alpaca-lora
 alpaca-lora copied to clipboard
alpaca-lora copied to clipboard
sharing experimental results like a chatbot
7B
demo link: https://notebooksd.jarvislabs.ai/tz0hyvPyQMO0qXbeTpLYv2Wu5-j9AfFm_dM9sQN5fqFGI0lT90sAIHgT-Gi0jLcX/

Compared with ChatGPT, the effect is still much worse. How can we narrow the gap with ChatGPT?
Compared with ChatGPT, the effect is still much worse. How can we narrow the gap with ChatGPT?
From the given examples, I wouldn't say it's much worse. It's just more direct and doesn't waste tokens, which is a good thing. With more complicated queries, it shits the bed and hallucinates, but then again, it's a 7B model. It's already very impressive.
For example, I want alpaca to be able to answer questions about a novel. How do I get alpaca to learn about the novel? Since the data I see tweaked so far is in prompt mode, can I only use data in prompt format for tweaking?

Nice! I'm finetuning 13b myself, but I've plateaued quite early.
 Did you experience the same behavior?
Did you experience the same behavior?
Yeah kind of
I will be more focusing on exploring how different combinations of hyper-params at generation time will effect the quality and speed!
Compared with ChatGPT, the effect is still much worse. How can we narrow the gap with ChatGPT?
From the given examples, I wouldn't say it's much worse. It's just more direct and doesn't waste tokens, which is a good thing. With more complicated queries, it shits the bed and hallucinates, but then again, it's a 7B model. It's already very impressive.
@HideLord @deep-diver There were a TON of hallucinations in the original Stanford dataset. I cleaned up hundreds of issues. Try re-training on the new cleaned dataset. If you get a chance, please post a 13b fine-tuned model. Some of us have SLOW GPU's.
Thanks @gururise
I am retraining with 13B and 30B at the same time. Will share if I find something useful
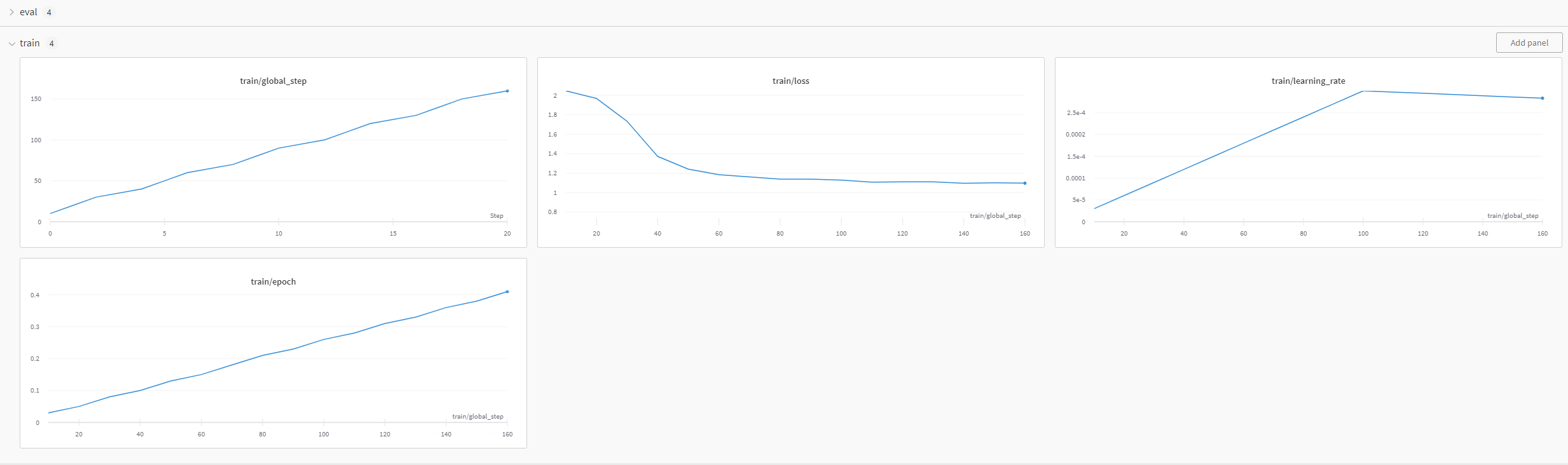
Unfortunately, the training crashed before it finished, but here are the logs:
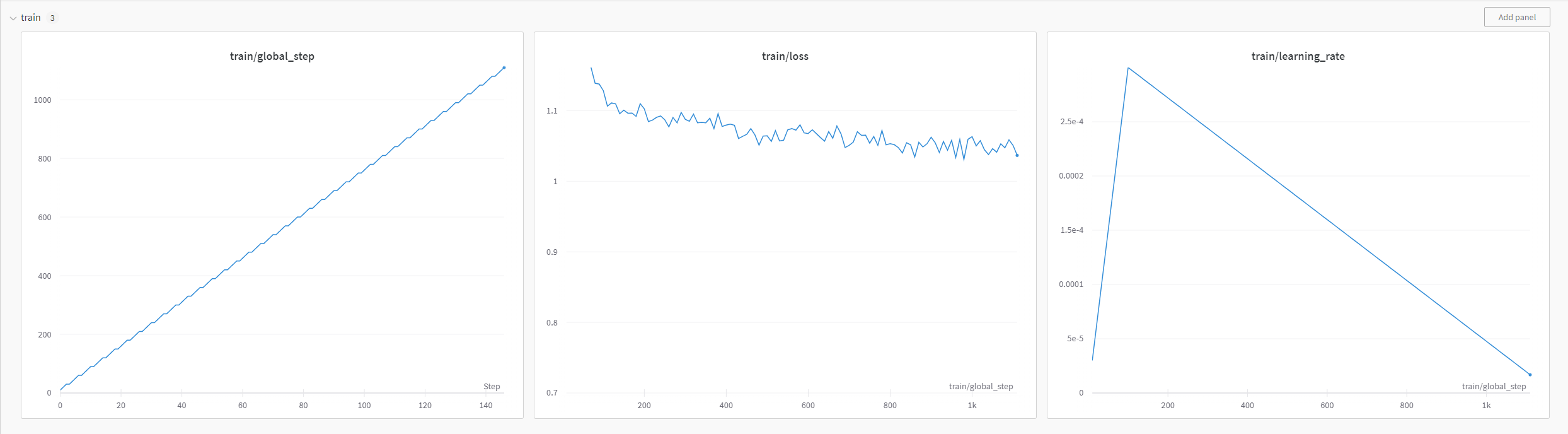 The data points were generated with a trimmed version:
The data points were generated with a trimmed version:
def generate_prompt(data_point):
instruction_field = data_point["instruction"]
input_field = data_point["input"]
output_field = data_point["output"]
if data_point["input"]:
return f"<<Instruction>>:\n{instruction_field}\n{input_field}\n<<Output>>:\n{output_field}"
else:
return f"<<Instruction>>:\n{instruction_field}\n<<Output>>:\n{output_field}"
Here is the final checkpoint if somebody is interested: https://huggingface.co/hidelord/llama-13b-lora/tree/main
"continue" works in 13B. That was something didn't work with 7B model in my case.
currently finetuning 13B model with Korean instruction datasets to see how well it works with different language, and 30B model with the original dataset.