onnx和pytorch模型转换rknn模型,输出结果shape不一样
如题,部署设备是rk1808,问题出现的测试demo:
import torch
import torch.nn as nn
class Tmodel(nn.Module):
def __init__(self, length=28):
super().__init__()
self.values = [self._norm(d) for d in [length, length]]
def _norm(self, length):
first = -(length - 1.0) / length
values = torch.arange(length, device='cpu') * (2.0 / length) + first
return values
def forward(self, probs):
assert(len(self.values) == probs.ndimension() - 2)
expectation = []
marg1 = probs.sum(3, keepdim=False)
marg2 = probs.sum(2, keepdim=False)
marg1 = self.values[0] * marg1
marg2 = self.values[1] * marg2
expectation.append(marg1.sum(marg1.ndim-1, keepdim=False))
expectation.append(marg2.sum(marg2.ndim-1, keepdim=False))
return torch.stack(expectation, -1)
net = Tmodel()
net.eval()
x = torch.rand(1, 1, 28, 28)
torch.onnx.export(net,
x,
'./tmodel.onnx',
verbose=False,
opset_version=11,
do_constant_folding=True,
input_names=['input'],
output_names=['output'])
print('export success.')
在转换到rknn时,出现如下错误:
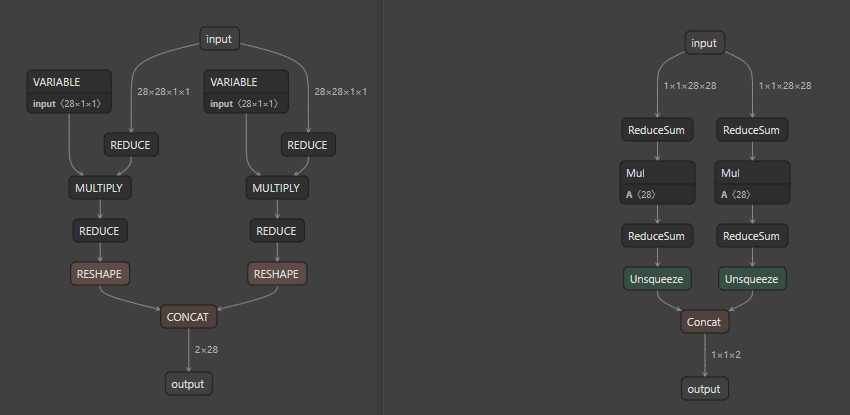
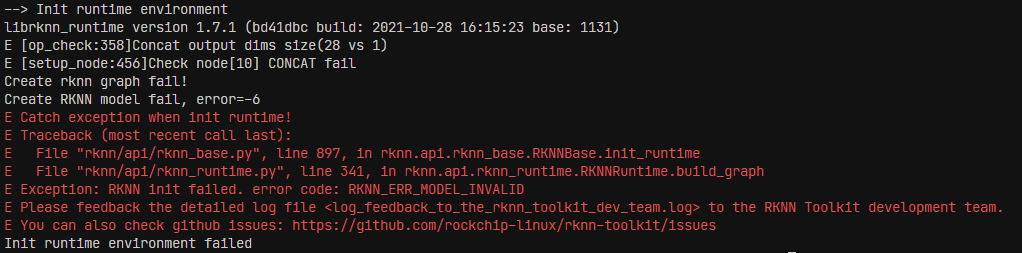 查看转换成的rknn模型,发现输出的shape与onnx不相同,
查看转换成的rknn模型,发现输出的shape与onnx不相同,
 转换日志如下:
D Using CPPUTILS: True
I Start importing onnx...
