mediapipe
 mediapipe copied to clipboard
mediapipe copied to clipboard
Pose tracking / segmentation underperforms on Ryzen 9 3900X
System information (Please provide as much relevant information as possible): Ryzen 9 3900X 3.8GHz 32 GB RAM
- Have I written custom code (as opposed to using a stock example script provided in Mediapipe): Pose example
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04, Android 11, iOS 14.4): Windows 10, up to date
- MediaPipe version: 0.8.8
- Bazel version: 3.7.2
- Solution (e.g. FaceMesh, Pose, Holistic): Pose
- Programming Language and version ( e.g. C++, Python, Java): C++ For benchmarking purposes the default graph provided is being used.
Describe the expected behavior: High performance is achieved, the load is distributed equally to all the CPU cores.
Actual behavior Only one thread seems to be utilized, for 800x600 resolution, the frame time is roughly 33ms. Technically speaking, this is a real time performance (~30fps), but it's strange that it's not much better than what one could expect on a mobile phone despite running it on one of the top of the line CPUs. While testing it on i7 7700k, the frame time is 18ms/frame, but still only one thread seems to be utilized. The difference between Intel and AMD is also interesting. I benchmarked it on 5 different machines and Intel outperforms the AMD even in the case of older intel CPUs.
Is it possible to build with some options that allow distributing the workload equally between all the cores/threads for better performance or modify the graph somehow? I also created a dll of the Pose solution so I can sideload it into an app I'm working on and the performance is exactly the same as in the demo. 30ms/frame wouldn't be a problem if not for the fact that we need to run a whole bunch of other image processing operations on each frame and Pose consumes the entire frame time budget already.
Hi @MaksymAtNimagna, Thank you for sharing your query. Could you please provide any references like error logs or screenshots where it underperforms on the above.
Hi @MaksymAtNimagna, Thank you for sharing your query. Could you please provide any references like error logs or screenshots where it underperforms on the above.
Thank you for replying so fast! There are no errors and it's just a relatively low framerate issue where only a single core is being utilized (at least looking at the task manager) - what specifically could I provide to help you better to take a closer look at the issue?
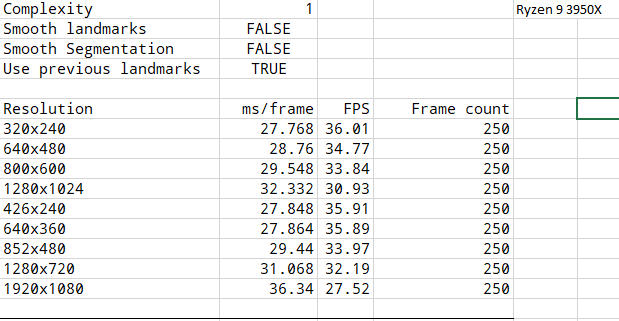
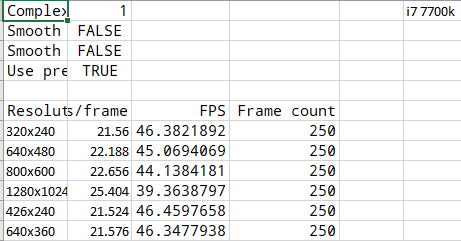
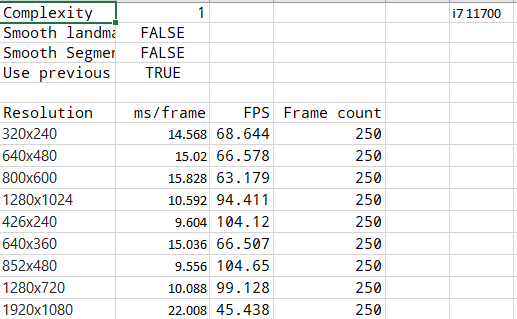
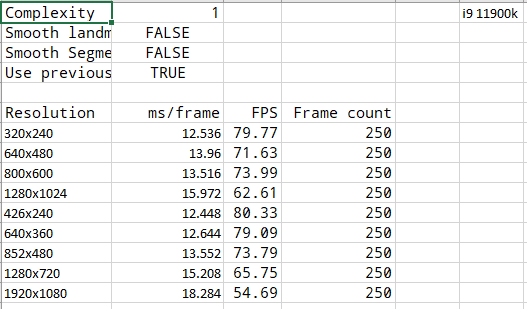
Here I include data collected from other platforms. Unfortunately I don't have a table for laptops we tried, but even on laptop i7 7820HK the performance is within 30ms/frame range and that's one of the top of the line mobile CPUs. Can something be done about the poor utilization of threads? For some reason everything seems to run on a single thread and not even utilize it fully in any of the cases above.
Hi, a few questions:
Are you running the CPU or GPU graph?
If CPU graph, Is the inference delegate using xnnpack?
If GPU graph, then there isn't much more to parallelize on CPU.
If CPU graph, is your OpenCV compiled with all the intrinsics enabled (if you didn't use setup_opencv.sh)?
Do the machines have similar DDR ram configurations/specs?
There is a num_threads option you can add to your graphs
add num_threads: 10 (or any number) to the top of your graphs.
The default is to choose a number based on # of cpus, but specifying a specific number might be beneficial..? This is just specifying a thread pool size, though (not forcing anything).
Thank you for your answer, @mcclanahoochie . I am running the CPU graph. If there's an option to run the GPU graph on Windows, I'd be very thankful for the guidelines - the only information I found is that it's currently not supported. I think it's running XNNPACK since I didn't change anything - how do I change the execution backend or check which one is used?
I used the OpenCV build from the official website (installer package for 3.4.10) and also tried building it myself with the options highlighted in setup_opencv.sh in versions 3.4.10, 3.4.1 and 4.5. I was unable to get the 4.x to work with mediapipe since it was complaining about missing optical flow module. Each of the above OpenCV build variants performed exactly the same.
I tried with the num_threads option with various combinations and this doesn't seem to have any effect on the performance (tried both 1, 5 and 10).
The most interesting insight is the memory configuration - all of the Intel machines tested run in dual channel mode at 2933, 3200 and 2933 MHz respectively. The Ryzen runs dual channel at 2666MHz. I was unable to overclock the memory to compare how this platform fares at higher memory clock rate.
@mcclanahoochie has there been any progress on this issue? The strangest part for me is that only one core is being utilized regardless of the CPU.
Has there been any progress on this or plans to better distribute the code across the cores or utilize GPU?
Hello @MaksymAtNimagna, We are upgrading the MediaPipe Legacy Solutions to new MediaPipe solutions However, the libraries, documentation, and source code for all the MediapPipe Legacy Solutions will continue to be available in our GitHub repository and through library distribution services, such as Maven and NPM.
You can continue to use those legacy solutions in your applications if you choose. Though, we would request you to check new MediaPipe solutions which can help you more easily build and customize ML solutions for your applications. These new solutions will provide a superset of capabilities available in the legacy solutions.
This issue has been marked stale because it has no recent activity since 7 days. It will be closed if no further activity occurs. Thank you.
This issue was closed due to lack of activity after being marked stale for past 7 days.