llama_index
 llama_index copied to clipboard
llama_index copied to clipboard
How to save the embedding from local data?
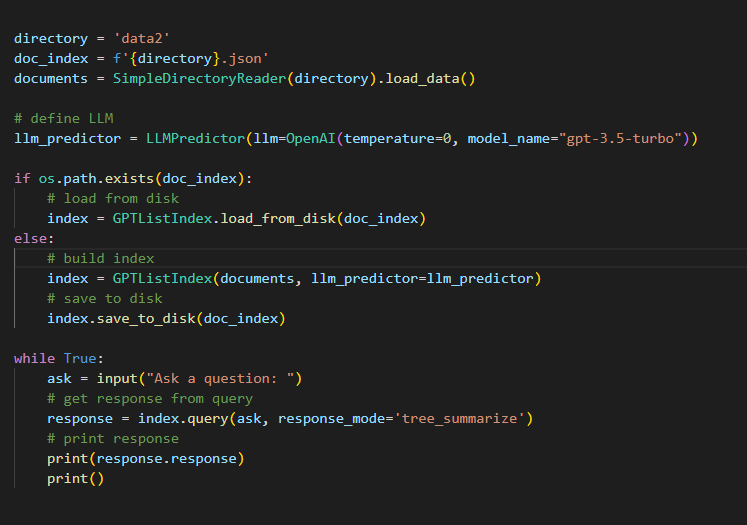
As shown in the figure, I found that every time the query function is called, it will regenerate the embedding. So, how to save it to avoid this situation?
The specific manifestation is that this line of output appears every time a query is made, and it takes a long time to wait.
INFO:root:> Building index from nodes: 45 chunks
It should be the reason of query embedding, the method:llama_index/embeddings/base.py get_query_embedding.
It should be the reason of query embedding, the method:llama_index/embeddings/base.py get_query_embedding.
This may not be the result I want. I mean, every query will request the API to build an embedding for the context, but in fact, the same context is always the same embedding. For the same document, the embedded vector representation should be the same, and there is no need to call the model every time to build the embedding. I don't know if my understanding is correct
I wonder if the reason why the index inside while True is regenerated every time is because of “index = GPTListIndex(documents)”?
Attach my code.
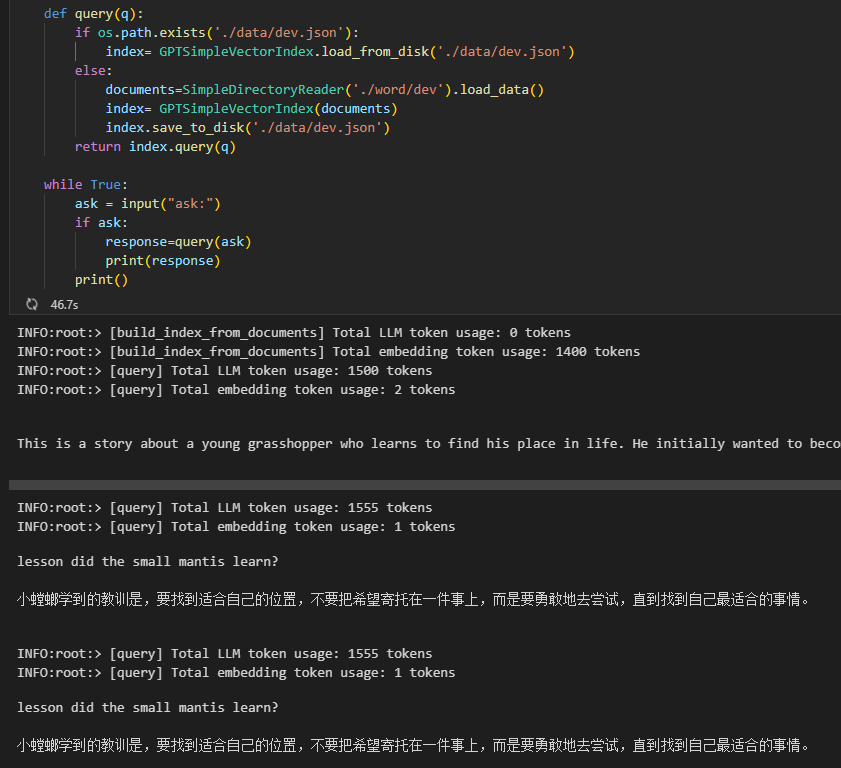
You code is the same as the figure above, GPTListIndex and GPTSimpleVectorIndex are the only diffrences, and also possible that it should be response_mode='tree_summarize', But, the document uses GPTListIndex or GPTTreeIndex, I'm not familiar with llama_index, so I can only follow tutorial.
Another point is that I don't understand whether vector storage of external data is related to this chapter, but I don't quite understand what "Using Vector Stores" is, and whether it can solve the problem of avoiding multiple generation embeddings?
