html5ever
 html5ever copied to clipboard
html5ever copied to clipboard
html5ever is much slower than MyHTML
https://lexborisov.github.io/benchmark-html-persers/ shows html5ever performing very badly against MyHTML, which furthermore has fewer bugs and ~~supports document.write()~~ html5ever supports document.write() in modern versions (thanks @jdm).
Sorry, I don’t see the point of this issue. “Fewer bugs” is very non-specific. If you’re aware of bugs in the latest version that aren’t listed in https://github.com/servo/html5ever/issues, it’d be more helpful to file them individually.
As to performance, just stating “very bad” isn’t particularly actionable either. Are you interested in investigating low-hanging fruit to fix performance issues?
The actionable item is attempting to reproduce the results. The benchmark repository looks like it's in good shape for doing that.
@jdm Perhaps issue #45 #51 might be more appropriate? I did ask about setting up benchmarks in a way that would work best for all parsers, but got no response, so I thought there wasn't any interest.
AFAICT the https://github.com/lexborisov/benchmark-html-persers uses C bindings for html5ever. I thought those were abandoned more than a year ago.
My thoughts were about maybe using https://github.com/seriyps/html-parsers-benchmark for comparison between different parsers and Criterion.rs for Rust specific.
https://github.com/swizard0/html2html_lib/blob/master/src/lib.rs is the Rust code that parses the document; the benchmark calls that function from C.
The C bindings in this repository were removed a year ago. IIRC they had been broken since we started using string-cache (since string-cache itself doesn’t have a C API), which happened 3 years ago. Also these bindings were only for tokenization.
According to its README.md, this benchmark uses swizard0/html2html_lib which:
- Decodes a UTF-8 byte string
- Parses into an
RcDomtree - Optionally serializes to stdout (this is disabled in the benchmark)
- Drops the tree
The tree cannot be accessed from C. (Which might be good enough for a parser.)
@nox pointed out that MyHTML does YOLO ownership of tree nodes. Whereas our reference counting probably has some overhead. If we take the time to reproduce this benchmark, we should try using a tree with arena-allocated nodes. (And when publishing results, include a date and version numbers…)
I was able to build the benchmarks. See fork. Here are my local results with top(ish) 11 sites (you can see the plots by clicking on "explore" in the right bottom corner).
MyHTML’s tree design only makes sense with a GC or with an immutable DOM. So I think that we should try with html5ever having an arena. Gumbo has a pluggable allocator, so we should give it an arena too.
Could it be that the DOM-manipulation methods in RcDom are not getting inlined? That would explain the slowdown.
Another thought: tree structures like the DOM are not one of Rust’s strengths, and RcDom has what appears to be a lot of overhead in order to be able to be written completely in safe code. I wonder if an unsafe, immutable DOM (that used raw pointers, like one would write in C) would be faster.
The benchmark’s extern fn parse_document uses TendrilSink::read_from with a &[u8] slice, treating it as a stream of unknown length that is copied into 4 KB chunks. It should use one instead, to use the slice as a single chunk. (Even that does a extra copy, though I don’t know if that’s significant compared to parsing time.)
I’ve added an arena-allocated tree, as an alternative to rcdom: https://github.com/servo/html5ever/pull/288. It doesn’t use unsafe (except in the arena library), and shouldn’t have more overhead than a tree based on raw pointers.
