FastChat
 FastChat copied to clipboard
FastChat copied to clipboard
NETWORK ERROR DUE TO HIGH TRAFFIC. PLEASE REGENERATE OR REFRESH THIS PAGE. (error_code: 4)
When i start a conversation it always shows:NETWORK ERROR DUE TO HIGH TRAFFIC. PLEASE REGENERATE OR REFRESH THIS PAGE. (error_code: 4)
How can I solve this ?
thank you!
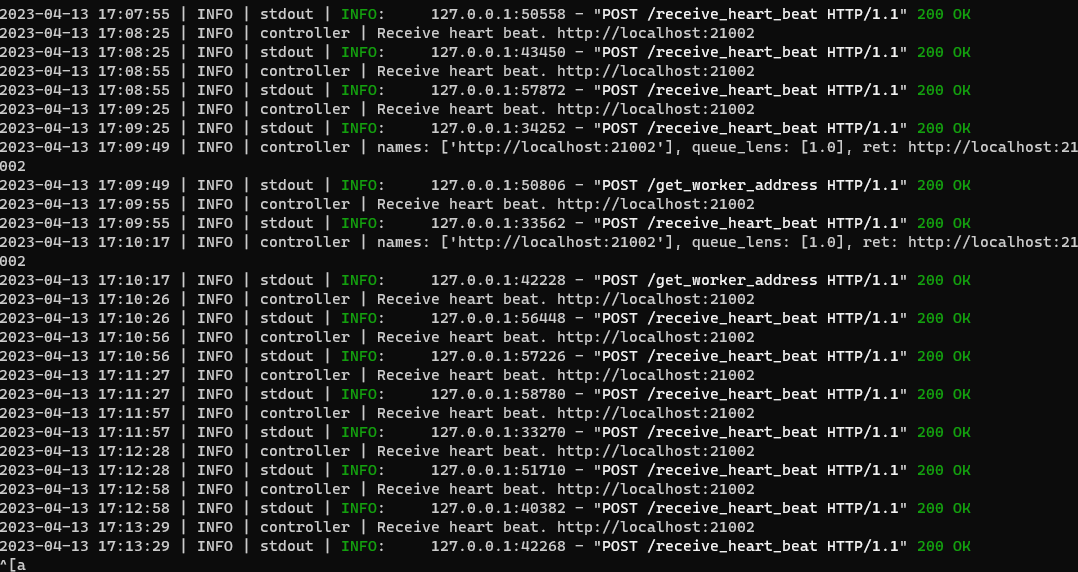
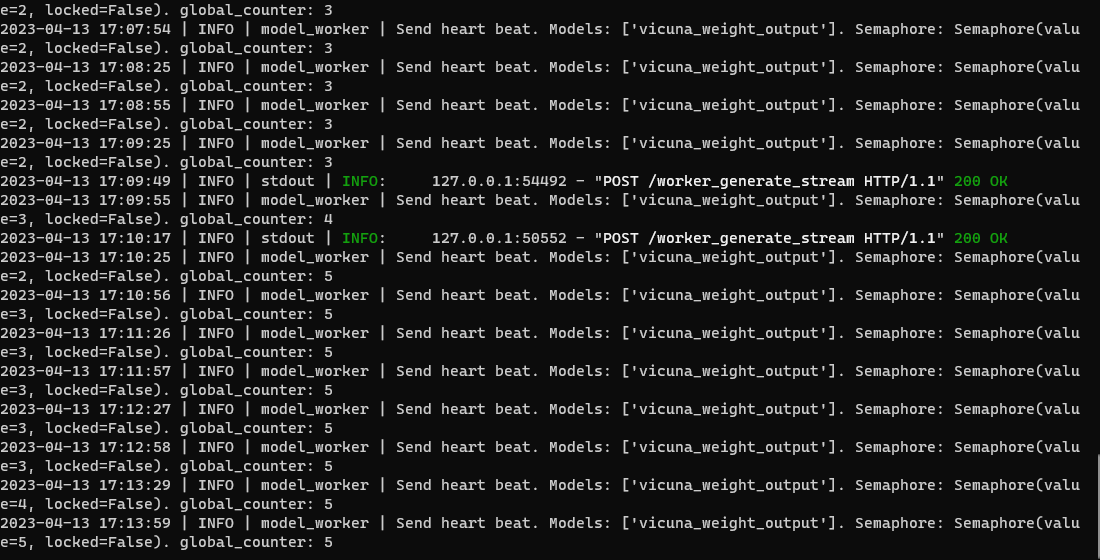
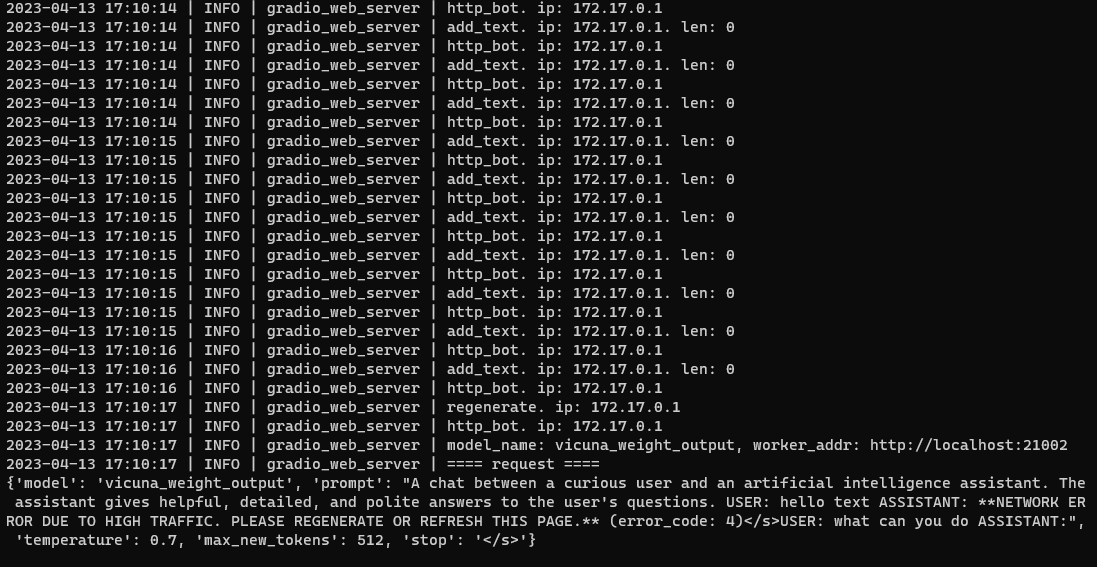
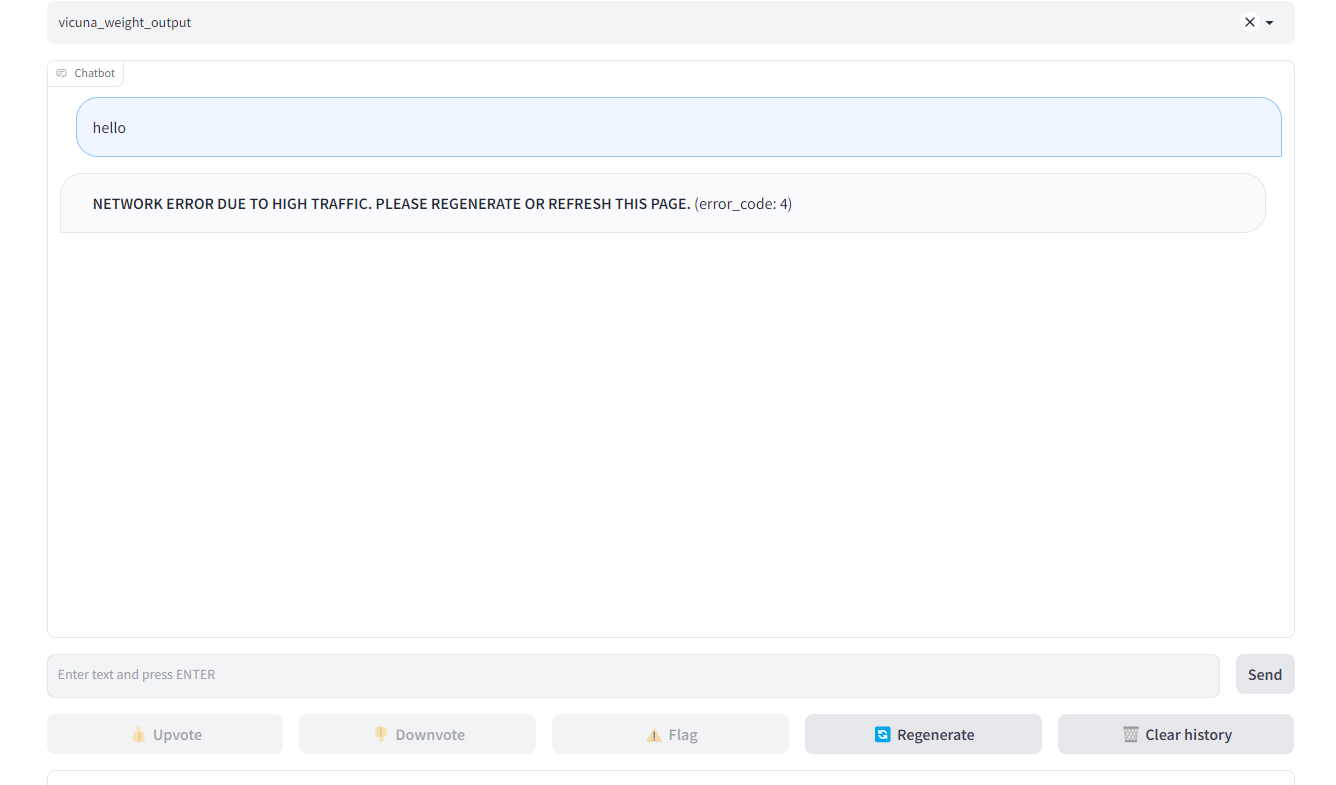
Same error. Running in cli mode works fine. I think this is a bug in controller or worker or gui.
Seems need to wait for model_worker to start, then you can start webui.
something like this bat script
start "" python -m fastchat.serve.controller --host 0.0.0.0
timeout 5
start "" python -m fastchat.serve.model_worker --model-path C:\model\LanguageModel\vicuna-13b-1.1 --load-8bit
timeout 10
start "" python -m fastchat.serve.gradio_web_server --host 0.0.0.0