I Current ONNX Model use ir_version 6 opset_version 11
I Call RKNN onnx optimize fail, skip optimize
D Calc tensor ReduceSum_2 (1, 1, 28)
D Calc tensor ReduceSum_1 (1, 1, 28)
D Calc tensor Initializer_5 (28,)
D Calc tensor Mul_6 (1, 1, 28)
D Calc tensor ReduceSum_8 (1, 1)
D Calc tensor Unsqueeze_10 (1, 1, 1)
D Calc tensor Initializer_3 (28,)
D Calc tensor Mul_4 (1, 1, 28)
D Calc tensor ReduceSum_7 (1, 1)
D Calc tensor Unsqueeze_9 (1, 1, 1)
D Calc tensor Concat_output (1, 1, 2)
D import clients finished
I build output layer attach_Concat_Concat_10:out0
I Try match layer: Concat_Concat_10:out0
I Match concat_2, convert ONNX layer: ['Concat_Concat_10'](OPs: ['Concat']) to ['concat']
I Try match layer: Unsqueeze_Unsqueeze_8:out0
I Match r_unsqueeze, convert ONNX layer: ['Unsqueeze_Unsqueeze_8'](OPs: ['Unsqueeze']) to ['reshape']
I Try match layer: Unsqueeze_Unsqueeze_9:out0
I Match r_unsqueeze, convert ONNX layer: ['Unsqueeze_Unsqueeze_9'](OPs: ['Unsqueeze']) to ['reshape']
I Try match layer: ReduceSum_ReduceSum_6:out0
I Match r_reducesum, convert ONNX layer: ['ReduceSum_ReduceSum_6'](OPs: ['ReduceSum']) to ['reducesum']
I Try match layer: ReduceSum_ReduceSum_7:out0
I Match r_reducesum, convert ONNX layer: ['ReduceSum_ReduceSum_7'](OPs: ['ReduceSum']) to ['reducesum']
I Try match layer: Mul_Mul_3:out0
I Match r_mul, convert ONNX layer: ['Mul_Mul_3'](OPs: ['Mul']) to ['multiply']
I Try match layer: Mul_Mul_5:out0
I Match r_mul, convert ONNX layer: ['Mul_Mul_5'](OPs: ['Mul']) to ['multiply']
I Try match layer: Initializer_3:out0
I Match r_variable, convert ONNX layer: ['Initializer_3'](OPs: ['Constant']) to ['variable']
I Try match layer: ReduceSum_ReduceSum_0:out0
I Match r_reducesum, convert ONNX layer: ['ReduceSum_ReduceSum_0'](OPs: ['ReduceSum']) to ['reducesum']
I Try match layer: Initializer_5:out0
I Match r_variable, convert ONNX layer: ['Initializer_5'](OPs: ['Constant']) to ['variable']
I Try match layer: ReduceSum_ReduceSum_1:out0
I Match r_reducesum, convert ONNX layer: ['ReduceSum_ReduceSum_1'](OPs: ['ReduceSum']) to ['reducesum']
W Input channel 1 less then 3, please update NPU Driver to v1.3.0 or later.
I build input layer input:out0
D connect Unsqueeze_Unsqueeze_8_2 0 ~ Concat_Concat_10_1 0
D connect Unsqueeze_Unsqueeze_9_3 0 ~ Concat_Concat_10_1 1
D connect ReduceSum_ReduceSum_6_4 0 ~ Unsqueeze_Unsqueeze_8_2 0
D connect ReduceSum_ReduceSum_7_5 0 ~ Unsqueeze_Unsqueeze_9_3 0
D connect Mul_Mul_3_6 0 ~ ReduceSum_ReduceSum_6_4 0
D connect Mul_Mul_5_7 0 ~ ReduceSum_ReduceSum_7_5 0
D connect Initializer_3_8 0 ~ Mul_Mul_3_6 0
D connect ReduceSum_ReduceSum_0_9 0 ~ Mul_Mul_3_6 1
D connect Initializer_5_10 0 ~ Mul_Mul_5_7 0
D connect ReduceSum_ReduceSum_1_11 0 ~ Mul_Mul_5_7 1
D connect input_12 0 ~ ReduceSum_ReduceSum_0_9 0
D connect input_12 0 ~ ReduceSum_ReduceSum_1_11 0
D connect Concat_Concat_10_1 0 ~ attach_Concat_Concat_10/out0_0 0
D Process Initializer_3_8 ...
