speechbrain
 speechbrain copied to clipboard
speechbrain copied to clipboard
Speaker Indentification from Scratch
Hello people! First of all, congratulations for this wonderful work. I need your help, please.
Contextualizing here: I'm studying the speakerIDfromScratch script (research work). I'm working with audios of 15 seconds in duration (aprox.), railway environment, 48 speakers (number of classes), etc. I'm, also, using ECAPA_TDNN, custom_model.classifier (I tried to used: ECAPA_TDNN.Classifier, but it gave me an error), etc.
So I have the following questions:
- I thought of adding the following settings (add_rev; add_noise; add_rev_noise; etc.), would it be the correct way?
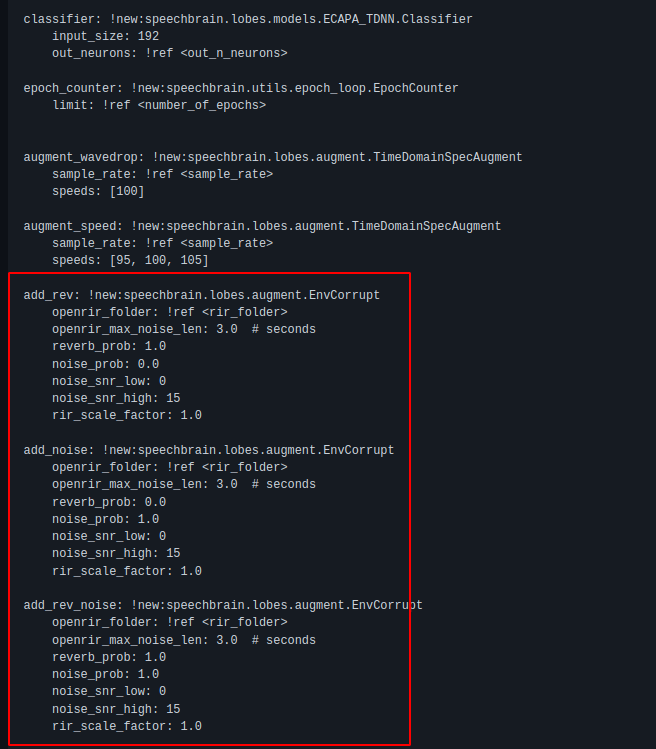
My current configuration is: train.yaml.
Nota: I'm wanting to add the maximum number of parameters settings, in such a way that I can get a "real" road environment. It is important to say that I am training with audios (48 speakers, approx. 800 audios in total) that were recorded in a noise-free environment. What other parameters can I modify or add in train.yaml?
- How can I make the inference, to be able to identify the speaker who is speaking? with "real" audio? in which the AUDIO has 4 or more parts and in which there are different speakers in these parts (usually there are two speakers).
Would I have to calculate the embeddings for each piece of audio?
Thank you very much!
Hi @EddyGiusepe hope you are doing well. There are a lot of questions ;-)
I thought of adding the following settings (add_rev; add_noise; add_rev_noise; etc.), would it be the correct way?
What is defined in the yaml files also needs to be picked up by your training recipe. Just declaring it in the yaml file might instantiate the objects add_ref, add_noise, and add_rev_noise - but that's not guaranteeing that they are used at all during training or in the way one intends for it. @mravanelli wrote a consistency testing PR, please take a look. It might help you in developing your recipe further. You'll see there in the noise corruptions for the VAD recipe, which are similar to yours, that we needed to take some definitions out of the yaml file since the training recipe did not pick up on them (the PR will be merged soon).
I'm wanting to add the maximum number of parameters settings, in such a way that I can get a "real" road environment.
I don't have expertise for that maybe - @pplantinga ?
How can I make the inference, to be able to identify the speaker who is speaking? with "real" audio? in which the AUDIO has 4 or more parts and in which there are different speakers in these parts (usually there are two speakers).
Sounds like a PR you could contribute ;-)
- What is a "part" for you?
- For multiple speakers in one audio, please look into "speaker diarization" - usually people fix the number of speakers, which is a way to adapt to their datasets - depends on the use case scenaria
- "Real audio" as in non-lab audio?
Would I have to calculate the embeddings for each piece of audio?
By rewriting your script in a way that does so. The questions you raise have been part of ongoing research discussions - there are some fully online research archives like this one - Interspeech proceedings are a good entry point for study.
@underdogliu what's your take?
Thank you very much @anautsch for starting this discussion, I hope to continue discussing with you and others researchers.
