ragflow

ragflow copied to clipboard
Published
3 days ago
•
 infiniflow
infiniflow
[Feature Request]: URL support: Capable of web crawling and the corresponding content extraction.
Is there an existing issue for the same feature request?
- [X] I have checked the existing issues.
Is your feature request related to a problem?
No response
Describe the feature you'd like
This feature should be capable of navigating through specified URLs to collect and parse data, allowing for the extraction of specific content based on user-defined criteria. Ideally, it would support a variety of content types, including text, images, and tables, and allow for easy manipulation and storage of the extracted data.
Describe implementation you've considered
Reference: QAnything
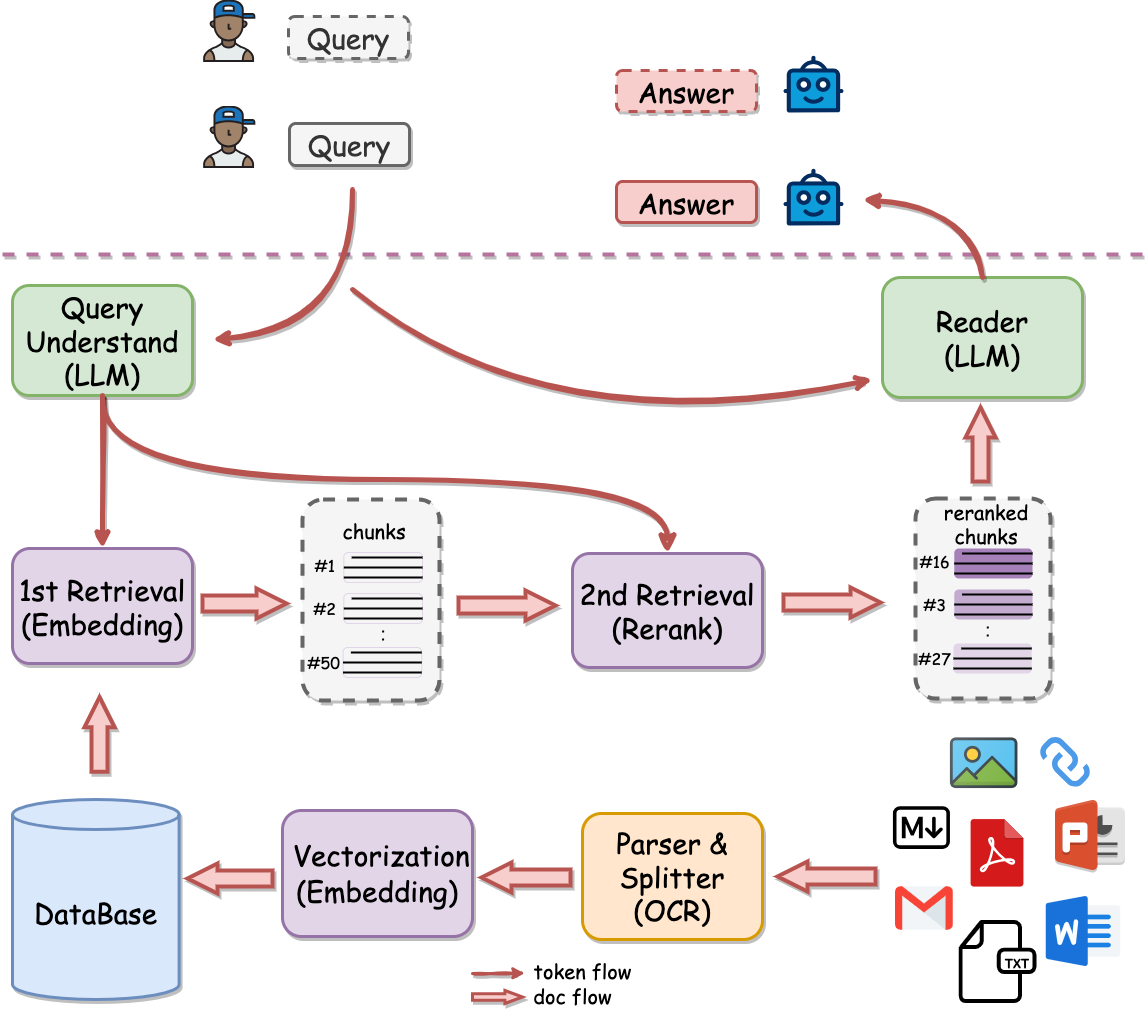
-
Task Management
- Deploy a task manager to handle the distribution of crawling jobs.
- Ensure tasks are evenly distributed across available resources to prevent bottlenecks.
- Use a robust queue system to prioritize tasks, manage retries, and monitor the crawling process.
-
Content Extraction with Playwright-Python and OCR
- Employ Playwright for Python to automate and control browser environments for scraping dynamic web pages that rely on JavaScript.
- Integrate OCR technology to recognize and extract text from images and other irregular content types that cannot be easily selected.
-
Page Classification
- Analyze the structure of the data stored and classify pages accordingly.
- Use machine learning or heuristic methods to categorize pages for targeted data extraction.
Documentation, adoption, use case
No response
Additional information
BCEmbedding: Bilingual and Crosslingual Embedding for RAG