neorv32
 neorv32 copied to clipboard
neorv32 copied to clipboard
Fixes concurrent ecall / IRQ issue.
Runs in simulation, still has to be tested on hardware. More commits might follow. This pull request is just to let you know and avoid that we are both doing the same work at the same time.
@GideonZ, I changed this PR to a draft, to prevent unwanted merges. Please, feel free to mark it as "Ready for review" as soon as you feel it to be good.
It may be superfluous; but this is my fix for the concurrent trap / irq issue. I tested this on the hw and the debugger works again; including single stepping.
I will be checking your fix as well; probably tomorrow.
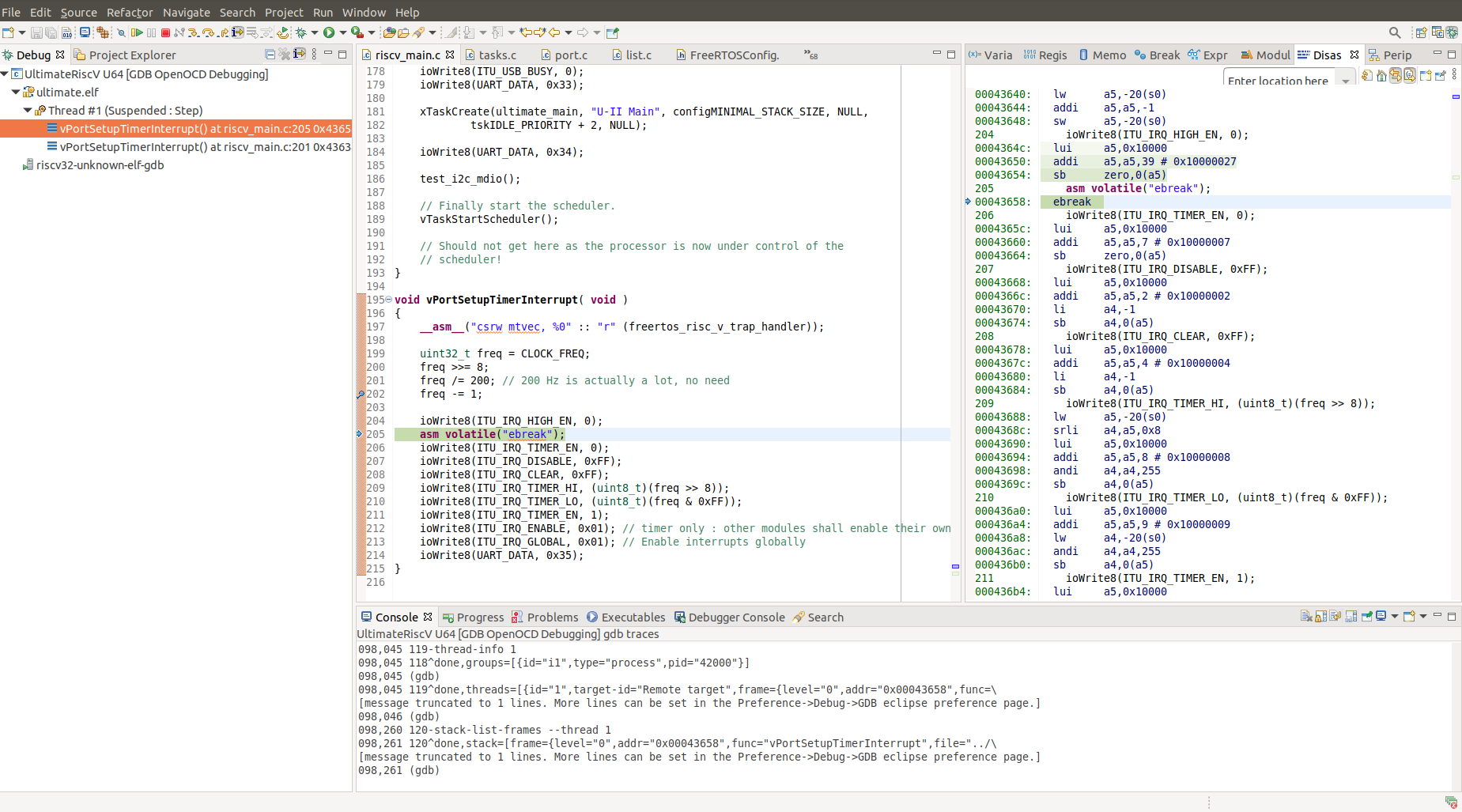
I have just tested your fix. Looks good so far, but there is a problem with the ebreak instruction. When running the processor_check program via GDB the program enters debug mode when the ebreak instruction is executed.
