SmallLanguageModel-project
 SmallLanguageModel-project copied to clipboard
SmallLanguageModel-project copied to clipboard
a LLM cookbook, for building your own from scratch, all the way from gathering data to training a model
Small Language Model
This repository contains all the necessary items needed to build your own LLM from scratch. Just follow the instructions.
Introduction
Inspired from Karpathy's nanoGPT and Shakespeare generator, I made this repository to build my own LLM. It has everything from data collection for the Model to architecture file, tokenizer and train file.
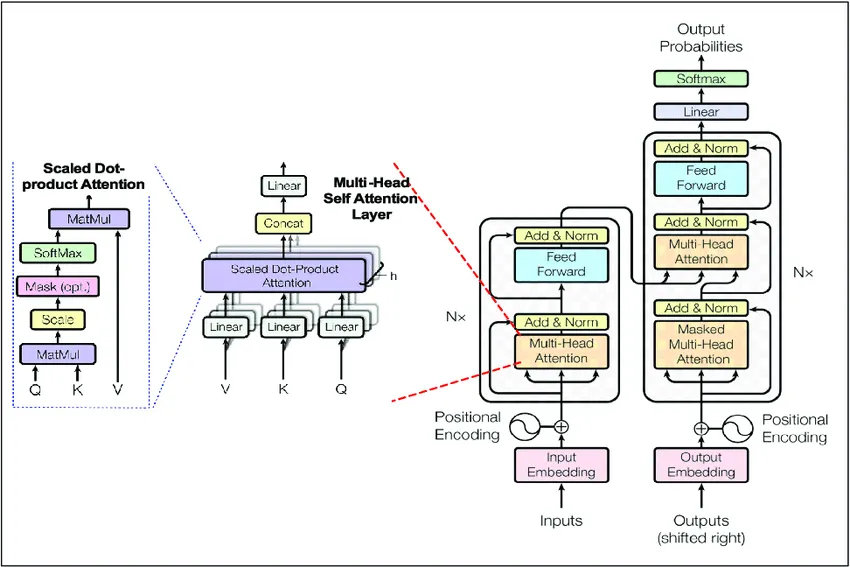
Architecture

Data Collection
I used transcripts of around 167k YouTube videos and scrapped around 10k web-pages and generated around ~5Gbs of data. You can download the data from HuggingFace if you don't wish to repeat the process. I would recommend you to at-least try once, generating the data from that same process, not much but small files, so that you understand it. If you want to specially learn about it, the data collection part, here is the repo: Data-Collection Repository
YouTube Transcripts
YouTube's V3 API is required to fetch results(video ids, urls and captions). Use Data Collector/transcriptCollector.py for collecting the data. Channel_Ids.json already has more than 45 channels' ids who have available caption data. It will take around 3days to fetch all the transcripts from over 200K videos and file size will be ~3GBs.
WebScrapping
WebScrapper uses BeautifulSoup and requests library in python to scrape data from the web, Britannica.com in this case. mainScrapper.py scrapes data from the website by building custom urls from the search_queries.json and then requesting on the url to get the data.
This generates a .txt file of ~600-700MBs approx. You can add more queries and topics for more data.
Pre-processing & tokenization
Character Level
In the initial working of the model, I used character level encoding and tokenization, for the Bi-gram model.
# this is a basic character level tokeinzer
chars = sorted(list(set(text)))
vocab_size = len(chars)
# encoder - decoder
stoi = { ch:i for i,ch in enumerate(chars) }
itos = { i:ch for i,ch in enumerate(chars) }
encode = lambda s: [stoi[c] for c in s] # encoder: take a string, output a list of integers
decode = lambda l: ''.join([itos[i] for i in l]) # decoder: take a list of integers, output a string
Sub-word Level
Implemented Byte-Pair Encoding this time using tik-token library from OpenAI. Wrote a basic training, encoding, decoding and saving model functions and then imported as a module in the code. It works fine.
