mediapipe
 mediapipe copied to clipboard
mediapipe copied to clipboard
Object detection desktop tflite graph on gpu error - "Buffer 118 size in bytes 24 < requested size_in_bytes 9600"
Well, I successfully built object_detection desktop tflite solution with my custom tflite yolov5 model (thanks for you work!) Based on this graph i want to run it on gpu. If I understand mediapipe approach correctly, I should convert ImageFrame to gpu_buffer, then add to all Image or Tensor tags "_GPU" and convert gpu_buffer to ImageFrame back at the end. And, of course, add GPU delefate to the TfLiteInferencerCalculator.
Here is the graph I ended up with
max_queue_size: 1
node {
calculator: "OpenCvVideoDecoderCalculator"
input_side_packet: "INPUT_FILE_PATH:input_video_path"
output_stream: "VIDEO:input_video"
output_stream: "VIDEO_PRESTREAM:input_video_header"
}
node {
calculator: "ImageFrameToGpuBufferCalculator"
input_stream: "input_video"
output_stream: "input_video_gpu"
}
node: {
calculator: "ImageTransformationCalculator"
input_stream: "IMAGE_GPU:input_video_gpu"
output_stream: "IMAGE_GPU:transformed_input_video"
node_options: {
[type.googleapis.com/mediapipe.ImageTransformationCalculatorOptions] {
output_width: 640
output_height: 640
}
}
}
node {
calculator: "TfLiteConverterCalculator"
input_stream: "IMAGE_GPU:transformed_input_video"
output_stream: "TENSORS_GPU:image_tensor"
node_options: {
[type.googleapis.com/mediapipe.TfLiteConverterCalculatorOptions] {
zero_center: false
}
}
}
node {
calculator: "TfLiteInferenceCalculator"
input_stream: "TENSORS_GPU:image_tensor"
output_stream: "TENSORS_GPU:detection_tensors"
node_options: {
[type.googleapis.com/mediapipe.TfLiteInferenceCalculatorOptions] {
model_path: "int_0_01_yxyx_100float_tf_2_9_1.tflite"
delegate { gpu {use_advanced_gpu_api: true} }
}
}
}
node {
calculator: "TfLiteTensorsToDetectionsCalculator"
input_stream: "TENSORS_GPU:detection_tensors"
output_stream: "DETECTIONS:detections"
options: {
[mediapipe.TfLiteTensorsToDetectionsCalculatorOptions.ext]{
num_classes: 1
num_boxes: 100
num_coords: 4
min_score_thresh: 0.5
reverse_output_order: false
ignore_classes: [2]
apply_exponential_on_box_size: false
}
}
}
node {
calculator: "DetectionLabelIdToTextCalculator"
input_stream: "detections"
output_stream: "output_detections"
node_options: {
[type.googleapis.com/mediapipe.DetectionLabelIdToTextCalculatorOptions] {
label_map_path: "crpt.txt"
}
}
}
node {
calculator: "DetectionsToRenderDataCalculator"
input_stream: "DETECTIONS:output_detections"
output_stream: "RENDER_DATA:render_data"
node_options: {
[type.googleapis.com/mediapipe.DetectionsToRenderDataCalculatorOptions] {
thickness: 2.0
color { r: 255 g: 0 b: 0 }
}
}
}
node {
calculator: "AnnotationOverlayCalculator"
input_stream: "IMAGE:input_video"
input_stream: "render_data"
output_stream: "IMAGE:output_video"
}
node {
calculator: "OpenCvVideoEncoderCalculator"
input_stream: "VIDEO:output_video"
input_stream: "VIDEO_PRESTREAM:input_video_header"
input_side_packet: "OUTPUT_FILE_PATH:output_video_path"
node_options: {
[type.googleapis.com/mediapipe.OpenCvVideoEncoderCalculatorOptions]: {
codec: "avc1"
video_format: "mp4"
}
}
}
Here is the error log I am getting:
I20220617 16:23:04.327461 115357 simple_run_graph_main.cc:122] Initialize the calculator graph.