D RKNN output shape(variable): (28)
D Process input_12 ...
D RKNN output shape(input): (1 28 28 1)
D Tensor @input_12:out0 type: float32
D Process ReduceSum_ReduceSum_0_9 ...
D RKNN output shape(reducesum): (1 1 28)
D Tensor @ReduceSum_ReduceSum_0_9:out0 type: float32
D Process Mul_Mul_3_6 ...
D RKNN output shape(multiply): (1 1 28)
D Tensor @Mul_Mul_3_6:out0 type: float32
D Process ReduceSum_ReduceSum_6_4 ...
W Warning: Axis may need to be adjusted according to original model shape.
D RKNN output shape(reducesum): (1 1)
D Tensor @ReduceSum_ReduceSum_6_4:out0 type: float32
D Process Unsqueeze_Unsqueeze_8_2 ...
D RKNN output shape(reshape): (1 1)
D Tensor @Unsqueeze_Unsqueeze_8_2:out0 type: float32
D Process Initializer_5_10 ...
D RKNN output shape(variable): (28)
D Process ReduceSum_ReduceSum_1_11 ...
D RKNN output shape(reducesum): (1 1 28)
D Tensor @ReduceSum_ReduceSum_1_11:out0 type: float32
D Process Mul_Mul_5_7 ...
D RKNN output shape(multiply): (1 1 28)
D Tensor @Mul_Mul_5_7:out0 type: float32
D Process ReduceSum_ReduceSum_7_5 ...
W Warning: Axis may need to be adjusted according to original model shape.
D RKNN output shape(reducesum): (1 1)
D Tensor @ReduceSum_ReduceSum_7_5:out0 type: float32
D Process Unsqueeze_Unsqueeze_9_3 ...
D RKNN output shape(reshape): (1 1)
D Tensor @Unsqueeze_Unsqueeze_9_3:out0 type: float32
D Process Concat_Concat_10_1 ...
W Warning: Axis may need to be adjusted according to original model shape.
D RKNN output shape(concat): (1 2)
D Tensor @Concat_Concat_10_1:out0 type: float32
D Process attach_Concat_Concat_10/out0_0 ...
D RKNN output shape(output): (1 2)
D Tensor @attach_Concat_Concat_10/out0_0:out0 type: float32
I Build torch-jit-export complete.
I Start C2T Switcher...
D Optimizing network with broadcast_op
D Align variable Initializer_3_8 shape [28] to [1, 1, 28]
D Align variable Initializer_5_10 shape [28] to [1, 1, 28]
D convert ReduceSum_ReduceSum_0_9(reducesum) axes [3] to [2]
D convert ReduceSum_ReduceSum_1_11(reducesum) axes [2] to [1]
D convert Mul_Mul_3_6(multiply) axis 1 to 2
D convert Mul_Mul_5_7(multiply) axis 1 to 2
D insert permute ReduceSum_ReduceSum_6_4_RKNN_mark_perm_13 before ReduceSum_ReduceSum_6_4
D insert permute ReduceSum_ReduceSum_7_5_RKNN_mark_perm_14 before ReduceSum_ReduceSum_7_5
I End C2T Switcher...
D Optimizing network with force_1d_tensor, swapper, merge_duplicate_quantize_dequantize, merge_layer, auto_fill_bn, auto_fill_l2normalizescale, auto_fill_instancenormalize, resize_nearest_transformer, eltwise_transform, auto_fill_multiply, auto_fill_zero_bias, proposal_opt_import, special_add_to_conv2d
I End importing onnx...
W The target_platform is not set in config, using default target platform rk1808.
I Generate input meta ...
I Load input meta
I Generate input meta ...
D import clients finished
I Load net...
I Load data...
I Load input meta
D Process Initializer_3_8 ...
D RKNN output shape(variable): (1 28 1)
D Process input_12 ...
D RKNN output shape(input): (1 28 28 1)
D Tensor @input_12:out0 type: float32
D Process ReduceSum_ReduceSum_0_9 ...