Program received signal SIGTRAP, Trace/breakpoint trap.
main () at main.c:643
643 asm volatile("EBREAK");
(gdb) s
[neorv32.cpu.0] Found 1 triggers
"stall", nothing happening
However, I cannot do a single step to step-over the ebreak instruction after that - the debugger just "hangs". I think it is waiting for the CPU to ack the resume bequest, but it seems like this never happens.
Interesting. I tried this, and you are right, you cannot step over the ebreak. I tried this in instruction stepping mode the debugger comes back on the same address every time and you can step as many times as you like, it doesn't hang per se. I see in SignalTap that it never leaves debug mode; PC stays in the FFFFF800 range, too.
How important is it to fix my fix, if your fix already works? This is beyond my skills to fix, I think, as I don't exactly know how the debugger works.
I think this is because of a false xepc (trap return address) assignment. The EBREAK-TRAP and the SINGLE-STEP-IRQ might arrive at the same time here, but EBREAK seems to be evaluated first.
How important is it to fix my fix, if your fix already works? This is beyond my skills to fix, I think, as I don't exactly know how the debugger works.
I have looked at your code again and there is one "thing" that hurts my eyes: :wink:
The signals trap_ctrl.cause and trap_ctrl.irq_start are written from two different if-blocks. Sure, this is fine as VHDL ensures the latter assignment gets priority, but this makes the code (at least for me 😅) hard to understand and hard to debug. Furthermore, this might have unintended side effects (on a "behavioral" level and also on resource utilization as we have an "implicit" mux here).
I did a quick synthesis using my default FPGA test setup:
:bug: main |
#326 | #327 | |
|---|---|---|---|
| Logic elements: | 6170 | 6152 | 6129 |
| Registers: | 3209 | 3210 | 3211 |
(Timing is not affected at all.)
I really appreciate your fix (:+1:), but I think we should focus on #327 (if that also works for you). What do you think?
I didn't mean to hurt your eyes. 😉 It is quite common in VHDL to start with default assignments and then overwrite stuff in 'if' statements. This is also the reason that I usually put the reset clause at the bottom of the process, not at the top. Because... if there is something you do not want to reset in the process (e.g. synchronization flops), the 'else' will cause the flipflops that are not reset to keep their previous value during reset. And, this causes more luts to be used, too. Anyway, this is "viel Getue um nichts".
And sure, let's drop #326 and go for #327. In every case I prefer a fix by the author over my own fix. I just had to find out if a fix for this problem also fixed the random crashes I was seeing, so I went ahead to make a temporary change. (And indeed; the random crashes are gone.) I'll try #327 tonight.
Message ID: @.***>
I didn't mean to hurt your eyes. 😉 It is quite common in VHDL to start with default assignments and then overwrite stuff in 'if' statements. This is also the reason that I usually put the reset clause at the bottom of the process, not at the top.
Don't get me wrong! I think this is just a matter of taste. :wink:
Anyway, this is "viel Getue um nichts".
😅
And sure, let's drop #326 and go for #327. In every case I prefer a fix by the author over my own fix. I just had to find out if a fix for this problem also fixed the random crashes I was seeing, so I went ahead to make a temporary change. (And indeed; the random crashes are gone.) I'll try #327 tonight.
I did some more testing and from my side everything looks good.
I think the bug has been resolved by #327. If you agree, we can close this, right?
I have to check it still, but I think so. I have been working on other things and didn't have much time to look into RiscV. Will try to look into it tonight or tomorrow morning.