lf
 lf copied to clipboard
lf copied to clipboard
random crash, unexpected signal during runtime execution
I don't know how to reproduce it. It seems crash randomly during runtime.
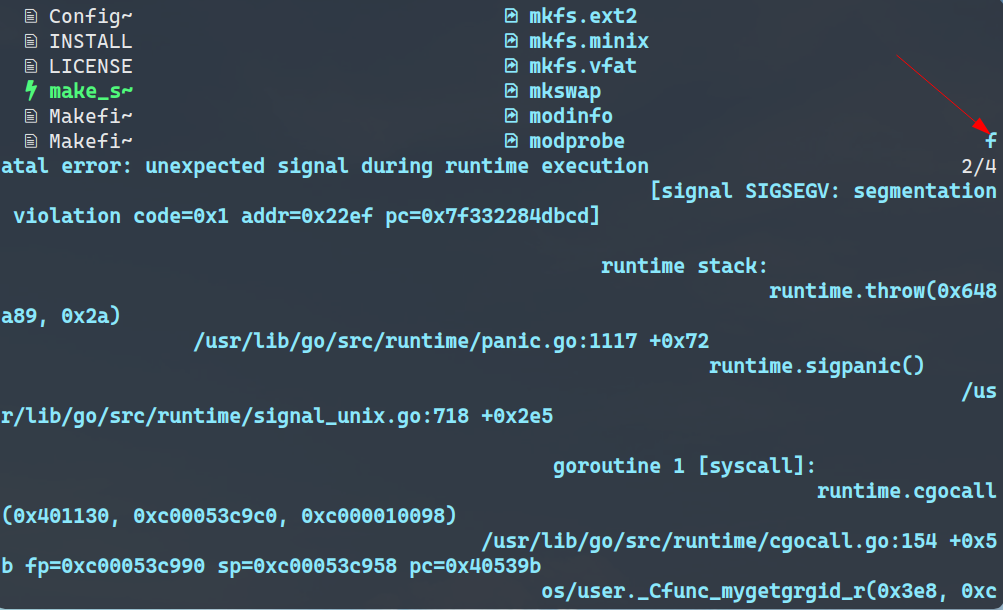
My environment:
- OS: arch linux, 5.13.5
- CPU: AMD Ryzen 5 3550H with Radeon Vega Mobile Gfx (8) @ 2.100GHz
- GPU: AMD ATI 03:00.0 Picasso
- window manager: bspwm
@66RING Thanks for reporting. We should eliminate such crashes as much as possible. Unfortunately, there's nothing much we can do until we find the steps to reproduce. Feel free to add more info here if you come up with something. It's interesting that stacktrace in the screenshot does not seem to show anything in our code but only system calls. Also, can you confirm you're using the latest version?
@gokcehan This is the full stacktrace I simply copy from stdout. I tried to find lf's log file, but /tmp/lf.log only has history info. lf.log
@66RING Backtrace shows some functions for user lookup. These are used to determine home directories for config file locations etc. Do you have something custom in your setup? Log file should be in /tmp/lf.${USER}.${id}.log. Do you have an empty USER variable in the environment?
@gokcehan I start lf in a wrapper script, which combined Uberzug preview and lfcd.
# lfcd.sh
__lf() {
if [ -n "$DISPLAY" ]; then
export FIFO_UEBERZUG="${TMPDIR:-/tmp}/lf-ueberzug-$$"
cleanup() {
exec 3>&-
rm "$FIFO_UEBERZUG"
}
if [ -f "$FIFO_UEBERZUG" ]; then
rm "$FIFO_UEBERZUG"
fi
mkfifo "$FIFO_UEBERZUG" 2> /dev/null
ueberzug layer --silent <"$FIFO_UEBERZUG" &
upid=$!
