snabb
 snabb copied to clipboard
snabb copied to clipboard
Throughput slowly getting reduced when running for 17 hours continuously
Hello,
After running my app network for about 17 hours continuously I noticed that there is a significant decrease in the throughput as measured by wget. For example this is the results I am getting today:
2017-06-05 04:14:21 (857 Mb/s) - ‘/dev/null’ saved [1073741824/1073741824]
2017-06-05 21:37:41 (469 Mb/s) - ‘/dev/null’ saved [1073741824/1073741824]
I have been observing this for past couple of days and found that if I restart the snabb process, the throughput will jump back to the maximum.
To explore further, I plotted the breaths/s, pps from q0_rxpackets.counter of north and south interface and number of zero packets received in my various apps. The breaths/s and pps counters show marked decrease, while zero packets I received from north interface shows a continuous increase. The breaths/s and pps is computed by taking the difference in the breaths and q0_rxpackets.counter every second.




While there are zero bytes packets in other apps, they are less than 100 in number.
I am not able to see any unusual memory usage, while checking in top.
14801 root 20 0 135172 40956 6108 R 72.3 1.0 1:58.23 snabb
11219 root 20 0 134984 40464 6036 S 65.6 1.0 886:51.04 snabb
I am keeping this process running continuously and see where it goes.
After running about 36 hours, the graphs trends are the same. Throughput decreases steadily. Not sure what could be wrong here.
Great test case!
There is probably a simple explanation. This kind of test has been done successfully with a few existing Snabb applications in the past. Question is how to find that simple explanation :).
I have been thinking about how to apply the new logging on the diagnostics branch and the Studio analysis tools. I have an idea!
The Snabb process exposes a lot of diagnostic information in /var/run/snabb/$pid during execution. This is updated in realtime and includes the timeline log (for the past ~10 minutes), the VMProfile data, and the engine latency histogram data.
Today we already have some tools and methods for analyzing this data and comparing it between multiple process. This case is different though: we want to compare one process with itself at different points in time. So how to do that?
One approach would be to periodically capture the /var/run/snabb/$pid data and "pretend" that each snapshot is from a different process. So for example we could run tools like studio snabb vmprofile to see how the process is operating at 0h, 6h, and 12h, etc. Then we look for what is different between the processes.
How does that sound? If good then I reckon you could setup the logging something like the script below. This assumes the Snabb process has the lukego/diagnostics branch merged in. (That's not landed on master yet because it has some performance overhead that needs to be dealt with.)
while true; do
stamp=$(date +%Y-%m-%d_%H.%M)
sudo tar cf snabb-$stamp.tar /var/run/snabb
sudo xz -f -0 snabb-$stamp.tar
echo -n "Snapshot: "; ls -lh snabb-$stamp.tar.xz
sleep 1h
done
This should be a good opportunity to improve the existing Studio tools and possible even make some special extensions for comparing the same process at different points in time (e.g. making deltas of the vmprofile and latency data to isolate specific time periods.)
Edit: Script has sleep 1h to snapshot every hour now. Initially it had the short sleep 10 interval that I used for testing.
That sounds good. I will run this tonight and update tomorrow. Eventually, I think, some sort of time series db like rrd would be a nice addition to tackle the change in parameters across time.
To generate the graphs above, I had written a shell script to log the counters I am interested in to a text file along with time stamp and then used plotly to generate the graph.
I would also like to have some rrd-like functionality built into Snabb.
This should work very well for counters (core.counter module) since those mostly represent simple events that can be counted. Could also work for the latency histogram and VMProfile data too. Won't work for timelines though because those are really log files rather than counters.
Question is how much of this we should build into the Snabb dataplane (e.g. make the counter shm objects contain rrd arrays instead of scalar values), how much we should put into a management function (e.g. parent process takes rrd samples of the workers), and how much we should put outside Snabb entirely (e.g. external tool querying via YANG model.) And, naturally, who has time to work on something like that and when :).
IMHO all these should be outside snabb, separate daemon can query the /var/run/snabb/$pid and do stuff like populate in RRD(and other time series db like influxdb) , provide SNMP etc...
btw, what does latency histogram and VMProfile data
I have interest in exposing the snabb data via SNMP, Hopefully I will get time to take a stab at it.
