marian-dev
 marian-dev copied to clipboard
marian-dev copied to clipboard
Flexible learning rate/beta specification
In a conversation with @frankseide a while ago, he suggested hyperparameters should normalize out size.
In other words: lr_decay: schedule decay as a function of the number of words w processed, not epochs lr = |words| * x B_1 = y^{|words|} B_2 = z^{|words|} Where |words| is target side words in the minibatch (not just the average for the epoch). Which is batch flexible learning rate and beta too.
@afaji has some nice plots agreeing with this position empirically.
The question is how the user should specify this. In an ideal world I would argue, albeit with not much backup, that w x y and z (with better names) should be specified as they are more likely to be constants across training runs.
But users are used to specifying learning rate etc at points per batch. This results in some "scaling factor" size that they meant the parameters were appropriate for. Then it seems that the scaling factor should be extracted automatically. But I would argue it shouldn't be, as this is really just the user expressing that their hyperparameters are appropriate for that batch size.
Question is what is the right way to specify this on the command line.
Some experiments: Originally we cannot train transformer on async SGD (0.0 BLEU). But if we assume that the average words per batch in sync SGD is 4x larger compared to the async (under 4 GPUs), we can scale the hyperparams as follow:
- LR: 0.000075 (0.0003 on sync baseline)
- Adams B1 and B2: 0.975 and 0.995 (0.9 & 0.98 on sync baseline)
- lr-decay-freq: 200000 (50k on sync baseline)
- lr-decay-inv-sqrt: 64000 (16k on sync baseline)
- lr-warmup: 64000 (16k on sync baseline)
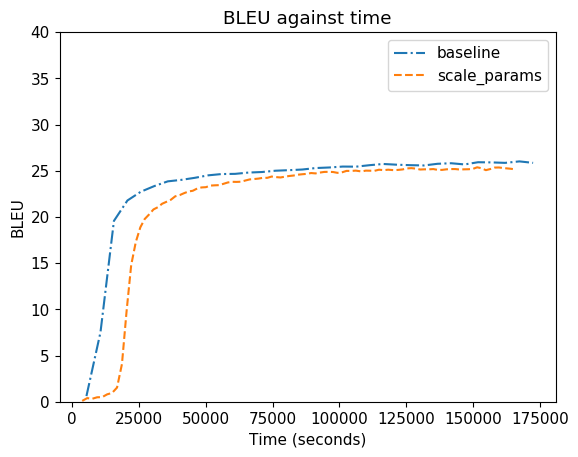
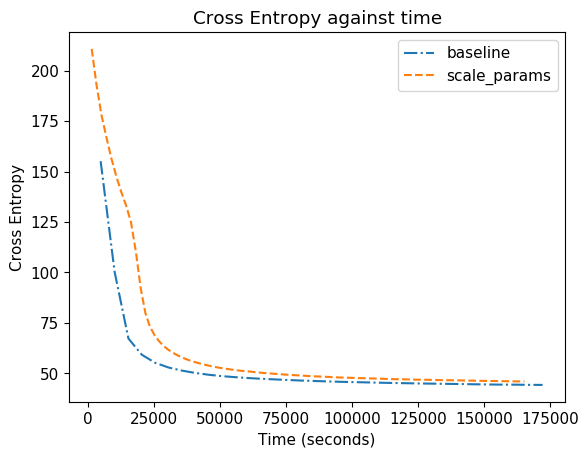
We can train transformer on async. Not as good as sync (maybe transformer is more sensitive to staleness?), but it is a great improvement from nothing.
I have a similar result with best-deep, but in best-deep case, async sgd works as good as sync sgd after tuning the hyperparams. (It was -1 BLEU without tuning).
What is the right way to specify this on the command line
Currently we can set --batch-normal-words. I think the easiest way both for us and users is just scale things based on that:
Right now if we apply --batch-flexible-lr, we adjust the LR as:
LR = base_LR *(|words| / batch_normal_words)
So we can apply the others as well, i.e.:
B1 = base_B1 ^ (|words| / batch_normal_words) B1 = base_B2 ^ (|words| / batch_normal_words)
We should be able to adjust the decay similarly as well.
So users just have to define the batch_normal_words and specify which hyperparams that wanted to be scaled.