cmc-csci181
 cmc-csci181 copied to clipboard
cmc-csci181 copied to clipboard
RuntimeError: shape '[1]' is invalid for input of size 128
This is what my code looks like during training
# training step
# update to have two outputs
output_class,output_nextchars = model(line_tensor)
# predicted class vs actual class
print('out_class.shape=', output_class.shape)
print('category_tensor.shape=', category_tensor.shape)
loss_class = criterion(output_class, category_tensor)
loss_nextchars_perchar = torch.zeros(output_nextchars.shape[0])
for i in range(output_nextchars.shape[0] - 1):
print('out_nextchars.shape=', output_nextchars.shape)
print('line_tensor.shape=', line_tensor.shape)
print('out_nextchars[i,:].shape=', output_nextchars[i,:].shape)
print('line_tensor[i+1,:].shape=', line_tensor[i+1,:].shape)
_, nextchar_i = line_tensor[i+1,:].topk(1)
print('nextchar_i.shape=', nextchar_i.shape)
nextchar_i= nextchar_i.view([1])
loss_nextchars_perchar[i] = criterion(output_nextchars[i,:], nextchar_i)
loss_nextchars = torch.mean(loss_nextchars_perchar)
loss = loss_class + loss_nextchars
loss.backward()
grad_norm = sum([ torch.norm(p.grad)**2 for p in model.parameters() if p.grad is not None])**(1/2)
if args.gradient_clipping:
torch.nn.utils.clip_grad_norm_(model.parameters(),1.0)
optimizer.step()
and the output
out_class.shape= torch.Size([128, 18])
category_tensor.shape= torch.Size([128])
out_nextchars.shape= torch.Size([14, 128, 58])
line_tensor.shape= torch.Size([14, 128, 58])
out_nextchars[i,:].shape= torch.Size([128, 58])
line_tensor[i+1,:].shape= torch.Size([128, 58])
nextchar_i.shape= torch.Size([128, 1])
Traceback (most recent call last):
File "names.py", line 252, in <module>
nextchar_i= nextchar_i.view([1])
RuntimeError: shape '[1]' is invalid for input of size 128
by changing the line