That's right, there are a lot of questions, sorry !!!
Then:
-
When you speak of "training recipe" you are referring to the "train.py" (meu train.py) file, right?
-
Thanks for these links (Thanks, also, @mravanelli): consistency testing PR and noise corruptions for the VAD recipe. I've already started reading these links and I'm looking at how I can use this for my task.
-
If I evolve, develop, in this challenge I would like to contribute (it's an honor).
-
"part" --> mean, that in each audio I always have excerpts (or I called: "parts") of speeches which correspond to different speakers (usually in these audios I have two speakers), did you understand?
I commented this because when I go to pass the audio to detect the speaker... I will pass a raw audio (that is, an audio where there will be two speakers, with noise, etc. Remembering here: I trained until only with audios where there is only one speaker with their respective identities, did you understand?
-
I thought about DIARIZATION, to separate the audio excerpts (or calculate the embeddings of each audio excerpt or excerpt that will contain only one speaker)... I'm still not quite sure how to do that :( .
-
Real áudio --> it is the same audio that is used in the work field (in the highway field). With noise, speakers speaking fast, slow, with echo ( reverberation), etc.
-
I will see and study, too, this link.
I'll be back soon with some improvements, etc.
Thank you very much!!
Hi @EddyGiusepe a pleasure, don't get too serious, the goal is: have fun, learn & make a difference.
Yes, train.py files are some sort of recipe, and we feature database recipes here: https://github.com/speechbrain/speechbrain/tree/develop/recipes
Mirco just merged the consistency testing, yesterday - so it's ready for use!
Do you know where these parts are upfront or do you need to figure them out while processing the audio? ;-) Diarization implies one needs to figure it out on the fly. Which is more difficult if one doesn't know how many speakers to detect. From my view, a research convenience choice is to restrict this to two speakers. Some databases go for 3 speakers - why not 12... or 7 - have some more thoughts here - but that's better for discussing in a call or so, once you got going! :grinning:
Yes, training with one speaker is fine, so long as one knows that. There is a difference between creating AI for data representation and creating AI for recognition based upon representations. Was about to send you on a journey for some ML books but that might not be practical here. We can discuss some philosophies if you are up for it - but let's stay on task here. Latent variables of N identities having each their predicitive posteriors would give some criterion - integrate out N, and you'll have more flexibility ... depends on what you want - and how fast.
I thought about DIARIZATION, to separate the audio excerpts [...]
Sounds like a good way! Is your goal to chop up the signal before to work on each audio segment then and try to cluster them? Or is your goal to create a model that pops out more directly what is more alike from what could be different?
same audio that is used in the work field (in the highway field)
Keep an eye on the lab datasets, nonetheless (to compare results). Do you have a database ready? Or is there a related publicly available dataset to your task? If you have an indoor task, providing a recipe could work through using a publicly available database and degrading its quality - SpeechBrain offers augmentation algorithms such as EnvCorrupt. Please take a look at related tutorials.
We need help on the speaker recognition part - community-driven tools evolve through mutual nourishment.
Thank you, @anautsch, yes yes ... I'm very happy to be learning this line of research.
Then:
-
With respect to those recipe files, it was clear yes. Thank you!
-
I know where these files are located for consistency. But unfortunately, I'm not able to run the consistency test (I'm working on Google Colab: consistency_test_file) ... could you give me a suggestion here?, please!
-
Yes. So, I'm training with 48 speakers, of each speaker I have 20 audios, each audio is 13 seconds aprox. (Also, I know their identities). You can send these books to me ... I will try to study in parallel. Thank you!
-
Good questions! ... I still have doubts about it. In principle I know that for a raw audio I should have the separate parts (or the embeddings) to later compare each "part" with the Database that I have already "trained" (maybe I can apply COSINE SIMILARITY ) . I need to study more about this part. For starters I'm focussing on this script. Since this script has an INFERENCE part ("Use the EncoderClassifier interface on your model"). In this part, also, is possible to calculate the EMBEDDINGS ... so I thought of comparing the embeddings of the new audios with my Database, already trained.
-
So, I have a Database yes. But they are very few (I will try to collect more Data). There is no Data related to my task (railway environment is very complex). Due to this difficulty (few Data, noisy environment, distorted speech, etc) I am trying use AUGMENTATION (I'm using the model pre-treined with VoxCeleb).
Aqui a minha configuração: train.yaml . If you can give me some suggestions, I would appreciate it!