But I have never seen similar code, such as storing a. txt file as an embedded vector, and then loading it for document queries, which is exactly what I want!
for example:
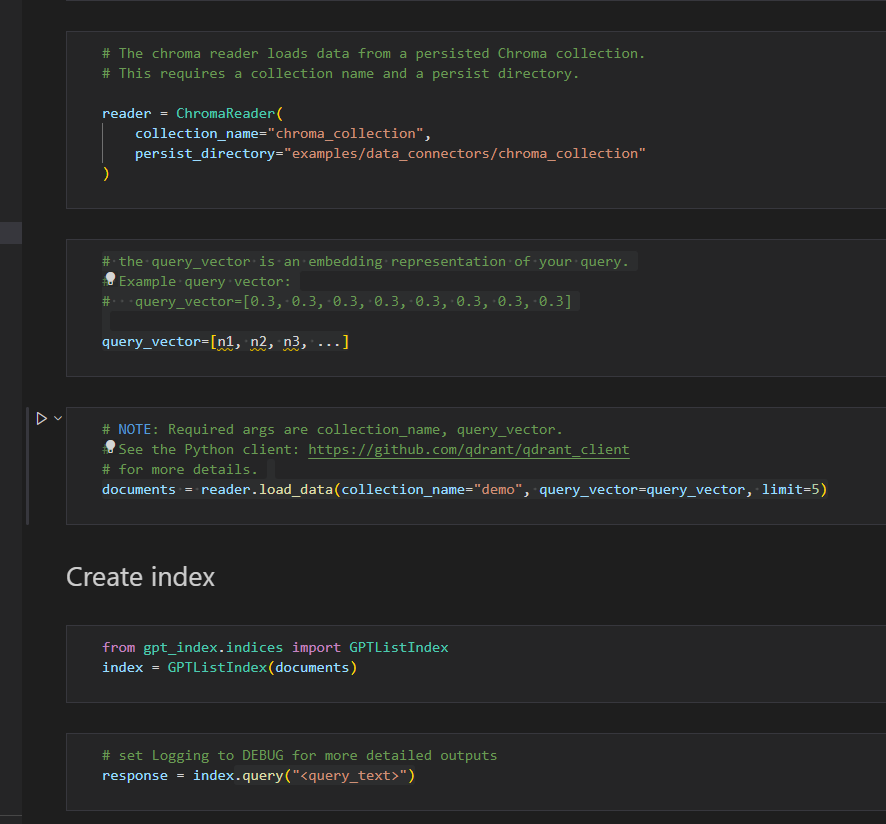 I have a few questions about the above code:
1, What
I have a few questions about the above code:
1, What ChromaReader is?
2, How to save the local data to ChromaReader and then load out?
3, What query_vector is? I mean I don't know how to build query into n1, n2, n3.....
Actually, I just want to know one thing:
1, this code response = index.query(ask, response_mode='tree_summarize', llm_predictor=llm_predictor) very slow to run at every time
2, If I terminate the program and run it again, do I have to build and embedding external data(in my code is .txt file) every time,
This wastes some unnecessary expenses for me, because, the same external data(in my code is .txt file) corresponds to the same embeddings, profitability should not be reconstructed
And I found that index.save_to_disk does not save some very resource consuming operations, so I can completely build the index from the document every time without saving it.
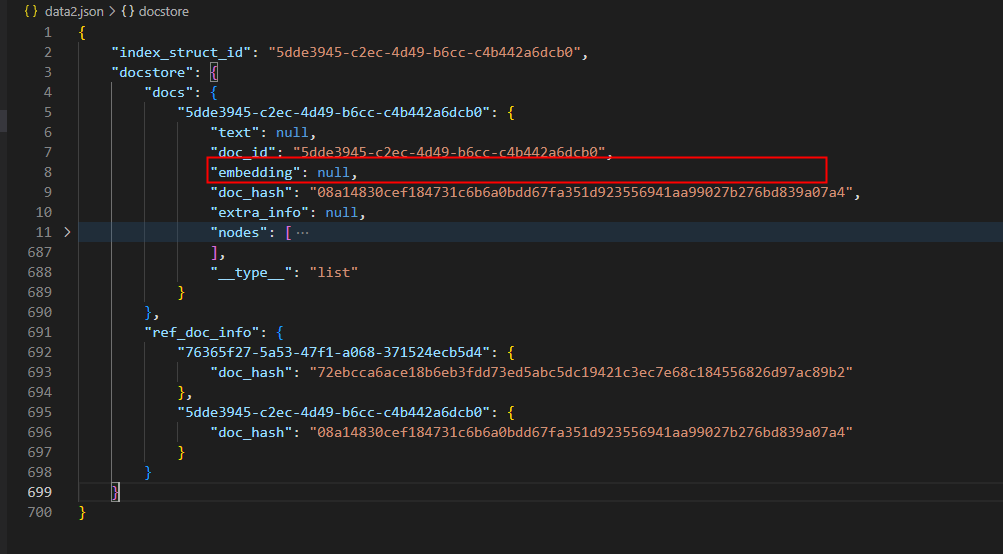 I'm not sure what the embedding here represents, but it's probably not working
I'm not sure what the embedding here represents, but it's probably not working
Hi @Luffffffy and @KopinXu
GPTListIndex does not use embedding by default. It considers all text chunks to synthesize a response (either through refinement, or hierarchical summarization).
If you want to use embedding based retrieval, please use a vector store index (e.g. GPTSimpleVectorIndex).
This guide should explain how things work: https://gpt-index.readthedocs.io/en/latest/guides/index_guide.html
We also have a FAQ doc: https://docs.google.com/document/d/1bLP7301n4w9_GsukIYvEhZXVAvOMWnrxMy089TYisXU/edit