langchainjs
 langchainjs copied to clipboard
langchainjs copied to clipboard
Improves pdf parsing
The below changes improve upon PDFLoader.parse method. Instead of adding a newline character after every TextItem, we only add a newline if the TextItem has an EOL character. This significantly improves the output text. Attaching an example below -
Before:
Contents
Foreword
iii
Preface
v
1.
Real Numbers
1
1.1
Introduction
1
1.2
Euclid's Division Lemma
2
1.3
The Fundamental Theorem of Arithmetic
7
1.4
Revisiting Irrational Numbers
11
1.5
Revisiting Rational Numbers and Their Decimal Expansions
15
1.6
Summary
After:
Contents
Foreword iii
Preface v
1. Real Numbers 1
1.1 Introduction 1
1.2 Euclid's Division Lemma 2
1.3 The Fundamental Theorem of Arithmetic 7
1.4 Revisiting Irrational Numbers 11
1.5 Revisiting Rational Numbers and Their Decimal Expansions 15
1.6 Summary 18
The latest updates on your projects. Learn more about Vercel for Git ↗︎
| Name | Status | Preview | Updated (UTC) |
|---|---|---|---|
| langchainjs-docs | ✅ Ready (Inspect) | Visit Preview | Apr 22, 2023 6:11pm |
