pytorch-grad-cam
 pytorch-grad-cam copied to clipboard
pytorch-grad-cam copied to clipboard
batch size for cam results
For batch size N > 1, I used to set targets = [ClassifierOutputTarget(cls)] * N to generate the grayscale_cam with output [N, H, W]
But not sure why, I tried again today and it doesn't work anymore. the grayscale_cam output is always [1, H, W] The input tensor is [N, C, H, W]
Could you please check? In compute_cam_per_layer:
activations_list = [a.cpu().data.numpy()
for a in self.activations_and_grads.activations]
grads_list = [g.cpu().data.numpy()
for g in self.activations_and_grads.gradients]
target_size = self.get_target_width_height(input_tensor)
cam_per_target_layer = []
# Loop over the saliency image from every layer
for i in range(len(self.target_layers)):
target_layer = self.target_layers[i]
layer_activations = None
layer_grads = None
if i < len(activations_list):
layer_activations = activations_list[i]
if i < len(grads_list):
layer_grads = grads_list[i]
cam = self.get_cam_image(input_tensor,
target_layer,
targets,
layer_activations,
layer_grads,
eigen_smooth)
cam = np.maximum(cam, 0)
Even though the grads_list & activation_list are length N, the layer_grads only contain 1 grad as my target_layers is size=1. thus the get_cam_image would only always return 1 cam instead of N
Hi, I tried reproducing it now but it works. I tried using the example in cam.py with resnet, and just repeated the tensor several times.
Maybe print input_tensor.shape to be sure? Can you post more details that might help troubleshoot this? Maybe some snippet to reproduce it?
Hi, I tried reproducing it now but it works. I tried using the example in cam.py with resnet, and just repeated the tensor several times.
Maybe print input_tensor.shape to be sure? Can you post more details that might help troubleshoot this? Maybe some snippet to reproduce it?
Thanks for your quick reply. In my code, I reproduced it like this:
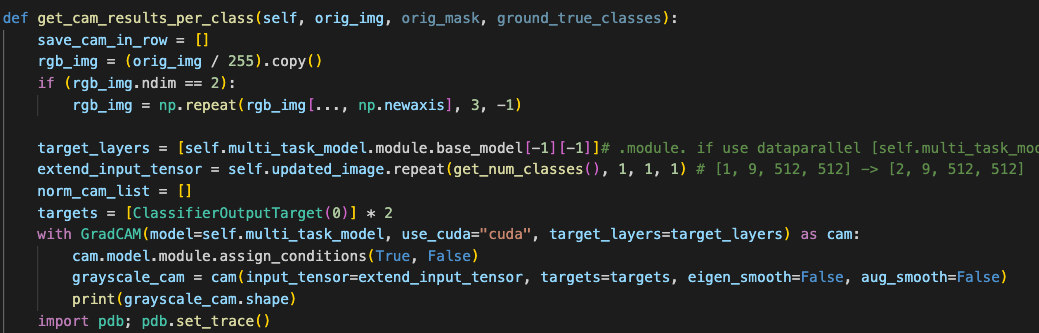
I also logged the some results in base_cam.py/forward() function:
def forward(self,
input_tensor: torch.Tensor,
targets: List[torch.nn.Module],
eigen_smooth: bool = False) -> np.ndarray:
if self.cuda:
input_tensor = input_tensor.cuda()
if self.compute_input_gradient:
input_tensor = torch.autograd.Variable(input_tensor,
requires_grad=True)
import pdb; pdb.set_trace()
outputs = self.activations_and_grads(input_tensor)
if targets is None:
target_categories = np.argmax(outputs.cpu().data.numpy(), axis=-1)
targets = [ClassifierOutputTarget(
category) for category in target_categories]
if self.uses_gradients:
self.model.zero_grad()
loss = sum([target(output)
for target, output in zip(targets, outputs)])
loss.backward(retain_graph=True)
cam_per_layer = self.compute_cam_per_layer(input_tensor,
targets,
eigen_smooth)
import pdb; pdb.set_trace()
return self.aggregate_multi_layers(cam_per_layer)
(Pdb) input_tensor.shape torch.Size([2, 9, 512, 512])
(Pdb) self.activations_and_grads(input_tensor) tensor([[-6.1811, 7.5720, 7.8820], [-6.1811, 7.5720, 7.8820]], device='cuda:0', grad_fn=<GatherBackward>)
(Pdb) targets [<pytorch_grad_cam.utils.model_targets.ClassifierOutputTarget object at 0x7f2058959580>, <pytorch_grad_cam.utils.model_targets.ClassifierOutputTarget object at 0x7f2058959580>]
Both input_tensor and outputs are fine with B, C, H, W However, the later cam_per_layer length becomes 1, with (1, [ 1, 1, 512, 512]) (Pdb) len(cam_per_layer) 1 (Pdb) cam_per_layer[0].shape (1, 1, 512, 512)
is that because I used the DataParallel?