D RKNN output shape(reducesum): (1 1 28)
D Tensor @ReduceSum_ReduceSum_0_9:out0 type: float32
D Process Mul_Mul_3_6 ...
D RKNN output shape(multiply): (1 28 28)
D Tensor @Mul_Mul_3_6:out0 type: float32
D Process ReduceSum_ReduceSum_6_4_RKNN_mark_perm_13 ...
D RKNN output shape(permute): (1 28 28)
D Tensor @ReduceSum_ReduceSum_6_4_RKNN_mark_perm_13:out0 type: float32
D Process ReduceSum_ReduceSum_6_4 ...
D RKNN output shape(reducesum): (1 28)
D Tensor @ReduceSum_ReduceSum_6_4:out0 type: float32
D Process Unsqueeze_Unsqueeze_8_2 ...
D RKNN output shape(reshape): (28 1)
D Tensor @Unsqueeze_Unsqueeze_8_2:out0 type: float32
D Process Initializer_5_10 ...
D RKNN output shape(variable): (1 28 1)
D Process ReduceSum_ReduceSum_1_11 ...
D RKNN output shape(reducesum): (1 1 28)
D Tensor @ReduceSum_ReduceSum_1_11:out0 type: float32
D Process Mul_Mul_5_7 ...
D RKNN output shape(multiply): (1 28 28)
D Tensor @Mul_Mul_5_7:out0 type: float32
D Process ReduceSum_ReduceSum_7_5_RKNN_mark_perm_14 ...
D RKNN output shape(permute): (1 28 28)
D Tensor @ReduceSum_ReduceSum_7_5_RKNN_mark_perm_14:out0 type: float32
D Process ReduceSum_ReduceSum_7_5 ...
D RKNN output shape(reducesum): (1 28)
D Tensor @ReduceSum_ReduceSum_7_5:out0 type: float32
D Process Unsqueeze_Unsqueeze_9_3 ...
D RKNN output shape(reshape): (28 1)
D Tensor @Unsqueeze_Unsqueeze_9_3:out0 type: float32
D Process Concat_Concat_10_1 ...
D RKNN output shape(concat): (28 2)
D Tensor @Concat_Concat_10_1:out0 type: float32
D Process attach_Concat_Concat_10/out0_0 ...
D RKNN output shape(output): (28 2)
D Tensor @attach_Concat_Concat_10/out0_0:out0 type: float32
I Build torch-jit-export complete.
I Initialzing network optimizer by /root/anaconda3/envs/torch/lib/python3.6/site-packages/rknn/config/npu_config/LION ...
D Optimizing network with merge_ximum, qnt_adjust_coef, multiply_transform, add_extra_io, format_input_ops, auto_fill_zero_bias, conv_kernel_transform, twod_op_transform, strip_op, extend_unstack_split, merge_layer, transform_layer, broadcast_op, strip_op, auto_fill_reshape_zero, adjust_output_attrs, insert_dtype_converter
I Start T2C Switcher...
D Optimizing network with broadcast_op, t2c_fc
D convert ReduceSum_ReduceSum_0_9(reducesum) axes [2] to [3]
D convert ReduceSum_ReduceSum_1_11(reducesum) axes [1] to [2]
D convert Mul_Mul_3_6(multiply) axis 2 to 1
D convert Mul_Mul_5_7(multiply) axis 2 to 1
D insert permute ReduceSum_ReduceSum_6_4_RKNN_mark_perm_13_RKNN_mark_perm_15 before ReduceSum_ReduceSum_6_4_RKNN_mark_perm_13
D insert permute ReduceSum_ReduceSum_7_5_RKNN_mark_perm_14_RKNN_mark_perm_16 before ReduceSum_ReduceSum_7_5_RKNN_mark_perm_14
D remove permute ReduceSum_ReduceSum_6_4_RKNN_mark_perm_13_RKNN_mark_perm_15
D remove permute ReduceSum_ReduceSum_6_4_RKNN_mark_perm_13
D remove permute ReduceSum_ReduceSum_7_5_RKNN_mark_perm_14_RKNN_mark_perm_16
D remove permute ReduceSum_ReduceSum_7_5_RKNN_mark_perm_14
I End T2C Switcher...