I20220617 16:23:04.328430 115357 simple_run_graph_main.cc:137] Start running the calculator graph.
I20220617 16:23:04.358013 115357 gl_context_egl.cc:84] Successfully initialized EGL. Major : 1 Minor: 5
I20220617 16:23:04.381624 115368 gl_context.cc:335] GL version: 3.2 (OpenGL ES 3.2 NVIDIA 470.129.06)
I20220617 16:23:04.381727 115357 gl_context_egl.cc:84] Successfully initialized EGL. Major : 1 Minor: 5
I20220617 16:23:04.390828 115369 gl_context.cc:335] GL version: 3.2 (OpenGL ES 3.2 NVIDIA 470.129.06)
ERROR: Following operations are not supported by GPU delegate:
CAST: Not supported Cast case.
GATHER: Operation is not supported.
NON_MAX_SUPPRESSION_V4: Operation is not supported.
STRIDED_SLICE: Slice does not support shrink_axis_mask parameter.
249 operations will run on the GPU, and the remaining 40 operations will run on the CPU.
ERROR: Following operations are not supported by GPU delegate:
CAST: Not supported Cast case.
GATHER: Operation is not supported.
NON_MAX_SUPPRESSION_V4: Operation is not supported.
STRIDED_SLICE: Slice does not support shrink_axis_mask parameter.
249 operations will run on the GPU, and the remaining 40 operations will run on the CPU.
W20220617 16:23:04.583326 115357 opencv_video_decoder_calculator.cc:230] Not all the frames are decoded (total frames: 441 vs decoded frames: 0).
E20220617 16:23:04.597381 115357 simple_run_graph_main.cc:149] Failed to run the graph: CalculatorGraph::Run() failed in Run:
Calculator::Open() for node "TfLiteInferenceCalculator" failed: Buffer 118 size in bytes 24 < requested size_in_bytes 9600
What am I doing wrong? Do I understand correctly that the cause of the error is not that some layers of the model cannot be executed on the GPU (they will simply be executed on the CPU), but in some kind of problem with the buffers?
BTW, i'm working with mediapipe v0.8.10 and tensorflow 2.9.1.
So, we were able to find out that this problem only occurs when we using coverted to tflite yolov5. When we run this graph with your ssd model everythin is ok. It turns out that the problem is in some layer of the yolov5 model, and only during inference on the GPU. Can you give any advice on how to more accurately localize the problem?
Hi @pixml27, We do not support Yolo, as it is quite out-dated, instead we recommend to use our SSD MobileNet object detection in Mediapipe. Typically, if you have a tensorflow model you'll need to convert it to mobile version with tflite_converter. Then use our inference calculator to run inference on device, our tflite inference calculators ensures that the model runs fine on different devices with different GPU backend such as Vulkan, OpenGL, cpu, etc. However, Yolo pre-dates all of this, and comes with its own darknet for inference, and the more recent quantized adoptions like xnornet are not supported. So if you insist on adding this to Mediapipe, you'll need to write a C++ wrapper for Yolo and then directly call that code in Mediapipe, then you have to make sure models runs fine on different gpu backend, etc.
Hey @kuaashish ! Thanks a lot for your answer! We use yolov5, and manual converted its tflite version. I don't think it's outdated, but it doesn't work on the GPU... In any case, we have done a lot of experiments, I want to share with you our observations and ask questions
- We forgot about yolo and started experimenting with models from tf-object-detection-api
- We started from Tensorflow 2. We converted CenterNet (resnet-50) and SSD (Movilenet_FPN_keras) to tflite using this approach
- Centernet didn't run on GPU at all. SSD started on the GPU, but very slowly (as you can see below - it took 5 minutes, like yolo on the CPU):
I20220621 18:47:42.878301 109230 simple_run_graph_main.cc:122] Initialize the calculator graph.