Hey, did you get a chance to look into this? @jacobgil I tested on the simple cases from your repo example with resnet50, and after adding DataParallel, it does return just 1 grayscale_cam. I am still working on how to solve this
Hi i'm traveling right now so can take me another week until I look at this.
Yes I'm 99% sure it's because of DataParallel: https://discuss.pytorch.org/t/using-forward-hook-for-data-parallel-with-multiple-gpus/107970
In DataParallel the hook is called several times since the models are replicated on each device, but I think then every device gets a batch size of 1 here, and an extra dimension somewhere.
When I get back I will try reproducing it with DataParralel.
Hi i'm traveling right now so can take me another week until I look at this.
Yes I'm 99% sure it's because of DataParallel: https://discuss.pytorch.org/t/using-forward-hook-for-data-parallel-with-multiple-gpus/107970
In DataParallel the hook is called several times since the models are replicated on each device, but I think then every device gets a batch size of 1 here, and an extra dimension somewhere.
When I get back I will try reproducing it with DataParralel.
Thanks and have a nice trip!
Hi, I couldn't reproduce it even with DataParralel.
model = models.resnet50(pretrained=True)
model = torch.nn.DataParallel(model)
target_layers = [model.module.layer4]
Can you please post:
- How you're craeting the model.
- The target_layers definition.
Hi, I couldn't reproduce it even with DataParralel.
model = models.resnet50(pretrained=True) model = torch.nn.DataParallel(model) target_layers = [model.module.layer4]Can you please post:
- How you're craeting the model.
- The target_layers definition.
Hey, Let me show the example in README:
from pytorch_grad_cam.utils.image import show_cam_on_image
from torchvision.models import resnet50
import torch.nn as nn
from pytorch_grad_cam.utils.model_targets import ClassifierOutputTarget
model = resnet50(pretrained=True)
model = nn.DataParallel(model)
target_layers = [model.module.layer4[-1]]
input_tensor = torch.rand(2, 3, 512, 512)# Create an input tensor image for your model..
# Note: input_tensor can be a batch tensor with several images!
targets = [ClassifierOutputTarget(281)] * 2
# Construct the CAM object once, and then re-use it on many images:
cam = GradCAM(model=model, target_layers=target_layers, use_cuda='cuda')
# You can also pass aug_smooth=True and eigen_smooth=True, to apply smoothing.
grayscale_cam = cam(input_tensor=input_tensor, targets=targets)
grayscale_cam.shape
The output of grayscale_cam.shape is (1, 512, 512)
If I remove the DataParallel wrapup, the output is correct (2, 512, 512)
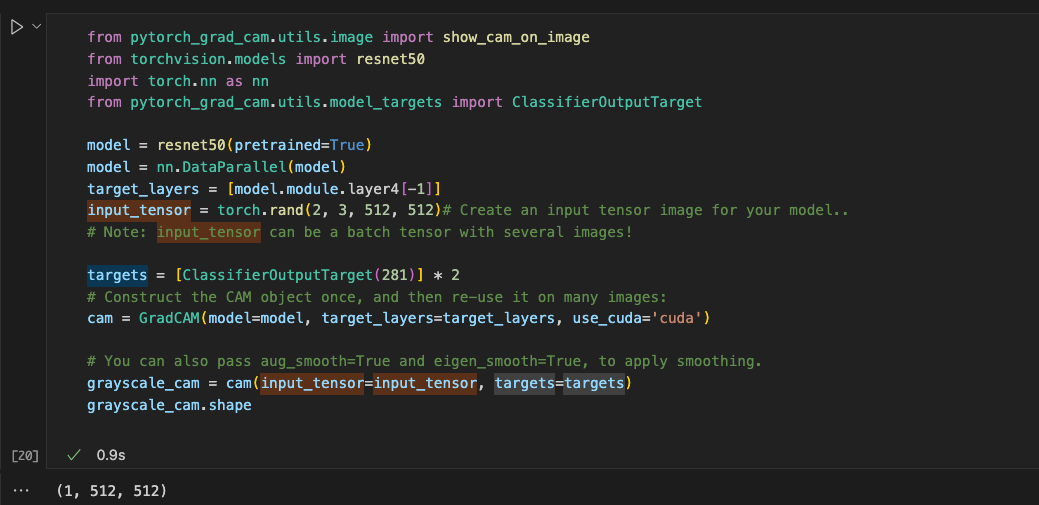
any solutions here? is that because i need to do the GradCAM(model=model.module, xx) ?
I solved it by sending model.module instead of the model that was parallel. Close now.