D Optimizing network with merge_ximum, qnt_adjust_coef, multiply_transform, add_extra_io, format_input_ops, auto_fill_zero_bias, conv_kernel_transform, twod_op_transform, strip_op, extend_unstack_split, merge_layer, transform_layer, broadcast_op, strip_op, auto_fill_reshape_zero, adjust_output_attrs, insert_dtype_converter
D Optimizing network with conv_1xn_transform, proposal_opt, c2drv_convert_axis, c2drv_convert_shape, c2drv_convert_array, c2drv_cast_dtype, c2drv_trans_data
I Building data ...
I Packing data ...
D Packing Initializer_3_8 ...
D Packing Initializer_5_10 ...
D output tensor id = 0, name = Concat_Concat_10/out0_0
D input tensor id = 1, name = input_12
I Build config finished.
D target set by user is: None
D Starting ntp or adb, target is None, host is None
I When we run model on simulator, we do not need set perf_debug to get layer performance.
E Catch exception when init runtime!
E Traceback (most recent call last):
E File "rknn/api/rknn_base.py", line 897, in rknn.api.rknn_base.RKNNBase.init_runtime
E File "rknn/api/rknn_runtime.py", line 341, in rknn.api.rknn_runtime.RKNNRuntime.build_graph
E Exception: RKNN init failed. error code: RKNN_ERR_MODEL_INVALID
E Please feedback the detailed log file <log_feedback_to_the_rknn_toolkit_dev_team.log> to the RKNN Toolkit development team.
E You can also check github issues: https://github.com/rockchip-linux/rknn-toolkit/issues
转换日志如下:
D Using CPPUTILS: True
I Start importing onnx...
I Current ONNX Model use ir_version 6 opset_version 11
I Call RKNN onnx optimize fail, skip optimize
D Calc tensor ReduceSum_2 (1, 1, 28)
D Calc tensor ReduceSum_1 (1, 1, 28)
D Calc tensor Initializer_5 (28,)
D Calc tensor Mul_6 (1, 1, 28)
D Calc tensor ReduceSum_8 (1, 1)
D Calc tensor Unsqueeze_10 (1, 1, 1)
D Calc tensor Initializer_3 (28,)
D Calc tensor Mul_4 (1, 1, 28)
D Calc tensor ReduceSum_7 (1, 1)
D Calc tensor Unsqueeze_9 (1, 1, 1)
D Calc tensor Concat_output (1, 1, 2)
D import clients finished
I build output layer attach_Concat_Concat_10:out0
I Try match layer: Concat_Concat_10:out0
I Match concat_2, convert ONNX layer: ['Concat_Concat_10'](OPs: ['Concat']) to ['concat']
I Try match layer: Unsqueeze_Unsqueeze_8:out0
I Match r_unsqueeze, convert ONNX layer: ['Unsqueeze_Unsqueeze_8'](OPs: ['Unsqueeze']) to ['reshape']
I Try match layer: Unsqueeze_Unsqueeze_9:out0
I Match r_unsqueeze, convert ONNX layer: ['Unsqueeze_Unsqueeze_9'](OPs: ['Unsqueeze']) to ['reshape']
I Try match layer: ReduceSum_ReduceSum_6:out0
I Match r_reducesum, convert ONNX layer: ['ReduceSum_ReduceSum_6'](OPs: ['ReduceSum']) to ['reducesum']
I Try match layer: ReduceSum_ReduceSum_7:out0
I Match r_reducesum, convert ONNX layer: ['ReduceSum_ReduceSum_7'](OPs: ['ReduceSum']) to ['reducesum']
I Try match layer: Mul_Mul_3:out0
I Match r_mul, convert ONNX layer: ['Mul_Mul_3'](OPs: ['Mul']) to ['multiply']
I Try match layer: Mul_Mul_5:out0
I Match r_mul, convert ONNX layer: ['Mul_Mul_5'](OPs: ['Mul']) to ['multiply']
I Try match layer: Initializer_3:out0
I Match r_variable, convert ONNX layer: ['Initializer_3'](OPs: ['Constant']) to ['variable']
I Try match layer: ReduceSum_ReduceSum_0:out0
I Match r_reducesum, convert ONNX layer: ['ReduceSum_ReduceSum_0'](OPs: ['ReduceSum']) to ['reducesum']
I Try match layer: Initializer_5:out0
I Match r_variable, convert ONNX layer: ['Initializer_5'](OPs: ['Constant']) to ['variable']
I Try match layer: ReduceSum_ReduceSum_1:out0
I Match r_reducesum, convert ONNX layer: ['ReduceSum_ReduceSum_1'](OPs: ['ReduceSum']) to ['reducesum']
W Input channel 1 less then 3, please update NPU Driver to v1.3.0 or later.