I20220621 18:47:42.878993 109230 simple_run_graph_main.cc:137] Start running the calculator graph.
I20220621 18:47:42.884274 109230 gl_context_egl.cc:84] Successfully initialized EGL. Major : 1 Minor: 5
I20220621 18:47:42.905244 109241 gl_context.cc:335] GL version: 3.2 (OpenGL ES 3.2 NVIDIA 470.129.06)
I20220621 18:47:42.905349 109230 gl_context_egl.cc:84] Successfully initialized EGL. Major : 1 Minor: 5
I20220621 18:47:42.912679 109242 gl_context.cc:335] GL version: 3.2 (OpenGL ES 3.2 NVIDIA 470.129.06)
INFO: Created TensorFlow Lite delegate for GPU.
ERROR: Following operations are not supported by GPU delegate:
CUSTOM TFLite_Detection_PostProcess: TFLite_Detection_PostProcess
PACK: OP is supported, but tensor type/shape isn't compatible.
RESHAPE: OP is supported, but tensor type/shape isn't compatible.
68 operations will run on the GPU, and the remaining 40 operations will run on the CPU.
W20220621 18:47:43.280387 109232 calculator_graph.cc:1224] Resolved a deadlock by increasing max_queue_size of input stream: input_video_header to: 2. Consider increasing max_queue_size for better performance.
W20220621 18:53:06.220429 109231 opencv_video_decoder_calculator.cc:230] Not all the frames are decoded (total frames: 441 vs decoded frames: 440).
I20220621 18:53:06.532114 109230 simple_run_graph_main.cc:152] Success!
Okay, let's assume that there are many operations that are not supported by the GPU, but then the question arises - is there at least one model here that can work with the media pipe on the GPU completely? 4. Okay, forgot about TF2. Let's assume that the nms calculator of the mediapipe is better and much faster than the nms inside the tflight model and move on to tf1. If we take your tf1 model and convert it as in the link - everything works perfectly But if we take our model trained on tf1, we convert it in the same way (with --add_postprocessing_op=False) - it doesn't work again
I20220624 15:04:44.136030 343259 simple_run_graph_main.cc:122] Initialize the calculator graph.
I20220624 15:04:44.137588 343259 simple_run_graph_main.cc:137] Start running the calculator graph.
I20220624 15:04:44.172026 343259 gl_context_egl.cc:84] Successfully initialized EGL. Major : 1 Minor: 5
I20220624 15:04:44.197243 343272 gl_context.cc:335] GL version: 3.2 (OpenGL ES 3.2 NVIDIA 470.129.06)
I20220624 15:04:44.197379 343259 gl_context_egl.cc:84] Successfully initialized EGL. Major : 1 Minor: 5
I20220624 15:04:44.209532 343273 gl_context.cc:335] GL version: 3.2 (OpenGL ES 3.2 NVIDIA 470.129.06)
ERROR: Following operations are not supported by GPU delegate:
MUL: MUL requires one tensor that not less than second in all dimensions.
RESHAPE: OP is supported, but tensor type/shape isn't compatible.
116 operations will run on the GPU, and the remaining 69 operations will run on the CPU.
ERROR: Following operations are not supported by GPU delegate:
MUL: MUL requires one tensor that not less than second in all dimensions.
RESHAPE: OP is supported, but tensor type/shape isn't compatible.
116 operations will run on the GPU, and the remaining 69 operations will run on the CPU.
W20220624 15:04:44.709188 343265 calculator_graph.cc:1224] Resolved a deadlock by increasing max_queue_size of input stream: input_video_header to: 2. Consider increasing max_queue_size for better performance.
W20220624 15:04:44.740053 343259 opencv_video_decoder_calculator.cc:230] Not all the frames are decoded (total frames: 441 vs decoded frames: 1).