** In that train.yaml file, I am still thinking how to use the ECAPA_TDNN classifier.
I'm making little progress little by little :)
Thank you very much!!!
@EddyGiusepe I do not have too many things to add since the reply from @anautsch has already been fruitful enough. I will leave the main conversation between you two but just reply one question.
How can I make the inference, to be able to identify the speaker who is speaking? with "real" audio? in which the AUDIO has 4 or more parts and in which there are different speakers in these parts (usually there are two speakers)._
There are numbers of ways to implement this. I am a long-time user and fan of Kaldi so I always utilise first a Kaldi-like data structure with wav.scp and utt2spk, then do the inference with my own in-house script (if you want and the team people are fine with it, I can share them later in some warehouse places in speechbrain). For the issue of different speakers, I think you already discussed with some diarization ideas with @anautsch.
Would I have to calculate the embeddings for each piece of audio?
By default yes, and the embeddings are extracted and buffered independently per-utterance (while for scoring they are unified as one, but that is another thing under discussion).
The consistency test is for you to check if everything is there in place - if it's way of use is not directly obvious, put your time elsewhere to be more effective (do what you like, you'll be good at it). Just make sure that everything that you want to use in the train file is also declared in the yaml file and vice versa.
Regarding books, look for Bishop, Duda & Murphy as lead authors on machine learning, pattern recognition and a probabilistic perspective. The books are tomes, more than a quick study ;-)
If there's not enough data to train a fully fledged AI, it's better to split all available data up per task. For example, how good is the noise simulation / reduction? Then a later question could be, how many different speakers are in one audio chunk? What are their identities? You might want to use pretrained models, and fine tune them. Then, validate your fine-tuning and run a larger test. Make sure, within a task, your data is not overlapping sets - if you fine-tune towards one speaker and make that one known to the model, of course the model will predict better for that one person - but are all people in your real-world setting known? How about other characteristics that could be linked to a specific task?
As you might guess already, different tasks might require different ways of how you need to handle your data to get to a robust solution. Please avoid sharing in-door data without going through appropriate disclosure procedures (speech data involves consent of the people who are recorded).
I hope that serves enough guidance to get ahead. I don't have access to your Google data. We can discuss some specific or general concerns but we do not have the resources available to work out each recipe (the heavy lifting rests with you). As @underdogliu mentioned, happy to discuss - also, we need to get the inner workings of this toolkit moving ahead.
What you are about to jump at, is a bigger task. It won't be completed within a week. It might very well lead to more than just having trained models and recipes ready (like a tutorial or blog of how to get there). This could be finished in one or two weeks, perhaps we are talking about months though. Are you on our slack?
I closed unintentionally :(
Hello @underdogliu!!! Quiet.
-
I would like to be able to discuss more how you make the inference. I will look for this author Kaldi to know more about this part. So, in this first part I'm using the SpeechBrain script to make some inferences. I'm still training the script with my Data. Obviously, this inference I make is only with an audio that has one speaker (I'm still studying how to make the inference for a real audio). I would like to discuss this part with you to see how you make this inference. Thank you!
-
Yes yes ... this issue of Embeddings is, also, on my mind.
Thank you so much, @underdogliu !
Hello @anautsch!
-
I will do this consistency test.
-
I'll look for those books yes, thank you!
-
I have little data. But, I'm already trying to get more Data for my training. I'm applying Augmentation and I'm also adding noise, velocity, revorbation, etc. I'm currently training the Network and my test_erro~5%, but when making the inference... the network makes a lot of mistakes. My train.yaml (I think there is another way to do these settings):
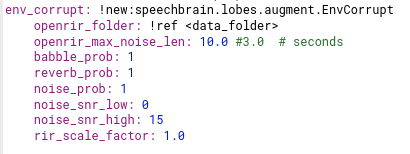
Yes, the numbers of speakers is two in each piece of áudio, I know the identities at the time of Training (each one has an ID) ... Yes, I thought of using a Pre-trained model. If you have a study link, please send it to me. I will be careful with the question of: "Data sharing".
-
Alright, let's go on this challenge.
-
Are you on our slack? --> No, not yet.
Thank you so much!
Make sure to use the env_corrupt in the train.py file. Check for a set of audios which are the noise effects you'd desire to have. Look at the training data of a pretrained model. Which data augmentation would be necessary to transform them into your environment? Maybe it is enough to retrain a pretrained model based on in-domain data augmentation. You won't need to corrupt audios that are already in-domain (unless to see if there's some performance gain because of a nature of the data your model is not encompassing by its design).