I build input layer input:out0
D connect Unsqueeze_Unsqueeze_8_2 0 ~ Concat_Concat_10_1 0
D connect Unsqueeze_Unsqueeze_9_3 0 ~ Concat_Concat_10_1 1
D connect ReduceSum_ReduceSum_6_4 0 ~ Unsqueeze_Unsqueeze_8_2 0
D connect ReduceSum_ReduceSum_7_5 0 ~ Unsqueeze_Unsqueeze_9_3 0
D connect Mul_Mul_3_6 0 ~ ReduceSum_ReduceSum_6_4 0
D connect Mul_Mul_5_7 0 ~ ReduceSum_ReduceSum_7_5 0
D connect Initializer_3_8 0 ~ Mul_Mul_3_6 0
D connect ReduceSum_ReduceSum_0_9 0 ~ Mul_Mul_3_6 1
D connect Initializer_5_10 0 ~ Mul_Mul_5_7 0
D connect ReduceSum_ReduceSum_1_11 0 ~ Mul_Mul_5_7 1
D connect input_12 0 ~ ReduceSum_ReduceSum_0_9 0
D connect input_12 0 ~ ReduceSum_ReduceSum_1_11 0
D connect Concat_Concat_10_1 0 ~ attach_Concat_Concat_10/out0_0 0
D Process Initializer_3_8 ...
D RKNN output shape(variable): (28)
D Process input_12 ...
D RKNN output shape(input): (1 28 28 1)
D Tensor @input_12:out0 type: float32
D Process ReduceSum_ReduceSum_0_9 ...
D RKNN output shape(reducesum): (1 1 28)
D Tensor @ReduceSum_ReduceSum_0_9:out0 type: float32
D Process Mul_Mul_3_6 ...
D RKNN output shape(multiply): (1 1 28)
D Tensor @Mul_Mul_3_6:out0 type: float32
D Process ReduceSum_ReduceSum_6_4 ...
W Warning: Axis may need to be adjusted according to original model shape.
D RKNN output shape(reducesum): (1 1)
D Tensor @ReduceSum_ReduceSum_6_4:out0 type: float32
D Process Unsqueeze_Unsqueeze_8_2 ...
D RKNN output shape(reshape): (1 1)
D Tensor @Unsqueeze_Unsqueeze_8_2:out0 type: float32
D Process Initializer_5_10 ...
D RKNN output shape(variable): (28)
D Process ReduceSum_ReduceSum_1_11 ...
D RKNN output shape(reducesum): (1 1 28)
D Tensor @ReduceSum_ReduceSum_1_11:out0 type: float32
D Process Mul_Mul_5_7 ...
D RKNN output shape(multiply): (1 1 28)
D Tensor @Mul_Mul_5_7:out0 type: float32
D Process ReduceSum_ReduceSum_7_5 ...
W Warning: Axis may need to be adjusted according to original model shape.
D RKNN output shape(reducesum): (1 1)
D Tensor @ReduceSum_ReduceSum_7_5:out0 type: float32
D Process Unsqueeze_Unsqueeze_9_3 ...