@raj2569 You should talk with @alexandergall who has previously made a daemon to expose Snabb data via SNMP with NetSNMP, and with @wingo &co who are now working on making Snabb data available via YANG models (which often have mappings to SNMP MIBs.)
I also like the idea of keeping the Snabb process "dumb" and putting the smarts into external tools. The dataplane produces the data and somebody else processes it.
@raj2569 as @lukego says, I have working SNMP support to expose the ifTable and some other MIBs in my l2vpn program (currently maintained on the l2vpn branch, soon to be merged https://github.com/snabbco/snabb/tree/l2vpn/src/program/l2vpn). The code predates the current shm implementation and uses a slightly different approach based on the stuff in lib/ipc/shmem, which is a bit awkward. I'm planning to replace it with a thinner layer based on the standard shm, so it's probably not a good idea to look at that code right now :(
It basically creates raw data items for all MIB objects in a special-purpose shared memory segment (e.g. from the standard counters provided by the NIC drivers). Those segments are read by https://github.com/alexandergall/snabb-snmp-subagent, which uses the AgentX protocol to hook into a standard SNMP daemon (e.g. snmpd provided by NetSNMP). Documentation is poor, please drop me a line if you're interested.
@raj2569 Great! Could you post the data somewhere so that I can have a little noodle around before suggesting the right commands to use?
Put the vmprofile data in a spread sheet. I have selected only the interesting data here, and removed all which do not show much variation or big enough value.
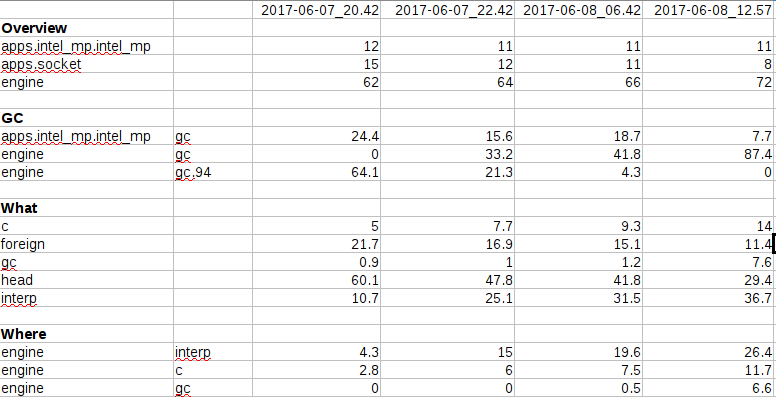
Some observations:
- Engine usage increases slightly over the period, while others decrease
- engine.gc shows a big increase, while engine.gc.94 decreases
- Interpreted code shows big increases over the period, along with c and gc. head and foreign reduces.
- Engine interpreted code, c and gc also shows increase.
Please let me know if any data I choose not to put here is important, I will update the sheet with it.
@raj2569 Great detective work! Thank you for your patience. I am now building new tools and writing new documentation about how to diagnose and fix performance problems.
The work in progress optimization guide is here: https://github.com/lukego/raptorjit/blob/optimization-guide/doc/optimization.md
Looking at your data the part that jumps out at me is the high and growing interpreter use. Generally speaking I would expect the interpreter use to be less than 1% but here it starts at 10.7% and we see it consistently growing up to 36.7%. So I would say that you need to identify the reason that some code is running interpreted and make a correction so that it will JIT compile instead. This is basically the same situation as we had in #1147 where the socket app contained code that was not JIT-able.
Please take a look at the "Eliminate interpreter mode" section and see if it is helpful!
@lukego Thanks for the fine docs, I will follow the docs and see if I can identify it.
One thing that I find strange is that the percentage of the interpreted code increases with time. What could be the reason for it?
@raj2569 I am curious about that too :-)
Hopefully we will find out along the way. Could be that there is an interesting explanation, could be that it magically disappears after switching to JIT mode, could be that performance still degrades in JIT mode and finding out why is the next step...
Where is the code here?
I would guess there's some increasing amount of polymorphism. Could be wrong of course.