audio
 audio copied to clipboard
audio copied to clipboard
Issues with transforms.InverseMelScale
Hi! I have had some issues using InverseMelScale
Firstly, I used the transform on a Spectrogram, without taking the log or using AmplitudeToDB on the spectrogram. This resulted in very poor computational performance, taking ~3.5 mins to run on CPU (Core i5 desktop) and ~1.5 mins to run on GPU (NVIDIA gtx 970).
y, sr = torchaudio.load(demo_sample)
num_mels = 80
n_fft = 2048
hop = hop = int(12.5 * sr * 10**-3)
spectrogram = torchaudio.transforms.Spectrogram(n_fft, hop_length=hop, power=2., normalized=True)
s = spectrogram(y)
mel_scale = torchaudio.transforms.MelScale(num_mels, sr, n_stft=n_fft // 2 + 1)
mel = mel_scale(s)
estimated_spect = inverse_mel_scale(mel)
I think one problem is that the default value for tolerance_loss in InverseMelScale is a hardcoded constant. This causes issues when the range of values within the input mel spect vary. In my case here, this tolerance is never met, resulting in very long runtimes.
It seems it is necessary to tune these hyperparameters to a specific input. If so, it would be useful if the documentation described (with an example) the kind of input the InverseMelScale transform is designed for (e.g. whether to normalise, whether to use AmplitudeToDB and with which parameters.)
This all caused me to look at the code for InverseMelScale and I have thought maybe there is a better way it could work...
We have the filter bank transformation matrix as defined above in mel_scale.fb.
Calling this filter bank matrix F and the spectrogram s we have
F s = mel
This summarises the MelScale function. To invert this we can come up with an approximate inverse of the F matrix, F^+ (the Moore-Penrose pseudo inverse of F https://en.wikipedia.org/wiki/Moore%E2%80%93Penrose_inverse) such that
F^+ mel ≈ s
In code this looks like
F = mel_scale.fb.transpose(0,1)
F_plus = F.pinverse()
s_est = torch.matmul(F_plus, mel)
This pinverse() operation is efficient, and only needs to be performed once. All future inverse mel scale operations then become simple (differentiable!) matrix multiplications. I believe this will necessarily yield minimal MSE performance for a linear operation.
This approach is equivalent to
s_est2, other = torch.lstsq(mel, F)
which is similar to that used by librosa https://librosa.org/doc/main/_modules/librosa/feature/inverse.html#mel_to_stft
Hovwever, using lstsq means that 1. batching etc isn't supported 2. performing this operation multiple times is less efficient than caching a inverse matrix and reusing it.
I hope this makes sense, I apologise for any misunderstandings I may have made (and that I can't render equations properly in github markdown).
I would appreciate if you could share how InverseMelScale is designed to be used. I could then benchmark this against the new method. If you are interested in the new, pseudo inverse, method, I could submit a pull request. I have coded it up here https://github.com/pytorch/audio/compare/master...jacobjwebber:inverseMelScale_fix?expand=1 This would require changing the interface, as 'max_iter', 'tolerance_loss', 'tolerance_change' and 'sgdargs' would no longer be required. It would be good to add a unit test for InverseMelScale, which could also function as an example.
Thanks to all who are working on this wonderful torchaudio library!!
Hi @jacobjwebber
So I worked on #448, but it was my onboarding task and I just followed the previous PR #336.
This all caused me to look at the code for InverseMelScale and I have thought maybe there is a better way it could work...
Is the inverse approach you mentioned covered in #336?
In the discussion of #336, the SVD approach could lead to a poor result, so it was removed from the consideration. However, since there is no clear winning approach, I think we can have a discussion here with your expertise, and reconsider the approach.
I think one problem is that the default value for
tolerance_lossin InverseMelScale is a hardcoded constant. This causes issues when the range of values within the input mel spect vary. In my case here, this tolerance is never met, resulting in very long runtimes.It seems it is necessary to tune these hyperparameters to a specific input. If so, it would be useful if the documentation described (with an example) the kind of input the InverseMelScale transform is designed for (e.g. whether to normalise, whether to use AmplitudeToDB and with which parameters.)
I will let @vincentqb (and @jaeyeun97 if you are still around), respond this one.
Hi! Is #336 the correct issue? It seems to be about delta features.
Yes, my suspicion was that a pseudo inverse might be unstable (even compared to the torch.lstsq optimization approach), but it works surprisingly well. See plots from below. There is noise at the very top of the spectrum, which is where there is no information retained in the mel.
