spacy-graphql
 spacy-graphql copied to clipboard
spacy-graphql copied to clipboard
🤹♀️ Query spaCy's linguistic annotations using GraphQL
spacy-graphql
A very simple and experimental app that lets you query spaCy's linguistic annotations using GraphQL. It's my first ever experiment with GraphQL, so it's probably not as elegant as it could be.
The API currently supports most token attributes, named entities, sentences and text categories (if available as doc.cats, i.e. if you added a text classifier to a model). The meta field will return the model meta data. Models are only loaded once and kept in memory.
It currently doesn't do anything particularly clever, so regardless of your query, the full model pipeline will always be applied, even if you only need the token texts. Similarly, if you only request entities, the document will still be tagged and parsed.
Installation & Usage
To try it out, clone this repo and install the dependencies. By default, the en_core_web_sm model will be preinstalled. Note that the API requires Python 3.5 or higher.
git clone https://github.com/ines/spacy-graphql
cd spacy-graphql
pip install -r requirements.txt
# optional: install more spaCy models
Executing the app.py will start the server:
python app.py
You can use the SPACY_HOST and SPACY_PORT environment variables to change the host and port. By default, the API is served on localhost:8080.
If you navigate to the URL in your browser, you can explore the API interactively using GraphiQL. It also shows the complete documentation for the available fields.
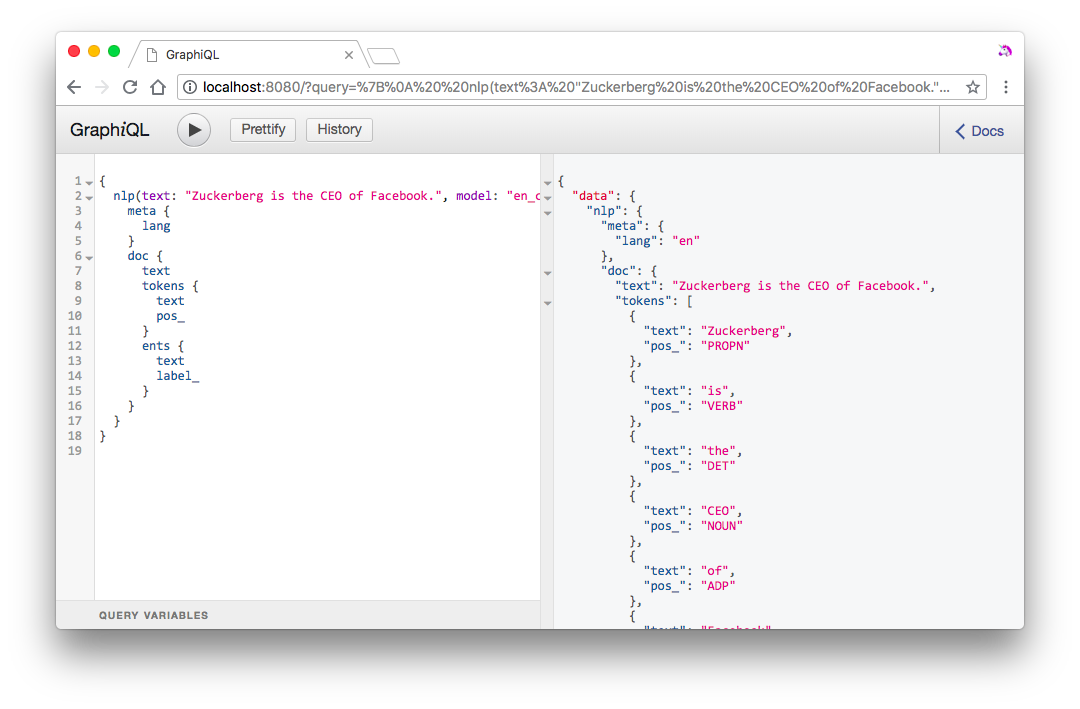
Example query
Both the text and model argument are required. The value of model is passed to spacy.load, so you'll be able to load any model that's installed in the same environment out-of-the-box.
{
nlp(text: "Zuckerberg is the CEO of Facebook.", model: "en_core_web_sm") {
meta {
lang
description
}
doc {
text
tokens {
text
pos_
}
ents {
text
label_
}
}
}
}
Example Response
{
"data": {
"nlp": {
"meta": {
"lang": "en",
"description": "English multi-task CNN trained on OntoNotes, with GloVe vectors trained on Common Crawl. Assigns word vectors, context-specific token vectors, POS tags, dependency parse and named entities."
},
"doc": {
"text": "Zuckerberg is the CEO of Facebook.",
"tokens": [
{
"text": "Zuckerberg",
"pos_": "PROPN"
},
{
"text": "is",
"pos_": "VERB"
},
{
"text": "the",
"pos_": "DET"
},
{
"text": "CEO",
"pos_": "NOUN"
},
{
"text": "of",
"pos_": "ADP"
},
{
"text": "Facebook",
"pos_": "PROPN"
},
{
"text": ".",
"pos_": "PUNCT"
}
],
"ents": [
{
"text": "Zuckerberg",
"label_": "PERSON"
},
{
"text": "Facebook",
"label_": "ORG"
}
]
}
}
}
}