:01.385472Z lvl=info msg="TSI log compaction (end)" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=8 op_name=tsi1_compact_log_file tsi1_log_file_id=1 op_event=end op_elapsed=300.859ms
ts=2023-03-22T06:00:01.385495Z lvl=info msg="TSI log compaction (end)" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=6 op_name=tsi1_compact_log_file tsi1_log_file_id=1 op_event=end op_elapsed=301.195ms
ts=2023-03-22T06:00:01.385528Z lvl=info msg="Log file compacted" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=3 op_name=tsi1_compact_log_file tsi1_log_file_id=1 elapsed=299ms bytes=3780 kb_per_sec=12
ts=2023-03-22T06:00:01.385558Z lvl=info msg="TSI log compaction (end)" log_id=0ggTwD2G000 service=storage-engine index=tsi tsi1_partition=3 op_name=tsi1_compact_log_file tsi1_log_file_id=1 op_event=end op_elapsed=299.953ms
ts=2023-03-22T06:10:02.241649Z lvl=info msg="Cache snapshot (start)" log_id=0ggTwD2G000 service=storage-engine engine=tsm1 op_name=tsm1_cache_snapshot op_event=start
ts=2023-03-22T06:10:02.778913Z lvl=info msg="Snapshot for path written" log_id=0ggTwD2G000 service=storage-engine engine=tsm1 op_name=tsm1_cache_snapshot path=/var/lib/influxdb2/engine/data/22626916da9871ce/autogen/3171 duration=537.219ms
ts=2023-03-22T06:10:02.778963Z lvl=info msg="Cache snapshot (end)" log_id=0ggTwD2G000 service=storage-engine engine=tsm1 op_name=tsm1_cache_snapshot op_event=end op_elapsed=537.352ms
ts=2023-03-22T07:00:02.232052Z lvl=info msg="index opened with 8 partitions" log_id=0ggTwD2G000 service=storage-engine index=tsi
ts=2023-03-22T07:00:02.232471Z lvl=info msg="loading changes (start)" log_id=0ggTwD2G000 service=storage-engine engine=tsm1 op_name="field indices" op_event=start
ts=2023-03-22T07:00:02.232516Z lvl=info msg="loading changes (end)" log_id=0ggTwD2G000 service=storage-engine engine=tsm1 op_name="field indices" op_event=end op_elapsed=0.048ms
ts=2023-03-22T07:00:02.233179Z lvl=info msg="Reindexing TSM data" log_id=0ggTwD2G000 service=storage-engine engine=tsm1 db_shard_id=3173
ts=2023-03-22T07:00:02.233196Z lvl=info msg="Reindexing WAL data" log_id=0ggTwD2G000 service=storage-engine engine=tsm1 db_shard_id=3173
I experienced this issue a week or two back running 2.7.4. A bucket with 6h retention and the default shard group duration of 1h filled up my disk over the course of a couple of days. When I searched the logs, I had pairs of op_name=retention_delete_check op_event=start and op_name=retention_delete_check op_event=end every thirty minutes until I reached a point where there was one last op_name=retention_delete_check op_event=start with no corresponding end. After that, I never saw another delete check until I restarted Influx, at which point the deletion policy kicked back in and cleared out the old shards.
We have found and fixed a bug in the retention service which could under rare circumstances cause the retention service to hang.
This fix will be available in the next release, v2.7.7, which is imminent.