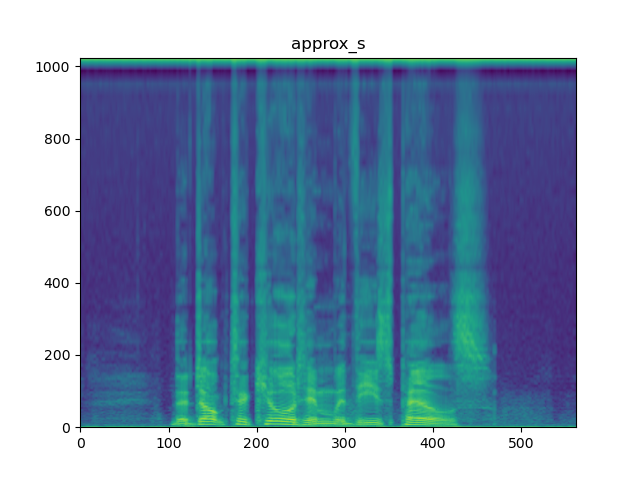
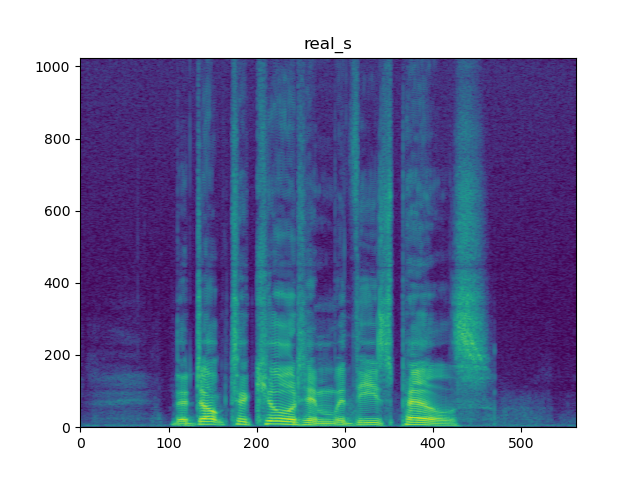
This area defaults to zero as you can see from the slice below
plt.plot(s_est[:,55])
plt.plot(s[0,:,55])
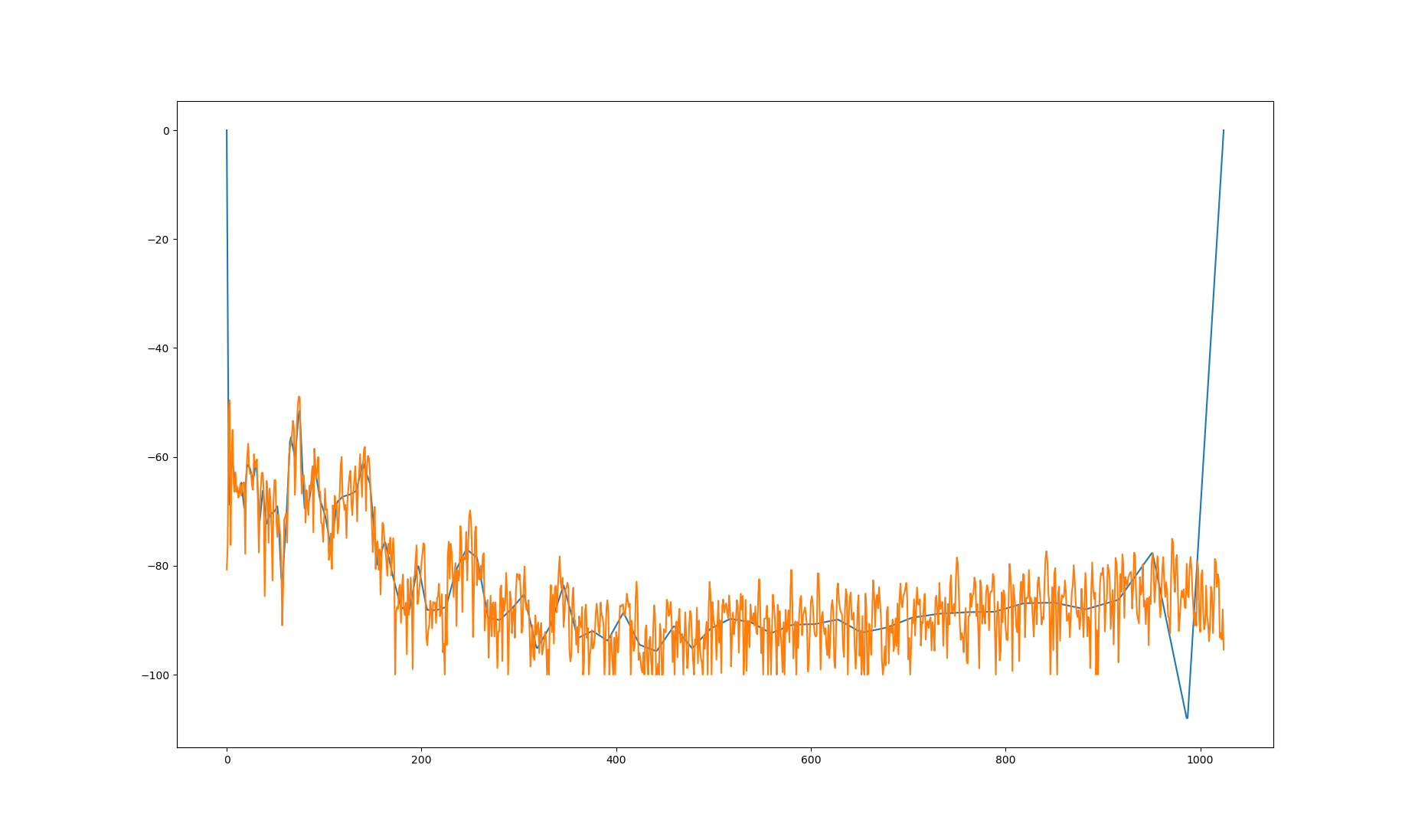
Please forgive the poor, unlabelled plots. I was just trying to convince myself this was working.
Hey, checkout out the original issue #366 and the gist mentioned there to see the difference between the SVD implementation and the SGD one. For higher freq. resolution SVD seems to degrade in performance significantly.
Hovwever, using lstsq means that 1. batching etc isn't supported 2. performing this operation multiple times is less efficient than caching a inverse matrix and reusing it.
Now batching is supported using torch.linalg.lstsq FYI.