start "" http://localhost:7860
for linux
# server
nohup python3 -m fastchat.serve.controller >> /root/server.log 2>&1 &
while [ `grep -c "Uvicorn running on" /root/server.log` -eq '0' ];do
sleep 1s;
echo "wait server running"
done
echo "server running"
# worker
nohup python3 -m fastchat.serve.model_worker --model-name 'vicuna-7b-v1.1' --model-path /data/vicuna-7b >> /root/worker.log 2>&1 &
while [ `grep -c "Uvicorn running on" /root/worker.log` -eq '0' ];do
sleep 1s;
echo "wait worker running"
done
echo "worker running"
# webui
python3 -m fastchat.serve.gradio_web_server
the same error on my macbook with 16Gram and M1pro. It works fine at first and there are some answer words, but if the answer is more than a certain number of words like 100 then this error occurs
It's error code based. Not readable tbh, had to prefix that error in gradio, controller and worker to see which component throws.
- error code 4, something wrong with worker (or communication with worker?) https://github.com/lm-sys/FastChat/blob/main/fastchat/serve/gradio_web_server.py#L296
- error code 1, out of memory https://github.com/lm-sys/FastChat/blob/main/fastchat/serve/model_worker.py#L180-L183
The problem is that the service only listens on localhost, so it rejects requests from others
- just add host listening on 0.0.0.0
python -m fastchat.serve.controller --host 0.0.0.0
sleep 5
python -m fastchat.serve.model_worker --model-name 'vicuna-7b-v1.1' --model-path xxx
sleep 5
python -m fastchat.serve.gradio_web_server --host 0.0.0.0
A DB-GPT Experiment Project Based ON FastChat
I post a demo project, which based on langchain and vicuna-13b, vicuna-13b is really cool. My project is there: https://github.com/csunny/DB-GPT
Folks -- this issue is likely caused because you are using a script to set up the three processes -- worker, controller, and web server.