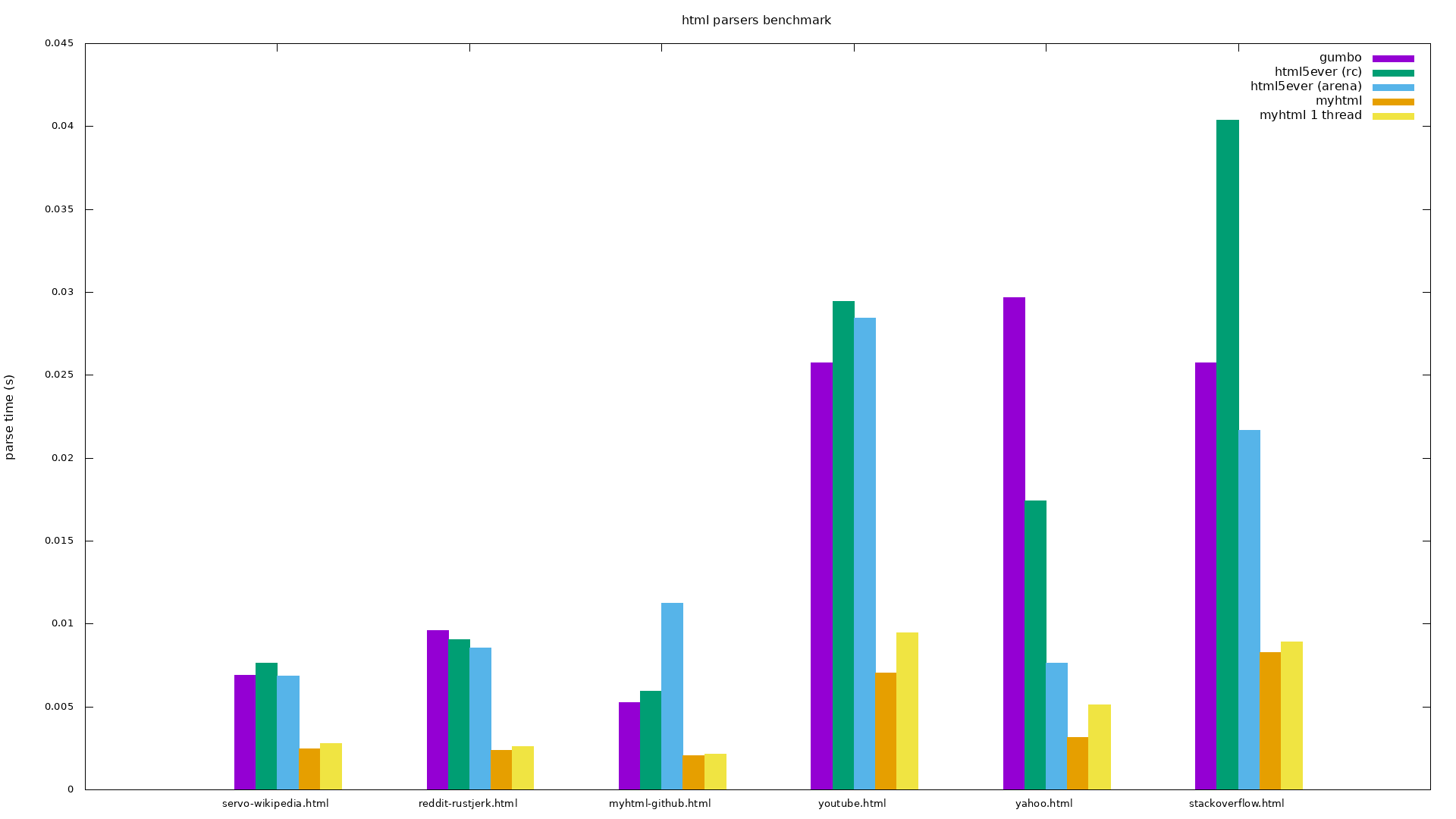
So the arena making parsing a lot faster in some cases and a lot slower in others. This seems forth investigating, but I likely won’t take time to do that in the near future.
So the arena making parsing a lot faster in some cases and a lot slower in others.
I've tried to make the benchmarks more scientific. Now arena-allocated tree doesn't look slower than rcdom.
Looks good, thanks. This shows that reference-counting does have significant overhead, but that doesn’t account for all the difference with MyHTML. The next step is probably profiling to find hot spots in html5ever.
According to perf 18% of the time is spent in tendril::push_char. That looks somewhat suspicious.
And 7.88 % is spent in core::fmt::write_char. That should not even be called by html5ever.
Here is a rasterized flame graph:
 Here is the original vectorized version (rename from .txt to .svg to view it – GitHub does not allow it because SVG files can and do contain JavaScript):
flamegraph.txt
Here is the original vectorized version (rename from .txt to .svg to view it – GitHub does not allow it because SVG files can and do contain JavaScript):
flamegraph.txt
The tokenizer does work with chars, effectively decoding UTF-8 and then re-encoding it. We should consider working on slices or u8 bytes, instead. This should be equivalent since all characters that are significant for HTML syntax are in the ASCII range instead. However this is not a small change, it’d take a significant amount of work.
@SimonSapin So if I understand correctly, this means we should use more ByteTendrils instead of StrTendrils, correct? Or iterate over StrTendril as if they were ByteTendril?
I mean only changing internal details of the tokenizer. All APIs should keep using StrTendril.
So, internally, we should use more u8. This means internally, we should use u8 instead of char, correct?
Will this require changes to Tendril or do we just use tendril.borrow()?
I’d use str::as_bytes though Deref<Target=str> for StrTendril.
Also look if Tendril::push_char is used with chars from another tendril. In those cases, try instead to keep start and end indices around and then use Tendril::subtendril to get a reference-counted view of the same buffer, without copying data.
Yes, one interesting problem is how to solve get_preprocesed_char in an elegant way? Right now it seems to be taking a char from BufferQueue, which should be replaced by a slice IIUC. I guess if all input to parser is guaranteed to be StrTendril, that shouldn't be an issue, just convert slice starting at current position to an Unicode code point (u32).
Second, is how to grab say next 4 or ten bytes from BufferQueue, theoretically speaking, first two bytes could be buffer_queue[0] and next two could be buffer_queue[1], no?
@SimonSapin Is there a particular reason a Tokenizer doesn't own the BufferQueue given to it? Does having them separate enable some sort of workflow that can't be replicated otherwise?
@Ygg01 If the tokeniser owns the buffer queue, we can't implement document.write nor speculative parsing.
Thanks nox, that's what I feared :(
EDIT: Note from chat with nox. h5e can never own any unprocessed data, because document.write() can be called at arbitrary points and change input in various ways.
@nox Do you have any thoughts on:
Also look if
Tendril::push_charis used withchars from another tendril. In those cases, try instead to keep start and end indices around and then useTendril::subtendrilto get a reference-counted view of the same buffer, without copying data.
Especially, how does one keep indicies into another tendril, when document.write could potentially change the tendril? Note: I am assuming the indices are being kept by the Tokenizer.