E20220624 15:04:44.757854 343259 simple_run_graph_main.cc:149] Failed to run the graph: CalculatorGraph::Run() failed in Run:
Calculator::Process() for node "TfLiteInferenceCalculator" failed: ; RET_CHECK failure (mediapipe/calculators/tflite/tflite_inference_calculator.cc:451) tflite_gpu_runner_->Invoke().ok()
- Ok, I found the difference in models:
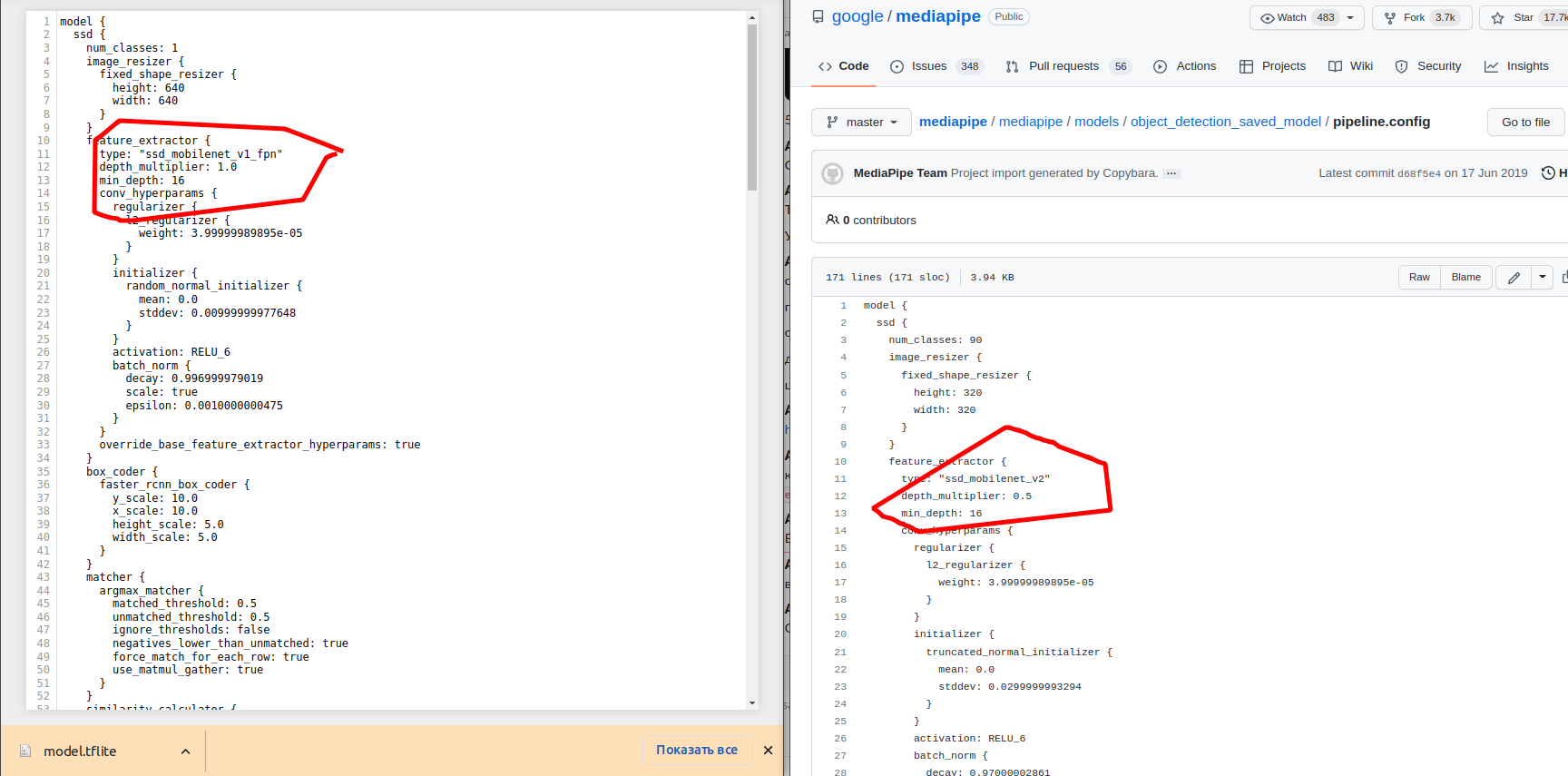
- It turns out that there is only one detection model that can fully work on the GPU in the mediapipe -- "ssd_mobilenet_v2"??