That doesn't seem to generalise to all pdfs, see eg the output for this pdf https://arxiv.org/pdf/1706.03762.pdf

I've committed here the solution used by https://gitlab.com/autokent/pdf-parse, do you want to try on your pdf and see if that's better?
That doesn't seem to generalise to all pdfs, see eg the output for this pdf https://arxiv.org/pdf/1706.03762.pdf
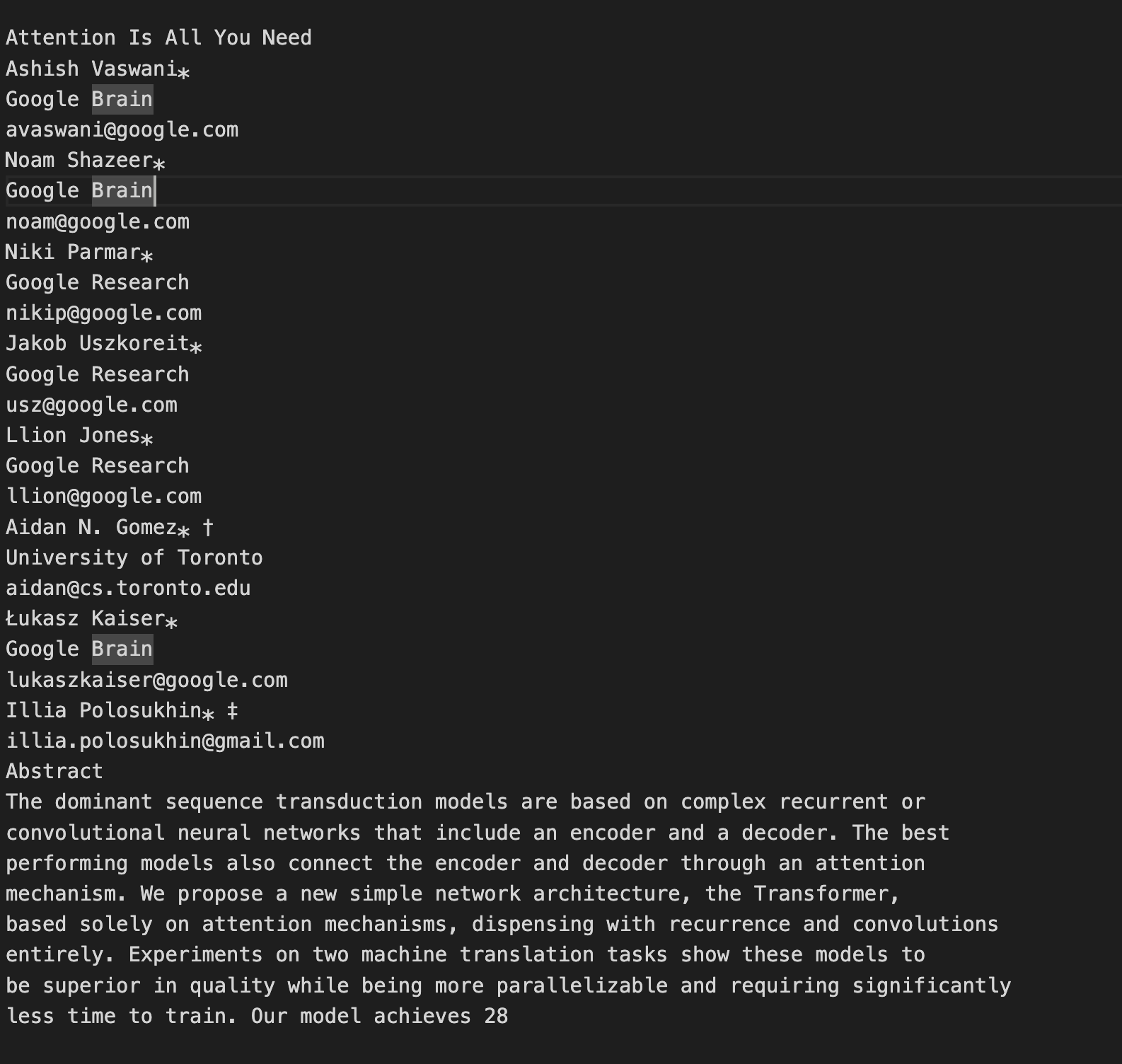
Are you sure you ran the PDF against my commit? Because I executed it against the PDF you mentioned (https://arxiv.org/pdf/1706.03762.pdf) and I'm getting a different result, as shown below.
Perhaps your console is not rendering the \n character and that's why the result seems off?
I've committed here the solution used by https://gitlab.com/autokent/pdf-parse, do you want to try on your pdf and see if that's better?
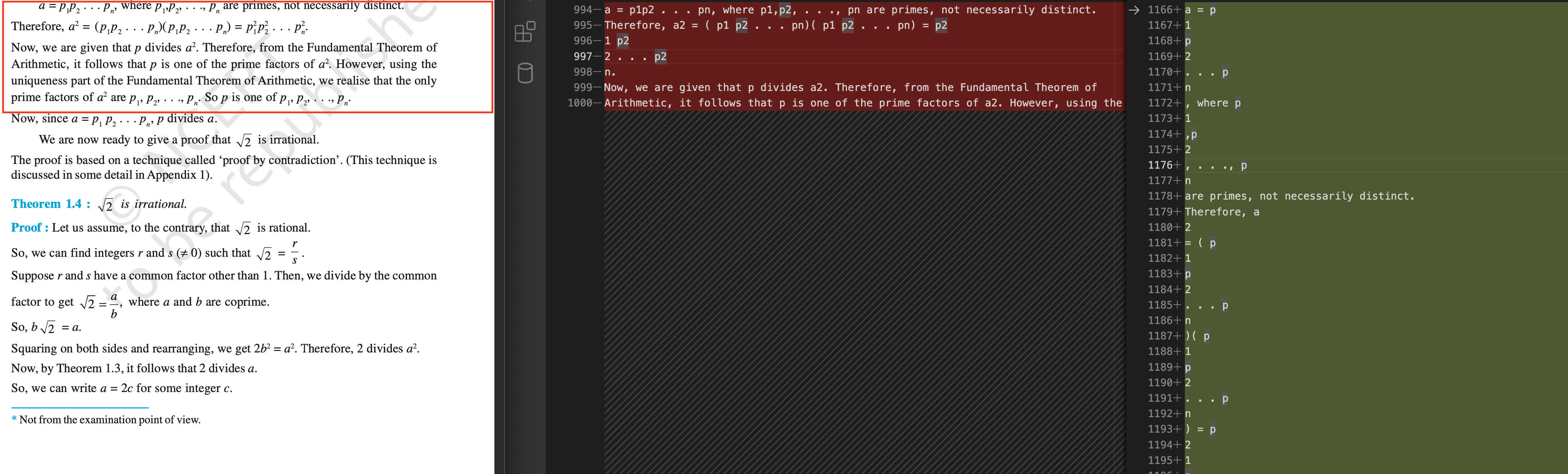
Unfortunately, the solution that you have committed doesn't seem to work for my pdfs. Example - red side of the diff editor is the output from my commit and green side would be from your commit.