llama_index
 llama_index copied to clipboard
llama_index copied to clipboard
I don't know how to create and optimize. Can I support more details in response mode?
I don't understand how to create and optimize answers. I am not a programmer, but an author. This response mode can only be set in three ways, but the final result is tragic. Cannot display lists, tables, etc., even if it is set to MARKDOWN, can it support more response modes? More details, like CHATAIWEB? thank you.Now AI's reply can't print more. Can the author give some specific examples? Let me see more details of him, support table list code, etc., or let him speak completely.
ps:
Setting response_mode Note: This option is not available/utilized in .GPTTreeIndex
An index can also have the following response modes through :response_mode
default: For the given index, “create and refine” an answer by sequentially going through each Node; make a separate LLM call per Node. Good for more detailed answers.
compact: For the given index, “compact” the prompt during each LLM call by stuffing as many Node text chunks that can fit within the maximum prompt size. If there are too many chunks to stuff in one prompt, “create and refine” an answer by going through multiple prompts.
tree_summarize: Given a set of Nodes and the query, recursively construct a tree and return the root node as the response. Good for summarization purposes.
index = GPTListIndex(documents)
mode="default"
response = index.query("What did the author do growing up?", response_mode="default")
mode="compact"
response = index.query("What did the author do growing up?", response_mode="compact")
mode="tree_summarize"
response = index.query("What did the author do growing up?", response_mode="tree_summarize")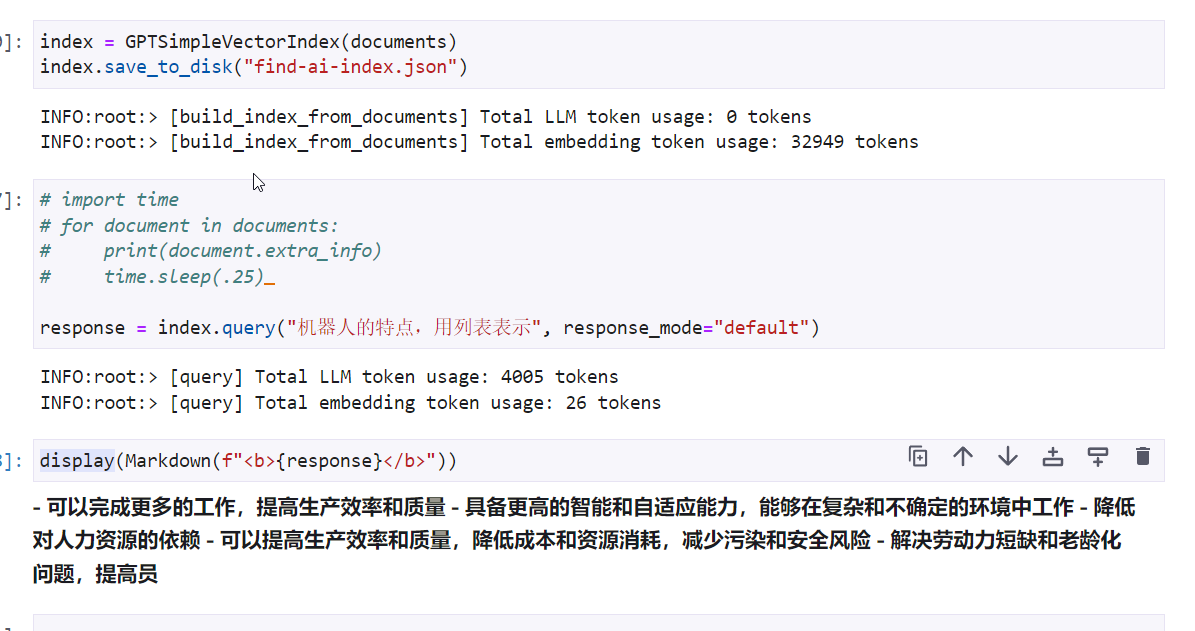