nextchar_i= nextchar_i.view([1])
to
nextchar_i= nextchar_i.view([128])
the error went away, but, when I run my code my loss seems very high and the accuracy very low. \t
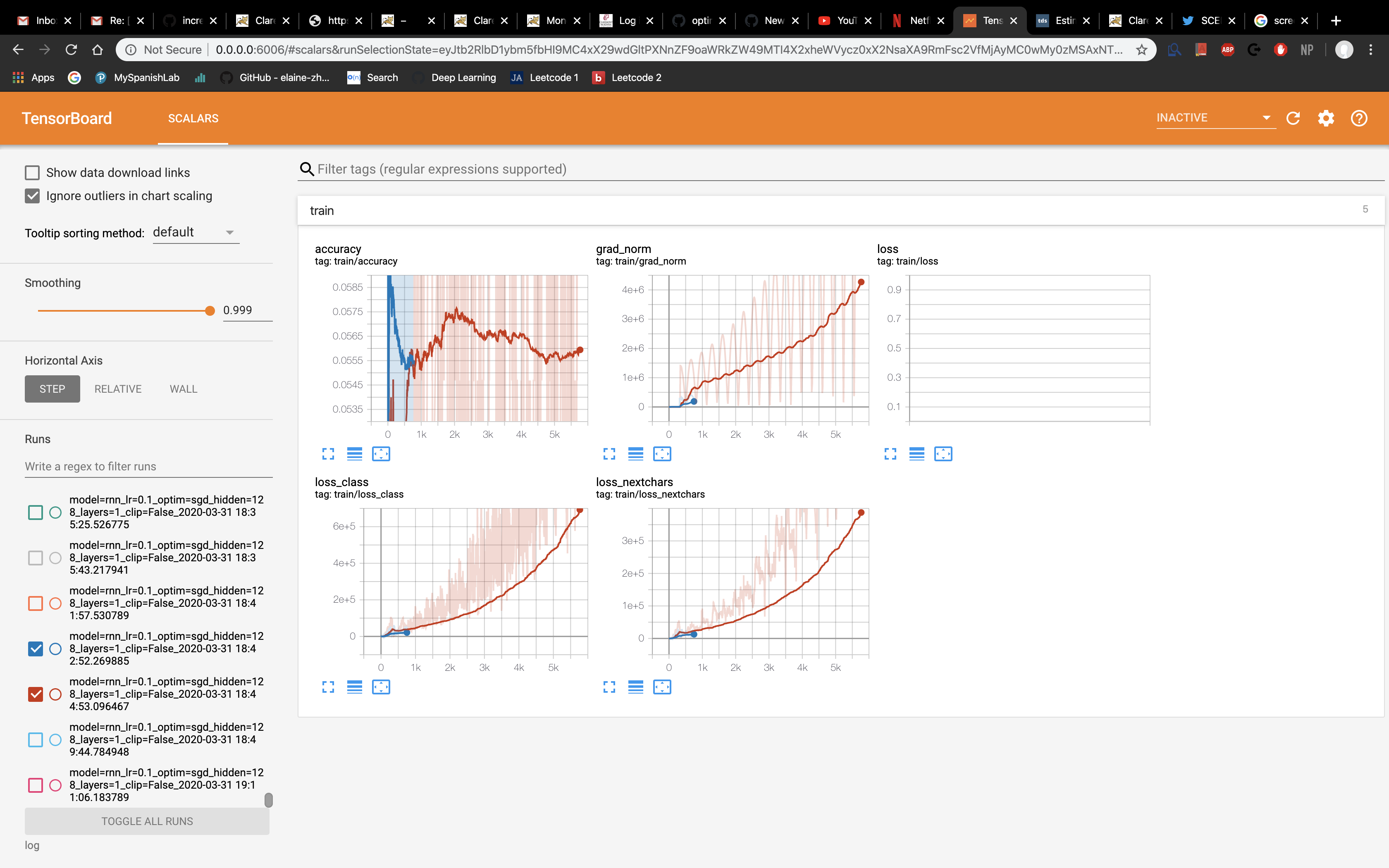
I was wondering what would be the best way to go about solving this problem.
Here is my model code:
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
if args.model == 'gru':
self.rnn = nn.GRU(len(vocabulary), args.hidden_layer_size, args.num_layers)
if args.model == 'lstm':
self.rnn = nn.LSTM(len(vocabulary), args.hidden_layer_size, args.num_layers)
if args.model == 'rnn':
self.rnn = nn.RNN(len(vocabulary), args.hidden_layer_size, args.num_layers)
# linear layer for predicting class
self.fc_class = nn.Linear(args.hidden_layer_size,len(all_categories))
# second linear layer for predicting next chars
self.fc_nextchars = nn.Linear(args.hidden_layer_size, len(vocabulary))
def forward(self, x):
# out is a 3rd order : len of line, batch size, hidden layer size
out,h_n = self.rnn(x)
out_class = self.fc_class(out[out.shape[0]-1,:,:])
out_nextchars = torch.zeros(out.shape[0], out.shape[1], len(vocabulary) )
for i in range(out.shape[0]):
out_nextchars[i,:,:] = self.fc_nextchars(out[i,:,:])
return out_class, out_nextchars
The error is occurring on this line:
nextchar_i= nextchar_i.view([1])
and what the error is saying is that you are trying to change the shape of nextchar_i to [1], but nextchar_i has 128 elements inside of it, so you can't do that. My guess is that the size of 128 is coming because you using a batch size of 128.
To fix this, we need to dynamically figure out the size of nextchar_i and use that instead of 1. One way to do this is to loop over every element in nextchar_i.shape and multiply them together (although there are many other methods to do this as well).