As @gujingit showed, if you do not wait for the worker to set up, the registration of the worker to the controller will fail. And the requests sent by the web server won't go through because there is no active worker.
Please note that the worker setup takes time (many seconds, depending on your disk speed) as it needs to load 7B or 13B weights from the disk.
@gujingit's script will solve the problem because that script follows the correct setup order, And it will wait for the worker to load model weights before starting the web server, and before you can send requests.
Closing the issue now. Please re-open if you still face the issue even if you follow what I said to diganose the issue.
@zhisbug well you just described a bug. Are you saying it should be ignored? :) Why order of running things matters when you have full control over the code and it can be actually fixed?
@krzysztofantczak No, we do not have control of your (and other users') launching script. We never provided such a launching script. If you follow strictly our instructions on how to launch the web server, you won't see this issue.
@zhisbug I think you missed my point here. There is absolutely no reason for UI to not receive an event from controller that model is ready (or crashed for that matter - it can auto-heal then). Users or their scripts have nothing to do with it. In other words, timing issues or requiring specific order of running services with no reason is bad design, not user fault.
@zhisbug I think you missed my point here. There is absolutely no reason for UI to not receive an event from controller that model is ready (or crashed for that matter - it can auto-heal then). Users or their scripts have nothing to do with it. In other words, timing issues or requiring specific order of running services with no reason is bad design, not user fault.
How about you submit a PR to improve it with your better design? Me and @merrymercy can help review (though there are some other considerations that we can discuss later)
Just make sure that gradio_web_server starts after model_worker registers model to controller. Check the model registering history in model_worker_xxx.log.
Nothing to do with local ip address or anything else.
@zhisbug Thank you for explanation! I have one question, what is the point of separating the services on worker, controller and ui, if they need strict order of starting? This defeats the whole purpose of having multiple services.
A poor try-except logic in my case
If it's not an issue of execution order of scripts, it might be a similar situation to mine. I recommend first identifying where this error message is from. In my case it's in the "model_worker.py":
def generate_stream_gate(self, params):
try:
device = params['device'] if 'device' in params else self.device
for output in generate_stream(
self.model,
params['text'],
params['image'],
device,
args.keep_in_device
):
ret = {
"text": output,
"error_code": 0,
}
yield json.dumps(ret).encode() + b"\0"
except Exception as e:
ret = {
"text": server_error_msg, #
NETWORK ERROR DUE TO HIGH TRAFFIC. PLEASE REGENERATE OR REFRESH THIS PAGE.
"error_code": 1,
}
yield json.dumps(ret).encode() + b"\0"
The exception handling here was too simplistic. When I modified it to print out the exception (by adding print(e) in the except part), the error was as follows:
2024-07-02 10:27:00 | INFO | stdout | >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
2024-07-02 10:27:00 | ERROR | stderr | Traceback (most recent call last):
2024-07-02 10:27:00 | ERROR | stderr | File "/home/root/Exp2/test/Multi-Modality-Arena-main/model_worker.py", line 133, in generate_stream_gate
2024-07-02 10:27:00 | ERROR | stderr | for output in generate_stream(
2024-07-02 10:27:00 | ERROR | stderr | File "/home/root/anaconda3/envs/llava_demo/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 35, in generator_context
2024-07-02 10:27:00 | ERROR | stderr | response = gen.send(None)
2024-07-02 10:27:00 | ERROR | stderr | File "/home/root/Exp2/test/Multi-Modality-Arena-main/peng_utils/__init__.py", line 74, in generate_stream
2024-07-02 10:27:00 | ERROR | stderr | output = model.generate(image, text, device, keep_in_device)
2024-07-02 10:27:00 | ERROR | stderr | File "/home/root/anaconda3/envs/llava_demo/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
2024-07-02 10:27:00 | ERROR | stderr | return func(*args, **kwargs)
2024-07-02 10:27:00 | ERROR | stderr | TypeError: TestLLaVA.generate() takes 3 positional arguments but 5 were given
Obviously, it was a problem about passing parameters. All I needed was to adjust the corresponding parts based on the exception.
Note I encountered this issue while trying to replicate Multi-Modality-Arena, which is based on FastChat.