Hi @difaandailisi, not entirely sure the specific question you're asking, but if it's about increasing the output length (so that you see less truncated results), see https://gpt-index.readthedocs.io/en/latest/how_to/custom_llms.html#example-changing-the-number-of-output-tokens-for-openai-cohere-ai21
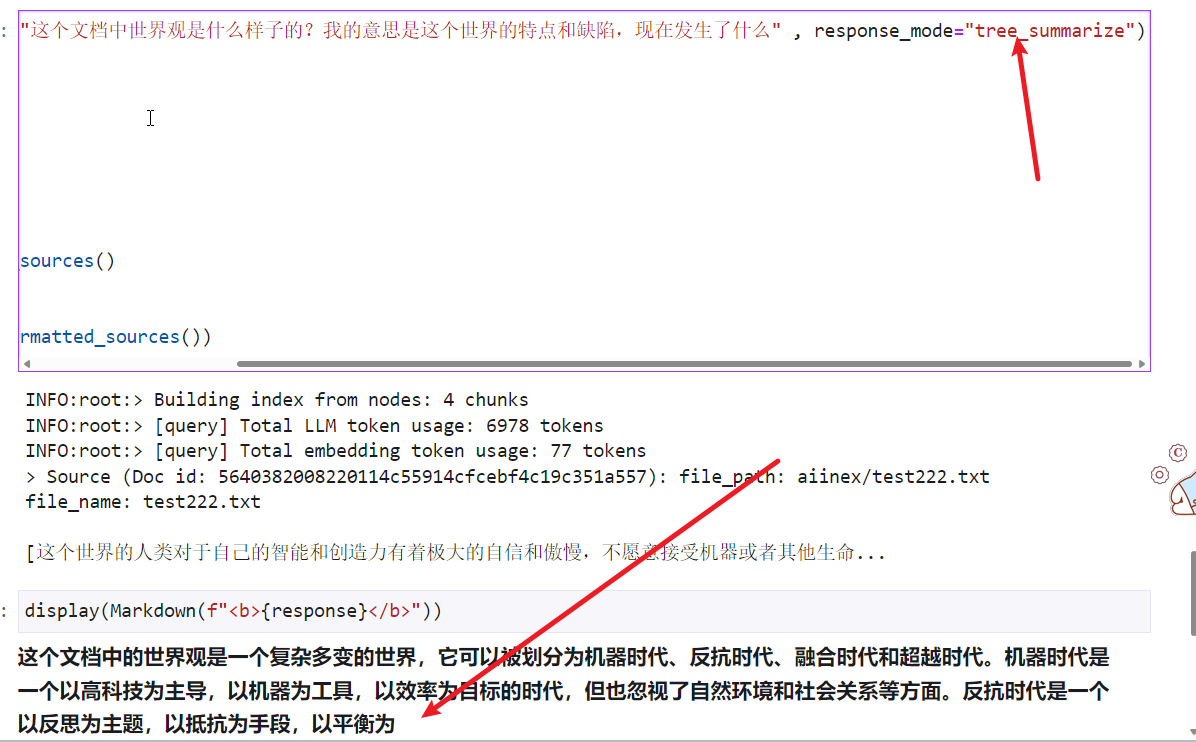
嗨@difaandailisi,不完全确定您要问的具体问题,但如果是关于增加输出长度(以便您看到更少的截断结果),请参阅 https://gpt-index.readthedocs.io/en/latest/how_to/custom_llms.html#example-changing-the-number-of-output-tokens-for-openai-cohere-ai21 抱歉,设置太大的参数会提示我,应该小点。设置小的参数,AI输出的有不完整。我不知道一个最好的参数是什么。设置成一个奇怪的参数,又会报错。可能是我的文件夹里的文件太大了。抱歉。请把zip的后缀直接改成,IPYNEB,这是一个事例简单文件。 具体的文件在这:! git clone https://github.com/difaandailisi/find-ai-index.git
[Chatbot_with_custom_knowledge_base .ipynb.zip


 ](https://github.com/jerryjliu/gpt_index/files/10921153/Chatbot_with_custom_knowledge_base.ipynb.zip)
](https://github.com/jerryjliu/gpt_index/files/10921153/Chatbot_with_custom_knowledge_base.ipynb.zip)
嗨@difaandailisi,不完全确定您要问的具体问题,但如果是关于增加输出长度(以便您看到更少的截断结果),请参阅 https://gpt-index.readthedocs.io/en/latest/how_to/custom_llms.html#example-changing-the-number-of-output-tokens-for-openai-cohere-ai21 你好,https://github.com/GaiZhenbiao/ChuanhuChatGPT 库是一个图形界面关于OPENAI的API接口,如果他能在你的帮助下得到支持,那就更好了。作为一名作者并不是程序员,对我非常难受。谢谢。
嗨@difaandailisi,不完全确定您要问的具体问题,但如果是关于增加输出长度(以便您看到更少的截断结果),请参阅 https://gpt-index.readthedocs.io/en/latest/how_to/custom_llms.html#example-changing-the-number-of-output-tokens-for-openai-cohere-ai21
不要在意这个文件中的劣质翻译,这并不是翻译,而是CHATGPTWEB网页自己注释的代码。
Closing this thread since it's a commonly asked question. Please refer to @jerryjliu answer above, or FAQ (https://docs.google.com/document/d/1bLP7301n4w9_GsukIYvEhZXVAvOMWnrxMy089TYisXU/edit#) for more details.