benchmarks
 benchmarks copied to clipboard
benchmarks copied to clipboard
Optimize the V version of the BF interpreter.
V does bounds checking by default on each array access.
Using [direct_array_access] over a function/method, disables the checks inside its body.
The brainfuck implementation does call very frequently the methods .get() and .inc() , which boil down to array access operations.
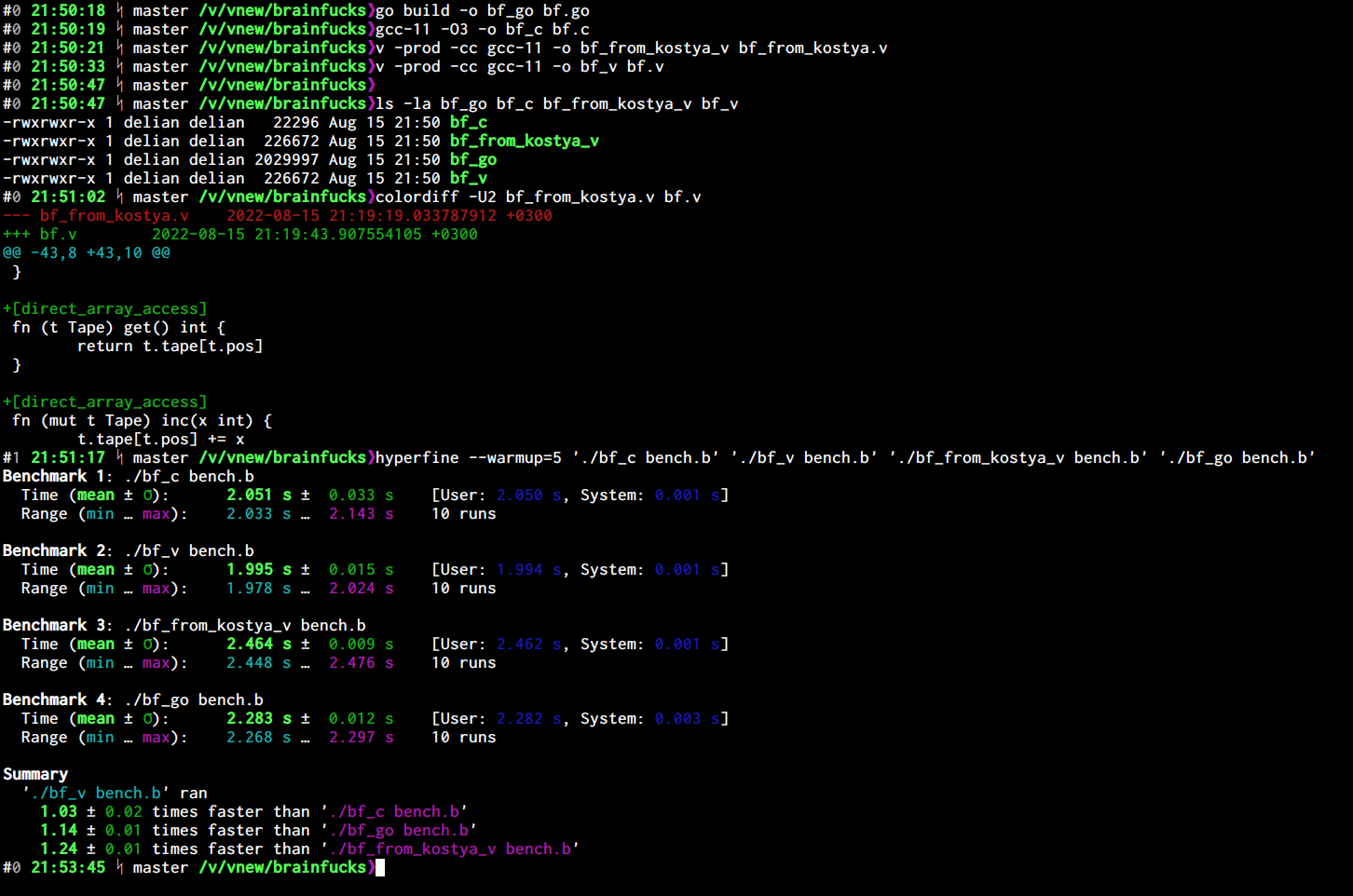
With this change, the V implementation is within 5% of the C version, when it is compiled with -prod (and the C version is compiled with -O3) on my machine.
Related: https://github.com/kostya/benchmarks/issues/312#issuecomment-918371330
Here is a small comparison between the version before, and the version after (bf_v), vs the C and the Go versions:
Sorry, those changes are micro-optimizations, and ideally could be provided by the compiler itself:
[direct_array_access]could be enabled for all array operations if V lang would have the special compiler flag for that (likedangerin Nim: https://nim-lang.org/docs/nimc.html#additional-compilation-switches)- appending an array vs appending an element performance seems like a compiler issue too as it's not an expected behaviour.
Please note that we don't compare top performance here, but rather the performance of the code written by the average software developer, and it's unlikely that they use constructions like [direct_array_access] in the usual code.
These constructs are actually encouraged and shared to regular developers @nuald as occasion necessitates. I'm sure there could be a lot more discussion on this topic so please feel free to pop on into Discord for further discussion: https://discord.gg/vlang
May be obsoleted by https://github.com/kostya/benchmarks/pull/431 , which will also benefit other V programs in this benchmark suite.