D RKNN output shape(reshape): (1 1)
D Tensor @Unsqueeze_Unsqueeze_9_3:out0 type: float32
D Process Concat_Concat_10_1 ...
W Warning: Axis may need to be adjusted according to original model shape.
D RKNN output shape(concat): (1 2)
D Tensor @Concat_Concat_10_1:out0 type: float32
D Process attach_Concat_Concat_10/out0_0 ...
D RKNN output shape(output): (1 2)
D Tensor @attach_Concat_Concat_10/out0_0:out0 type: float32
I Build torch-jit-export complete.
I Start C2T Switcher...
D Optimizing network with broadcast_op
D Align variable Initializer_3_8 shape [28] to [1, 1, 28]
D Align variable Initializer_5_10 shape [28] to [1, 1, 28]
D convert ReduceSum_ReduceSum_0_9(reducesum) axes [3] to [2]
D convert ReduceSum_ReduceSum_1_11(reducesum) axes [2] to [1]
D convert Mul_Mul_3_6(multiply) axis 1 to 2
D convert Mul_Mul_5_7(multiply) axis 1 to 2
D insert permute ReduceSum_ReduceSum_6_4_RKNN_mark_perm_13 before ReduceSum_ReduceSum_6_4
D insert permute ReduceSum_ReduceSum_7_5_RKNN_mark_perm_14 before ReduceSum_ReduceSum_7_5
I End C2T Switcher...
D Optimizing network with force_1d_tensor, swapper, merge_duplicate_quantize_dequantize, merge_layer, auto_fill_bn, auto_fill_l2normalizescale, auto_fill_instancenormalize, resize_nearest_transformer, eltwise_transform, auto_fill_multiply, auto_fill_zero_bias, proposal_opt_import, special_add_to_conv2d
I End importing onnx...
W The target_platform is not set in config, using default target platform rk1808.
I Generate input meta ...
I Load input meta
I Generate input meta ...
D import clients finished
I Load net...
I Load data...
I Load input meta
D Process Initializer_3_8 ...
D RKNN output shape(variable): (1 28 1)
D Process input_12 ...
D RKNN output shape(input): (1 28 28 1)
D Tensor @input_12:out0 type: float32
D Process ReduceSum_ReduceSum_0_9 ...
D RKNN output shape(reducesum): (1 1 28)
D Tensor @ReduceSum_ReduceSum_0_9:out0 type: float32
D Process Mul_Mul_3_6 ...
D RKNN output shape(multiply): (1 28 28)
D Tensor @Mul_Mul_3_6:out0 type: float32
D Process ReduceSum_ReduceSum_6_4_RKNN_mark_perm_13 ...
D RKNN output shape(permute): (1 28 28)
D Tensor @ReduceSum_ReduceSum_6_4_RKNN_mark_perm_13:out0 type: float32
D Process ReduceSum_ReduceSum_6_4 ...
D RKNN output shape(reducesum): (1 28)
D Tensor @ReduceSum_ReduceSum_6_4:out0 type: float32
D Process Unsqueeze_Unsqueeze_8_2 ...
D RKNN output shape(reshape): (28 1)
D Tensor @Unsqueeze_Unsqueeze_8_2:out0 type: float32
D Process Initializer_5_10 ...
D RKNN output shape(variable): (1 28 1)
D Process ReduceSum_ReduceSum_1_11 ...
D RKNN output shape(reducesum): (1 1 28)
D Tensor @ReduceSum_ReduceSum_1_11:out0 type: float32
D Process Mul_Mul_5_7 ...
D RKNN output shape(multiply): (1 28 28)
D Tensor @Mul_Mul_5_7:out0 type: float32
D Process ReduceSum_ReduceSum_7_5_RKNN_mark_perm_14 ...
D RKNN output shape(permute): (1 28 28)
D Tensor @ReduceSum_ReduceSum_7_5_RKNN_mark_perm_14:out0 type: float32
D Process ReduceSum_ReduceSum_7_5 ...