Well, I successfully built object_detection desktop tflite solution with my custom tflite yolov5 model (thanks for you work!) Based on this graph i want to run it on gpu. If I understand mediapipe approach correctly, I should convert ImageFrame to gpu_buffer, then add to all Image or Tensor tags "_GPU" and convert gpu_buffer to ImageFrame back at the end. And, of course, add GPU delefate to the TfLiteInferencerCalculator.
Here is the graph I ended up with
max_queue_size: 1 node { calculator: "OpenCvVideoDecoderCalculator" input_side_packet: "INPUT_FILE_PATH:input_video_path" output_stream: "VIDEO:input_video" output_stream: "VIDEO_PRESTREAM:input_video_header" } node { calculator: "ImageFrameToGpuBufferCalculator" input_stream: "input_video" output_stream: "input_video_gpu" } node: { calculator: "ImageTransformationCalculator" input_stream: "IMAGE_GPU:input_video_gpu" output_stream: "IMAGE_GPU:transformed_input_video" node_options: { [type.googleapis.com/mediapipe.ImageTransformationCalculatorOptions] { output_width: 640 output_height: 640 } } } node { calculator: "TfLiteConverterCalculator" input_stream: "IMAGE_GPU:transformed_input_video" output_stream: "TENSORS_GPU:image_tensor" node_options: { [type.googleapis.com/mediapipe.TfLiteConverterCalculatorOptions] { zero_center: false } } } node { calculator: "TfLiteInferenceCalculator" input_stream: "TENSORS_GPU:image_tensor" output_stream: "TENSORS_GPU:detection_tensors" node_options: { [type.googleapis.com/mediapipe.TfLiteInferenceCalculatorOptions] { model_path: "int_0_01_yxyx_100float_tf_2_9_1.tflite" delegate { gpu {use_advanced_gpu_api: true} } } } } node { calculator: "TfLiteTensorsToDetectionsCalculator" input_stream: "TENSORS_GPU:detection_tensors" output_stream: "DETECTIONS:detections" options: { [mediapipe.TfLiteTensorsToDetectionsCalculatorOptions.ext]{ num_classes: 1 num_boxes: 100 num_coords: 4 min_score_thresh: 0.5 reverse_output_order: false ignore_classes: [2] apply_exponential_on_box_size: false } } } node { calculator: "DetectionLabelIdToTextCalculator" input_stream: "detections" output_stream: "output_detections" node_options: { [type.googleapis.com/mediapipe.DetectionLabelIdToTextCalculatorOptions] { label_map_path: "crpt.txt" } } } node { calculator: "DetectionsToRenderDataCalculator" input_stream: "DETECTIONS:output_detections" output_stream: "RENDER_DATA:render_data" node_options: { [type.googleapis.com/mediapipe.DetectionsToRenderDataCalculatorOptions] { thickness: 2.0 color { r: 255 g: 0 b: 0 } } } } node { calculator: "AnnotationOverlayCalculator" input_stream: "IMAGE:input_video" input_stream: "render_data" output_stream: "IMAGE:output_video" } node { calculator: "OpenCvVideoEncoderCalculator" input_stream: "VIDEO:output_video" input_stream: "VIDEO_PRESTREAM:input_video_header" input_side_packet: "OUTPUT_FILE_PATH:output_video_path" node_options: { [type.googleapis.com/mediapipe.OpenCvVideoEncoderCalculatorOptions]: { codec: "avc1" video_format: "mp4" } } }Here is the error log I am getting:
