diart
 diart copied to clipboard
diart copied to clipboard
microphone in conda enviroment
hi @juanmc2005 it's me again, trouble maker QAQ
I have a problem when using "diart.stream microphone" in the conda env "diart"
i follow the install step
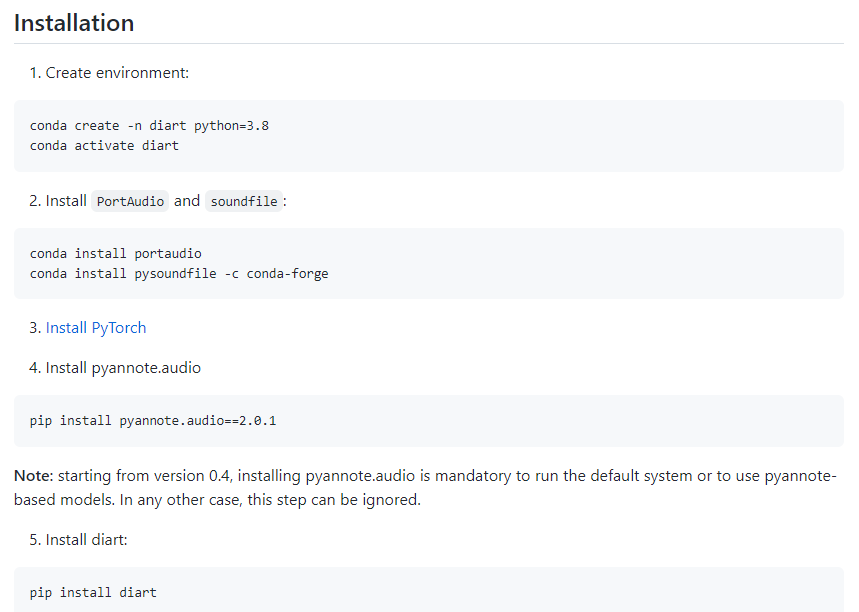
when I connect the microphone or Logitech webcam(with mic), the ubuntu os can detect the sound from the mic but the conda environment can't see and get the sound signal from the mic when i use "diart.stream microphone", it can't find the sound when i run like sounddevice.py in the original environment(i.e not in conda), the mic device can be detected and can obtain the audio signal
I have thought that i just install the package in the original environment, but some package like portaudio, can't install
SO, i want to ask for some suggestion What should i do to use "diart.stream microphone" usefully in the conda environment? Or the Ubuntu version effect? Or i need to do some special setting??
Sorry for bothering you
For information I build the conda environment in the NVIDIA nano board with ubuntu 20.04 LTS
Hi @Shoawen0213,
Currently, the class MicrophoneAudioSource reads from the default microphone automatically.
You make a very good point, I would like the user to be able to select the device.
In sounddevice, you need to set the value device to the selected microphone's ID. You can query available IDs with python -m sounddevice.
I'd like to add a device parameter to __init__ so that we can set this in the sounddevice.InputStream here (sd.InputStream(..., device=device)).
Would you be willing to open a PR for this? It would help a lot!
Hi @juanmc2005
Thanks for your reply!
I found that the problem might be the conda use for NVIDIA nano board is called "archiconda"
The missing sound problem might be caused by using the "archiconda"
When I change to use the anaconda in the windows OS system, the sound from the mic can be detected
of course, but how to open a PR, and what should i do? sorry for this stupid question
Did you manage to read the microphone stream from diart without modifying the code?
To open a PR, you need to fork diart, create a new branch from develop, make changes to the code, push them and then create a pull request to this repo.
hi @juanmc2005 I use it directly without modifying the code i remember. But I will try again and test several times, then tell you the testing result!! I search the setting of sounddevice.py, it seems that it can be set with a given parameter like ID or something else I will PR this after I finish testing!! Thanks for your teaching!
BTW these days I thought a question, if u have time i would like to know your suggestion the problem is that how to measure the diart system parameter size? i know that when fine-tuning the segmentation model, the terminal will show that 5.890 (MB) is the total estimated params size, it means the size of the segmentation right? but how about the embedding model and the whole diart model? I have this question is because several papers mentioned that the self-attention-based model for speaker diarization needs a large parameter size (actually i aslo curious how large it is ), and the hybrid way can have a smaller one. That's why I would like to know. Sorry for bothering u!!
You can measure the parameter size of the diart pipeline by adding the sizes of the different models involved.
For the segmentation and embedding models you can use any method for PyTorch's nn.Module.
For OnlineSpeakerClustering you should calculate the size of the speaker centroid matrix, this would be num_global_speakers * embedding_dimension.
Also notice that the number of global speakers can grow indefinitely, although diart sets a limit (20 by default).
Hello,
Please allow me to join the discussion as I have a question regarding this. I also implemented an audio card selector to select a virtual alsa card (loopback). The change works on my dev computer but when i use it on my raspberry (with my virtual card), i don't get a good result (speaker log on noise or silence).
The difference betwen my dev audio card and my virtual card is the sample rate (dev= 44K, virtual= 16k).
Have you ever encountered the problem? Should I modify another part of the code to use the virtual card or another sample rate? I have implemented an audio saving to check the input stream (in _read_callback) and the wav file is ok.
