Why the MoE layer forces the input hidden dimenstion the same as the output hidden dimension?
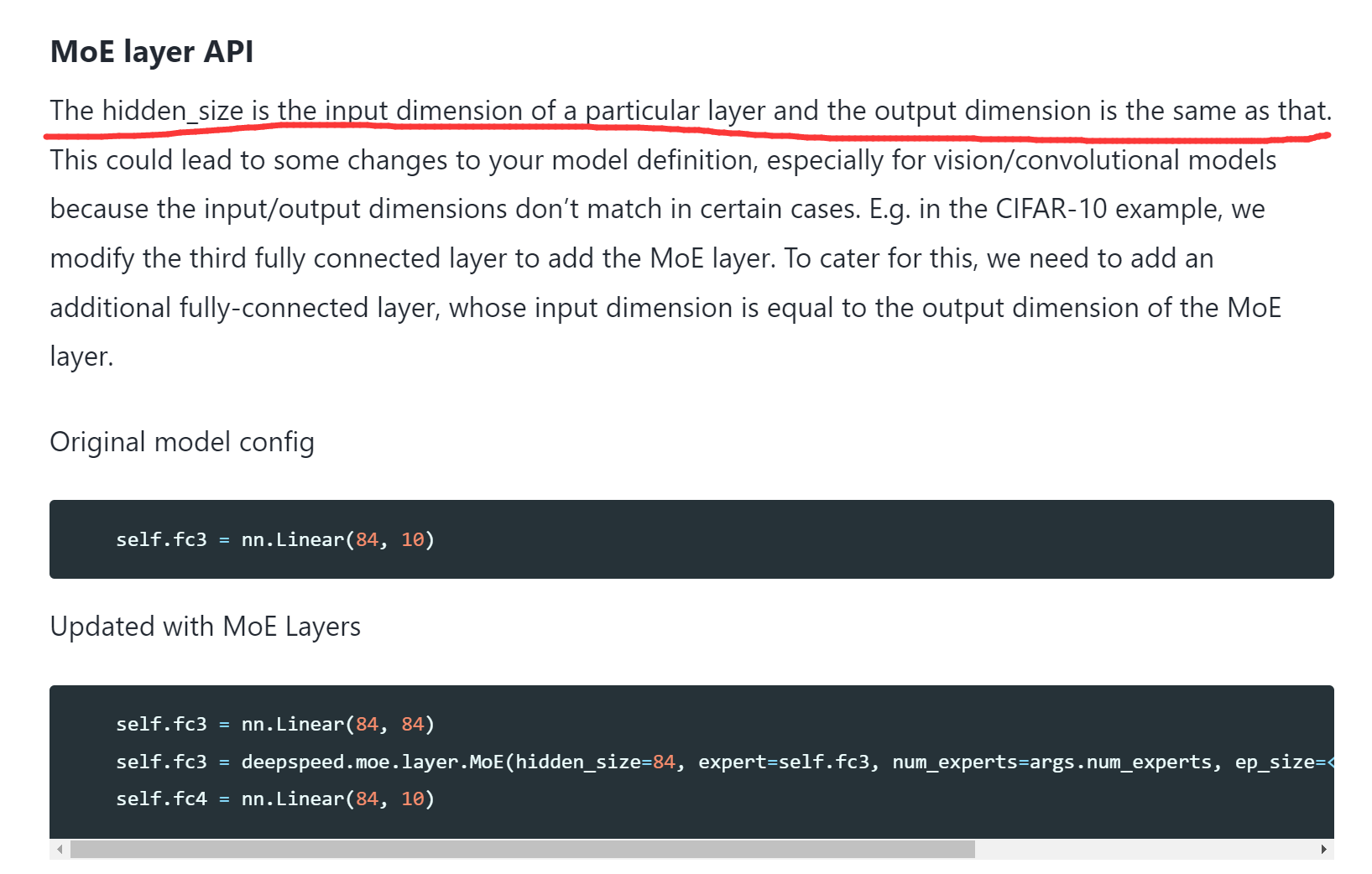 I notice a problem when I read the tutorial of MoE. As the figure shows, it says the input dimension must be equal to the output dimension. This absolutely imports complexity for many DNNs, and I don't understand why this is necessary. In my view, the output dimension is supposed to be easily set at will?
I notice a problem when I read the tutorial of MoE. As the figure shows, it says the input dimension must be equal to the output dimension. This absolutely imports complexity for many DNNs, and I don't understand why this is necessary. In my view, the output dimension is supposed to be easily set at will?
@ykim362 -- I know its a very old issue but do you mind explaining this here?
I think this is because the initial implementation is based on the NLP applications following GShard and Switch. We have a certain tensor dimension assumption - batch, sequence length at the beginning of input tensors.
Hi,
I have fixed this issue in this PR https://github.com/microsoft/DeepSpeed/pull/2530/files.