I20220617 16:23:04.327461 115357 simple_run_graph_main.cc:122] Initialize the calculator graph. I20220617 16:23:04.328430 115357 simple_run_graph_main.cc:137] Start running the calculator graph. I20220617 16:23:04.358013 115357 gl_context_egl.cc:84] Successfully initialized EGL. Major : 1 Minor: 5 I20220617 16:23:04.381624 115368 gl_context.cc:335] GL version: 3.2 (OpenGL ES 3.2 NVIDIA 470.129.06) I20220617 16:23:04.381727 115357 gl_context_egl.cc:84] Successfully initialized EGL. Major : 1 Minor: 5 I20220617 16:23:04.390828 115369 gl_context.cc:335] GL version: 3.2 (OpenGL ES 3.2 NVIDIA 470.129.06) ERROR: Following operations are not supported by GPU delegate: CAST: Not supported Cast case. GATHER: Operation is not supported. NON_MAX_SUPPRESSION_V4: Operation is not supported. STRIDED_SLICE: Slice does not support shrink_axis_mask parameter. 249 operations will run on the GPU, and the remaining 40 operations will run on the CPU. ERROR: Following operations are not supported by GPU delegate: CAST: Not supported Cast case. GATHER: Operation is not supported. NON_MAX_SUPPRESSION_V4: Operation is not supported. STRIDED_SLICE: Slice does not support shrink_axis_mask parameter. 249 operations will run on the GPU, and the remaining 40 operations will run on the CPU. W20220617 16:23:04.583326 115357 opencv_video_decoder_calculator.cc:230] Not all the frames are decoded (total frames: 441 vs decoded frames: 0). E20220617 16:23:04.597381 115357 simple_run_graph_main.cc:149] Failed to run the graph: CalculatorGraph::Run() failed in Run: Calculator::Open() for node "TfLiteInferenceCalculator" failed: Buffer 118 size in bytes 24 < requested size_in_bytes 9600What am I doing wrong? Do I understand correctly that the cause of the error is not that some layers of the model cannot be executed on the GPU (they will simply be executed on the CPU), but in some kind of problem with the buffers?
BTW, i'm working with mediapipe v0.8.10 and tensorflow 2.9.1.
I had exactly the same error (incompatible buffer size) while trying to run a custom YOLOv5 model in .tflight format. Currently, I managed to run it on the CPU (Desktop and Android) and it works fine. But it would be great if i could test it on the GPU as well!!
@ilia-6over6 Hello! Can you share the file .pbtxt to run yolov5 on Desktop and Android ?
Hello, I happen to have the same problem with my custom Yolov5 model, but only for Desktop GPU, I manage to run it on Android using GPU, the only issue being a long loading time (~15s before it starts real time detection in my case). I'd be happy to know if you have any news related to this problem. By the way I don't have the same yolo as you, as I built my own calculator to infer detections from the raw yolo output, which is different from TfLiteTensorsToDetectionsCalculator in my case.
@ilia-6over6 Hello! Can you share the file .pbtxt to run yolov5 on Desktop and Android ?
Hi, Sorry for the late response. Sure, here is my .pbtxt file. Note that i re-implemented the TensorsToDetectionsCalculator function to fit YOLO bounding boxes structure.