Thank you
class MicrophoneAudioSource(AudioSource):
def __init__(self, sample_rate: int):
super().__init__("live_recording", sample_rate)
#print("Rate: ", sample_rate)
currentDeviceIndex = 0
for i, device in enumerate(sd.query_devices()):
print("=> ", device)
if device['name'] == "default":
currentDeviceIndex = i
self.block_size = 1024
self.mic_stream = sd.InputStream(
channels=1,
samplerate=sample_rate,
latency=0,
blocksize=self.block_size,
callback=self._read_callback,
device=currentDeviceIndex
)
self.queue = SimpleQueue()
#self.file = sf.SoundFile("test.wav", mode='x', samplerate=16000, channels=1, subtype='PCM_16')
def _read_callback(self, samples, *args):
self.queue.put_nowait(samples[:, [0]].T)
print("callback")
#self.file.write(samples)
Hi @KentDesreumaux,
What devices are available in your raspberry? I'm guessing the "default" device may be the wrong one.
Also, could you verify what's the input and output of SegmentationModel?
Hi @juanmc2005, Thank you for your reply!
I had problems with the new version of pyannote but now it's ok! My problem is very stange because my audio stream is good and the model have the same framerate,... I had the correct card name from the previous message (default was an example). I print annotations in sinks file (in DiarizationPredictionAccumulator::on_next):
Streaming live_recording: 157chunk [05:11, 2.00s/chunk] Annote: | datetime: 28/11/2022 15:19:37
Streaming live_recording: 158chunk [05:13, 1.99s/chunk] Annote: | datetime: 28/11/2022 15:19:39
Streaming live_recording: 159chunk [05:15, 1.95s/chunk] Annote: [ 00:01:24.041 --> 00:01:24.508] 0 speaker0 | datetime: 28/11/2022 15:19:41
Streaming live_recording: 160chunk [05:17, 1.91s/chunk] Annote: [ 00:01:24.508 --> 00:01:25.008] 0 speaker0 | datetime: 28/11/2022 15:19:42
Streaming live_recording: 161chunk [05:19, 1.89s/chunk] Annote: | datetime: 28/11/2022 15:19:44
Streaming live_recording: 162chunk [05:21, 1.90s/chunk] Annote: [ 00:01:25.508 --> 00:01:26.008] 0 speaker0 | datetime: 28/11/2022 15:19:46
Streaming live_recording: 163chunk [05:23, 1.91s/chunk] Annote: | datetime: 28/11/2022 15:19:48
Streaming live_recording: 164chunk [05:24, 1.89s/chunk] Annote: | datetime: 28/11/2022 15:19:50
Streaming live_recording: 165chunk [05:26, 1.90s/chunk] Annote: | datetime: 28/11/2022 15:19:52
I think there is a high latency because one chunk take 2 seconds and one step take 0.5 second. I'm using a raspberry pi with the cpu to run PyAnnote.
Is this problem is possible?
Thank you :)
Hi @KentDes,
Yes it sounds likely that the system would be much slower on a raspberry pi. The real-time latency should be at most 500ms per chunk to run in real time.
I suggest you profile the code to see what steps of the pipeline are taking longer. If it's the segmentation or embedding inference (most likely), maybe you could try scaling the models down and training them with a distillation loss.
Changing microphone devices is now implemented in #136 and will be part of the next v0.7 release
Hi @juanmc2005, Thank you for your reply!
I had problems with the new version of pyannote but now it's ok! My problem is very stange because my audio stream is good and the model have the same framerate,... I had the correct card name from the previous message (default was an example). I print annotations in sinks file (in DiarizationPredictionAccumulator::on_next):
Streaming live_recording: 157chunk [05:11, 2.00s/chunk] Annote: | datetime: 28/11/2022 15:19:37 Streaming live_recording: 158chunk [05:13, 1.99s/chunk] Annote: | datetime: 28/11/2022 15:19:39 Streaming live_recording: 159chunk [05:15, 1.95s/chunk] Annote: [ 00:01:24.041 --> 00:01:24.508] 0 speaker0 | datetime: 28/11/2022 15:19:41 Streaming live_recording: 160chunk [05:17, 1.91s/chunk] Annote: [ 00:01:24.508 --> 00:01:25.008] 0 speaker0 | datetime: 28/11/2022 15:19:42 Streaming live_recording: 161chunk [05:19, 1.89s/chunk] Annote: | datetime: 28/11/2022 15:19:44 Streaming live_recording: 162chunk [05:21, 1.90s/chunk] Annote: [ 00:01:25.508 --> 00:01:26.008] 0 speaker0 | datetime: 28/11/2022 15:19:46 Streaming live_recording: 163chunk [05:23, 1.91s/chunk] Annote: | datetime: 28/11/2022 15:19:48 Streaming live_recording: 164chunk [05:24, 1.89s/chunk] Annote: | datetime: 28/11/2022 15:19:50 Streaming live_recording: 165chunk [05:26, 1.90s/chunk] Annote: | datetime: 28/11/2022 15:19:52I think there is a high latency because one chunk take 2 seconds and one step take 0.5 second. I'm using a raspberry pi with the cpu to run PyAnnote.
Is this problem is possible?
Thank you :)
Hi @KentDes ,
Would you mind to share your experience about installing diart on rsp? I'm trying to run diart on rsp 4B, but it can't work. I will be appreciated if you would like to share you rsp environment.
Thank you. :-)