# Final Models/Transformer/tokenizer.py
import tiktoken
pre_encodings = 'p50k_base'
pre_model = 'text-davinci-003'
class Tokenizer:
def __init__(self, encoding=None, model=None):
self.encodings = encoding if encoding is not None else pre_encodings
self.model = model if model is not None else pre_model
self.tokenizer = tiktoken.get_encoding(self.encodings)
self.tokenizer = tiktoken.encoding_for_model(self.model)
def encode(self, data):
return self.tokenizer.encode(data)
def decode(self, tokens):
return self.tokenizer.decode(tokens)
def get_vocab(self):
return self.tokenizer.n_vocab
Training
It's very simple, once you have a dataset, downloaded from huggingface or generated using the code provided, you'll have to choose the model you want, bi-gram or transformer, import it along with the tokenizer and train loop, and train it according to your required iterations. Modify hyperparams.json as your wish.
Or you can just use the pre-written main_script.py to start training it.
I've also provided Colab Notebooks for each type of model, in case you want to train it on a bigger level like me.
# main_script.py
import json
import os
os.chdir('D:/Machine Learning/SLM-Project')
with open('Final Models/Transformer/hyperparams.json', 'r', encoding='utf-8') as file:
params = json.load(file)
import torch
batch_size = params['batch_size']
block_size = params['block_size']
n_head = params['n_head']
n_embd = params['n_embd']
n_layer = params['n_layer']
dropout = params['dropout']
learning_rate = params['learning_rate']
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# importing training data for model
file_path = 'Data/training_data.txt'
with open(file_path, 'r', encoding='utf-8') as file:
captions = file.read()
# tokenizing the data
from tokenizer import Tokenizer
tokenizer = Tokenizer()
input_data = tokenizer.encode(captions)
# train-test split
n = int(0.9*len(input_data))
train_data = input_data[:n]
val_data = input_data[n:]
train_data = torch.tensor(train_data, dtype=torch.long)
val_data = torch.tensor(val_data, dtype=torch.long)
vocab_size = tokenizer.get_vocab()
from transformer import TransformerModel
model = TransformerModel(n_embd=n_embd, block_size=block_size, dropout=dropout, n_head=n_head, n_layer=n_layer, vocab_size=vocab_size, norm_eps=1e-5)
model = model.to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
n_param = sum(p.numel() for p in model.parameters()) / 1e6
print(f"no of parameters present are {n_param} million")
from train_model import TrainModel
train = TrainModel(model=model, optimizer=optimizer, train_data=train_data, val_data=val_data, batch_size=batch_size, block_size=block_size)
train.train_model()
# saving the model
torch.save(model.state_dict(), f"{n_param:.1f}m_model.pth")
# generating output
target_text = "Would you like to tell me your name because "
context = torch.tensor([tokenizer.encode(target_text)], dtype=torch.long, device=device)
generated_output = tokenizer.decode(model.generate(context, max_new_tokens=10)[0].tolist())
print(generated_output)
Model
Basic-Transformer
It follows a basic architecture, just Block class that has layers of MultiHeadAttention, FeedForward followed by two Normalization layers, repeating n times and a Linear layer at final. Very basic, easy to understand.
# transformer model
class GPTLanguageModel(nn.Module):
def __init__(self):
super().__init__()
self.token_embedding_table = nn.Embedding(vocab_size, n_embd)
self.position_embedding_table = nn.Embedding(block_size, n_embd)
self.blocks = nn.Sequential(*[Block(n_embd, n_head=n_head) for _ in range(n_layer)])
self.ln_f = nn.LayerNorm(n_embd, eps=norm_eps) # final layer norm
self.lm_head = nn.Linear(n_embd, vocab_size)
self.apply(self._init_weights)
def _init_weights(self, module):
if isinstance(module, nn.Linear):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
if module.bias is not None:
torch.nn.init.zeros_(module.bias.data)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
Seq-2-Seq Transfomer
It is the more complex one, with encoder and decoder layers present, repeating n_times to give the output. It's still in progress, I'll make it and upload it as soon as possible.
Star History
Contributing
Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change. Please make sure to update tests as appropriate.
License
MIT
Metadata
Owner
Metadata
a LLM cookbook, for building your own from scratch, all the way from gathering data to training a model