input_stream: "IMAGE:image"
output_stream: "DETECTIONS:detections"
node: {
calculator: "ImageToTensorCalculator"
input_stream: "IMAGE:image"
output_stream: "TENSORS:input_tensors"
output_stream: "MATRIX:transform_matrix"
options: {
[mediapipe.ImageToTensorCalculatorOptions.ext] {
output_tensor_width: 320
output_tensor_height: 320
keep_aspect_ratio: true
output_tensor_float_range {
min: 0.0
max: 1.0
}
}
}
}
node {
calculator: "InferenceCalculator"
input_stream: "TENSORS:input_tensors"
output_stream: "TENSORS:detection_tensors"
options: {
[mediapipe.InferenceCalculatorOptions.ext] {
model_path: "mediapipe/modules/yolov5/yolov5n-fp16_320_3cls.tflite"
delegate {
#nnapi {} # for cpu optimization on Android
#xnnpack {} # for cpu optimization on Desktop
}
}
}
}
node {
calculator: "TensorsToDetectionsCalculator"
input_stream: "TENSORS:detection_tensors"
output_stream: "DETECTIONS:unfiltered_detections"
options: {
[mediapipe.TensorsToDetectionsCalculatorOptions.ext] {
num_classes: 3
num_boxes: 6300 #2268 #25200
num_coords: 4
box_coord_offset: 0
sigmoid_score: false
reverse_output_order: true
min_score_thresh: 0.5 #0.25
}
}
}
node {
calculator: "NonMaxSuppressionCalculator"
input_stream: "unfiltered_detections"
output_stream: "filtered_detections"
options: {
[mediapipe.NonMaxSuppressionCalculatorOptions.ext] {
min_suppression_threshold: 0.3 #0.45
overlap_type: INTERSECTION_OVER_UNION
algorithm: WEIGHTED
}
}
}
node {
calculator: "DetectionProjectionCalculator"
input_stream: "DETECTIONS:filtered_detections"
input_stream: "PROJECTION_MATRIX:transform_matrix"
output_stream: "DETECTIONS:detections"
}
Hello, I happen to have the same problem with my custom Yolov5 model, but only for Desktop GPU, I manage to run it on Android using GPU, the only issue being a long loading time (~15s before it starts real time detection in my case). I'd be happy to know if you have any news related to this problem. By the way I don't have the same yolo as you, as I built my own calculator to infer detections from the raw yolo output, which is different from TfLiteTensorsToDetectionsCalculator in my case.
I also have my custom implementation for TensorsToDetectionsCalculator. How did you manage to run it on Android GPU? I have this error for both platforms (Desktop & Android).
Finally got it to work by changing the export in yolov5 (see the above PR). Hope it helps!
Hello @pixml27, We are upgrading the MediaPipe Legacy Solutions to new MediaPipe solutions However, the libraries, documentation, and source code for all the MediapPipe Legacy Solutions will continue to be available in our GitHub repository and through library distribution services, such as Maven and NPM.
You can continue to use those legacy solutions in your applications if you choose. Though, we would request you to check new MediaPipe solutions which can help you more easily build and customize ML solutions for your applications. These new solutions will provide a superset of capabilities available in the legacy solutions. Thank you
This issue has been marked stale because it has no recent activity since 7 days. It will be closed if no further activity occurs. Thank you.
This issue was closed due to lack of activity after being marked stale for past 7 days.
I just wrote a medium post where I explain in detail how to use Mediapipe with Yolov5 on Desktop (Linux) with CPU\GPU and on Android with GPU if someone is interested.
Sorry for the delayed response. We are still using MediaPipe 0.8.1. It is possible that the issue has been fixed in newer versions. Here's what we have done so far:
-
We changed the TFLiteInferencer calculator to the Inferencer calculator.
-
We added the TfLiteGpuV2 delegate to the Inferencer calculator. This was necessary because YOLOv5, which was manually exported to TFLite, did not work on Linux and Android without this delegate. However, it worked perfectly on iOS. XNNPACK delegates were still slow for edge mobile phones, so we achieved much faster speed by using the GPU delegate (TfLiteGpuV2) based on OpenCL support.
-
To reduce long loading times, we used the following flag: inference_preference: TFLITE_GPU_INFERENCE_PREFERENCE_FAST_SINGLE_ANSWER