D RKNN output shape(reducesum): (1 28)
D Tensor @ReduceSum_ReduceSum_7_5:out0 type: float32
D Process Unsqueeze_Unsqueeze_9_3 ...
D RKNN output shape(reshape): (28 1)
D Tensor @Unsqueeze_Unsqueeze_9_3:out0 type: float32
D Process Concat_Concat_10_1 ...
D RKNN output shape(concat): (28 2)
D Tensor @Concat_Concat_10_1:out0 type: float32
D Process attach_Concat_Concat_10/out0_0 ...
D RKNN output shape(output): (28 2)
D Tensor @attach_Concat_Concat_10/out0_0:out0 type: float32
I Build torch-jit-export complete.
I Initialzing network optimizer by /root/anaconda3/envs/torch/lib/python3.6/site-packages/rknn/config/npu_config/LION ...
D Optimizing network with merge_ximum, qnt_adjust_coef, multiply_transform, add_extra_io, format_input_ops, auto_fill_zero_bias, conv_kernel_transform, twod_op_transform, strip_op, extend_unstack_split, merge_layer, transform_layer, broadcast_op, strip_op, auto_fill_reshape_zero, adjust_output_attrs, insert_dtype_converter
I Start T2C Switcher...
D Optimizing network with broadcast_op, t2c_fc
D convert ReduceSum_ReduceSum_0_9(reducesum) axes [2] to [3]
D convert ReduceSum_ReduceSum_1_11(reducesum) axes [1] to [2]
D convert Mul_Mul_3_6(multiply) axis 2 to 1
D convert Mul_Mul_5_7(multiply) axis 2 to 1
D insert permute ReduceSum_ReduceSum_6_4_RKNN_mark_perm_13_RKNN_mark_perm_15 before ReduceSum_ReduceSum_6_4_RKNN_mark_perm_13
D insert permute ReduceSum_ReduceSum_7_5_RKNN_mark_perm_14_RKNN_mark_perm_16 before ReduceSum_ReduceSum_7_5_RKNN_mark_perm_14
D remove permute ReduceSum_ReduceSum_6_4_RKNN_mark_perm_13_RKNN_mark_perm_15
D remove permute ReduceSum_ReduceSum_6_4_RKNN_mark_perm_13
D remove permute ReduceSum_ReduceSum_7_5_RKNN_mark_perm_14_RKNN_mark_perm_16
D remove permute ReduceSum_ReduceSum_7_5_RKNN_mark_perm_14
I End T2C Switcher...
D Optimizing network with merge_ximum, qnt_adjust_coef, multiply_transform, add_extra_io, format_input_ops, auto_fill_zero_bias, conv_kernel_transform, twod_op_transform, strip_op, extend_unstack_split, merge_layer, transform_layer, broadcast_op, strip_op, auto_fill_reshape_zero, adjust_output_attrs, insert_dtype_converter
D Optimizing network with conv_1xn_transform, proposal_opt, c2drv_convert_axis, c2drv_convert_shape, c2drv_convert_array, c2drv_cast_dtype, c2drv_trans_data
I Building data ...
I Packing data ...
D Packing Initializer_3_8 ...
D Packing Initializer_5_10 ...
D output tensor id = 0, name = Concat_Concat_10/out0_0
D input tensor id = 1, name = input_12
I Build config finished.
D target set by user is: None
D Starting ntp or adb, target is None, host is None
I When we run model on simulator, we do not need set perf_debug to get layer performance.
E Catch exception when init runtime!
E Traceback (most recent call last):
E File "rknn/api/rknn_base.py", line 897, in rknn.api.rknn_base.RKNNBase.init_runtime
E File "rknn/api/rknn_runtime.py", line 341, in rknn.api.rknn_runtime.RKNNRuntime.build_graph
E Exception: RKNN init failed. error code: RKNN_ERR_MODEL_INVALID
E Please feedback the detailed log file <log_feedback_to_the_rknn_toolkit_dev_team.log> to the RKNN Toolkit development team.
E You can also check github issues: https://github.com/rockchip-linux/rknn-toolkit/issues