Intern CassandraServer instances
General
Before this PR:
ImmutableCassandraServer instances are created and used as Set elements & Map keys heavily, and would benefit from canonicalizing as there should be a relatively small, generally fixed number of Cassandra servers.
After this PR:
Follow on to #6065 to reduce the number of live CassandraServer instances and simplify equals checks to identity equality.
==COMMIT_MSG==
Intern CassandraServer instances
Weakly intern instances as there should be a relatively small, generally fixed number of Cassandra servers. ==COMMIT_MSG==
Priority:
Concerns / possible downsides (what feedback would you like?):
Is documentation needed?:
Compatibility
Does this PR create any API breaks (e.g. at the Java or HTTP layers) - if so, do we have compatibility?:
Does this PR change the persisted format of any data - if so, do we have forward and backward compatibility?:
The code in this PR may be part of a blue-green deploy. Can upgrades from previous versions safely coexist? (Consider restarts of blue or green nodes.):
Does this PR rely on statements being true about other products at a deployment - if so, do we have correct product dependencies on these products (or other ways of verifying that these statements are true)?:
Does this PR need a schema migration?
Testing and Correctness
What, if any, assumptions are made about the current state of the world? If they change over time, how will we find out?:
What was existing testing like? What have you done to improve it?:
If this PR contains complex concurrent or asynchronous code, is it correct? The onus is on the PR writer to demonstrate this.:
If this PR involves acquiring locks or other shared resources, how do we ensure that these are always released?:
Execution
How would I tell this PR works in production? (Metrics, logs, etc.):
Has the safety of all log arguments been decided correctly?:
Will this change significantly affect our spending on metrics or logs?:
How would I tell that this PR does not work in production? (monitors, etc.):
If this PR does not work as expected, how do I fix that state? Would rollback be straightforward?:
If the above plan is more complex than “recall and rollback”, please tag the support PoC here (if it is the end of the week, tag both the current and next PoC):
Scale
Would this PR be expected to pose a risk at scale? Think of the shopping product at our largest stack.:
Would this PR be expected to perform a large number of database calls, and/or expensive database calls (e.g., row range scans, concurrent CAS)?:
Would this PR ever, with time and scale, become the wrong thing to do - and if so, how would we know that we need to do something differently?:
Development Process
Where should we start reviewing?:
If this PR is in excess of 500 lines excluding versions lock-files, why does it not make sense to split it?:
Please tag any other people who should be aware of this PR: @jeremyk-91 @sverma30 @raiju
Generate changelog in changelog/@unreleased
changelog/@unreleasedType
See change types. Select one:
- [ ] Feature
- [x] Improvement
- [ ] Fix
- [ ] Break
- [ ] Deprecation
- [ ] Manual task
- [ ] Migration
Description
Weakly intern instances as there should be a relatively small, generally fixed number of Cassandra servers.
Check the box to generate changelog(s)
- [x] Generate changelog entry
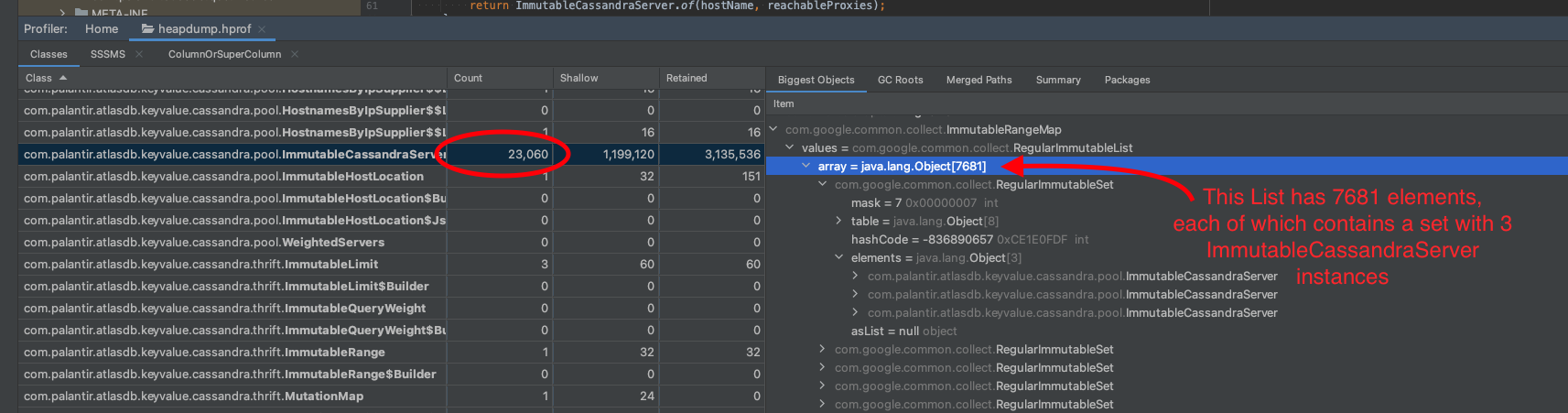
Big +1 to this.
As a concrete example, here's an heap dump from an OOM of one of our highest volume services. We have 23,000 instances of ImmutableCassandraServer.