flux
 flux copied to clipboard
flux copied to clipboard
newWindowGroupKey produces a lot of memory allocations
The newWindowGroupKey method inside of the window() transformation produces a lot of memory allocations when there are a lot of groups. This is because it will end up producing N*M group keys with M being the interval and N being the number of tables that it is processing.
In addition, these allocations are untracked which can cause an OOM when not enough memory is present on the system.
This issue is about optimizing newWindowGroupKey so it uses fewer allocations. One potential method might be to refactor group key so it is more friendly to memory allocations as proposed in #1032.
Alternatively, we can find a way to track group key creation in the memory allocator. Or we can do both. These two may be compatible since tracking memory allocations probably involves converting group key to use arrow buffers in some manner and the current interface wouldn't be friendly to doing that either.
Another way that this can be fixed, as I found out recently, is to optimize window() a bit. The window() transformation will recompute the group key for each new point it looks at. It is likely possible to optimize this so it only generates the group key once as long as it is changed to read the data with the time already sorted. This should be a pretty simple check and is also something that could get set by the planner.
We're also seeing poor performances with Flux when using aggregateWindow: the Flux version is about 30 times slower than the equivalent InfluxQL query with GROUP BY(time) (InfluxDB 1.8.2): 17s for Flux vs 0.5s for InfluxQL.
Is there a timeframe for a fix? We're very happy with Influx 1.8, but we'd like to use Flux :)
Some Examples that i believe show this issue affecting us on v1.8.3:
Flux - 43s:


InfluxQL: ~1.5s
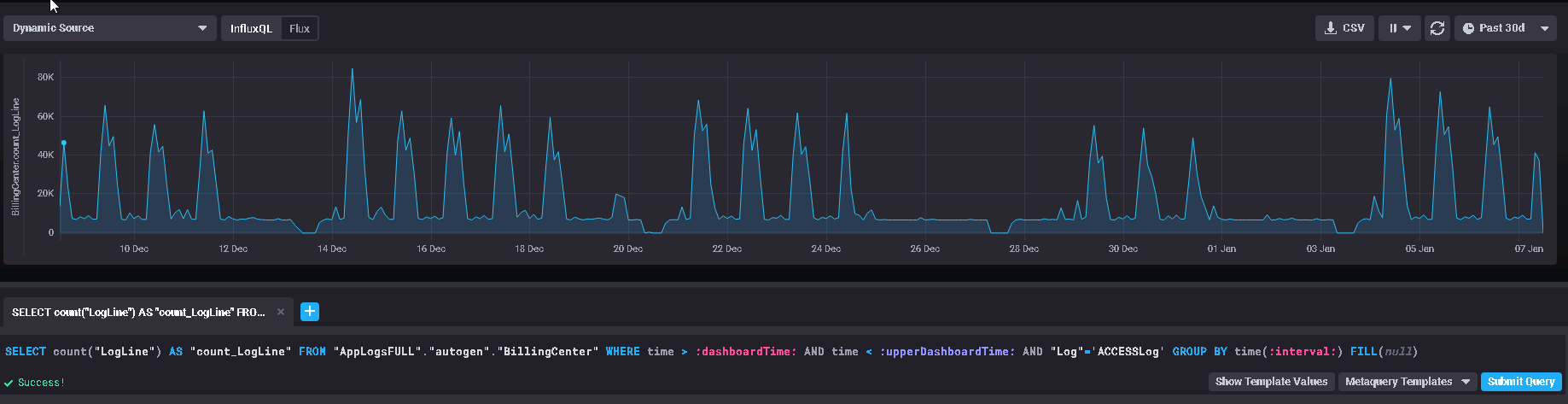
Just to eliminate the count() component the same query but without the interval, just returning the total: ~3s
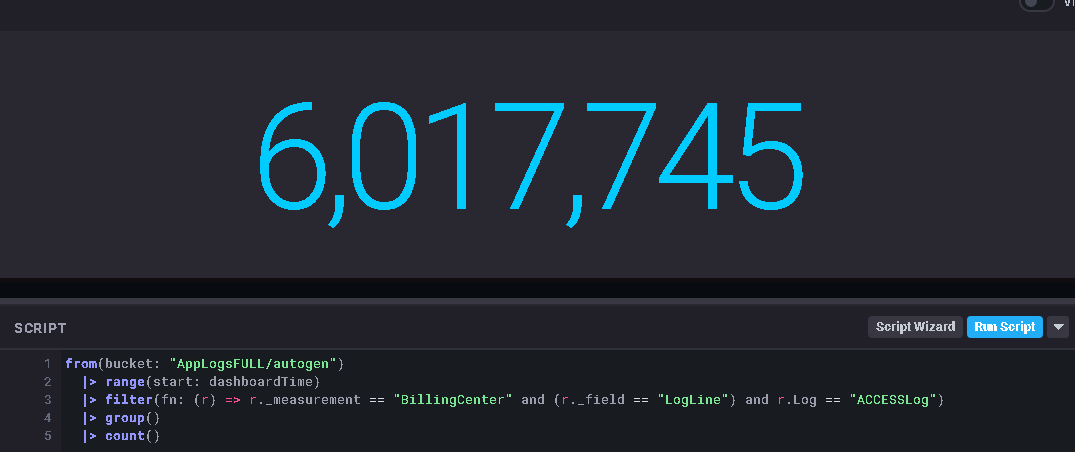
I'd like to make use of the advanced capabilities of Flux but any type of query that i want to window over time i take a massive performance hit on.
Hello,
I have been testing out using flux for a project of mine but seam to be running into this issue. Any aggregated queries (min, max, sum, count, etc.) take forever compared to InfluxQL.
Wondering if there is a timeline for a fix for this? Really excited to use flux's advanced capabilities but it's not worth it if it's performing so slowly.
Thanks
@webstersteele sorry for the late response on this. I often miss github notifications and just saw this comment. We're currently experimenting with improving this in this PR. There are also push down optimizations depending on the query that will push down the windowed aggregation which avoids this section of code. Those push downs primarily exist on the cloud version of the InfluxData product but we're actively working on bringing those to the open source versions and backporting them to the 1.x version.
@jsternberg Hi, have there been any development/progress in this area for the OSS version ?
Still having massive performance issues on 2022. Not happening with Influx 1.8. Looking for alternatives right now.