exec 3>"$FIFO_UEBERZUG"
trap cleanup EXIT
if ! [ -d "$HOME/.cache/lf" ]; then
mkdir -p "$HOME/.cache/lf"
fi
lf "$@" 3>&-
else
lf "$@"
fi
}
lfcd () {
tmp="$(mktemp)"
export LF_BACK="$(pwd)"
(__lf -last-dir-path="$tmp" "$@")
if [ -f "$tmp" ]; then
dir="$(cat "$tmp")"
rm -f "$tmp"
unset LF_BACK
if [ -d "$dir" ]; then
if [ "$dir" != "$(pwd)" ]; then
cd "$dir"
fi
fi
fi
}
Usage:
$ source ./lfcd.sh
$ lfcd
And my lfrc is:
set previewer /home/ring/.config/lf/scope.sh
set cleaner /home/ring/.config/lf/clear_img.sh
set shell bash
set shellopts '-eu'
set ifs "\n"
set scrolloff 10
scope.sh should be from ranger
I checked /tmp/lf.${USER}.${id}.log. It recorded command history. Maybe I can find the last command, next time the crash happend.
It seems to happen at random
log file of recent crash:
$ cat lf.ring.5523.log
2021/08/07 10:45:51 hi!
2021/08/07 10:45:51 loading files: []
2021/08/07 10:45:51 reading file: /home/ring/.config/lf/lfrc
2021/08/07 10:45:51 loading files: []
2021/08/07 10:50:49 search: loca
2021/08/07 10:50:50 pushing keys 5k
$ cat lf.ring.14779.log
2021/08/03 10:42:06 hi!
2021/08/03 10:42:06 loading files: []
2021/08/03 10:42:06 reading file: /home/ring/.config/lf/lfrc
2021/08/03 10:42:06 loading files: []
2021/08/03 10:42:08 search: make
$ cat lf.ring.105270.log
2021/08/04 08:09:39 hi!
2021/08/04 08:09:39 loading files: []
2021/08/04 08:09:39 reading file: /home/ring/.config/lf/lfrc
2021/08/04 08:09:39 loading files: []
2021/08/04 08:09:51 pushing keys 5k
@66RING From the crash log, it seems that the segfault is happening in getgrgid_r, which is a libc function. Does it crash consistently when you move to certain files? If you can reproduce it, could you generate a core dump with GOTRACEBACK=crash lf?
Hi, any updates on this? I've been getting what looks like the same fatal error every other day for months now.
Previously I was using lf-git from the aur, but never updated it. I'm not sure what the version was but I installed it around June 2022. Everything was working fine. Early this year I switched to the main repo package (version 28 at the time) and the crashes started immediately.
- lf version: 30
- os: arch 6.3.7
- terminal: st
- my config files
- wrapper script I use
- lferror.log
@SeekingBlues
Does it crash consistently when you move to certain files?
No. For me, it happens at random only while moving around files / directories with hjkl. Never happens while doing any other operation like opening a file or cutting and pasting.
Initially I thought it had something to do with first time preview generation or first encounter of a file on screen because it seems more likely to crash when new files are present, but I'm really not sure.
If you can reproduce it, could you generate a core dump with
GOTRACEBACK=crash lf?
If you think this would help, can you please explain in detail how I'm supposed to do it?
@gokcehan
log file
I don't have one in /tmp/.
Do you have an empty USER variable in the environment?
[jameson@arch ~]$ echo $USER
jameson
Any ideas for how I can test this issue to possibly narrow down the cause? I have no idea how to deduce the error message.
Hi, @2084x
If you think this would help, can you please explain in detail how I'm supposed to do it?
Just GOTRACEBACK=crash lf, (SOME_ENV=var <cmd>), which should generate some core dump file.
But it doesn't happen anymore when I add this GOTRACEBACK=crash env
@66RING
Oh I see, it's an env variable. So I've just prefixed lf with GOTRACEBACK=crash in my wrapper script. Hopefully it's all good now...
Where will the file be generated if it crashes again?
The backtrace itself should be printed on the console, and the core dump can be retrieved using coredumpctl (systemd specific).
Using the latest git version, it hasn't happend for me in a while. Whereas previously (some months ago) I saw it on a daily basis.
Thanks for the help guys! Since adding that variable I haven't had any issues.
well looks like it's not gone completely. I've had a few crashes over the last month. here's the coredump info from the most recent crash:
[jameson@arch ~]$ coredumpctl info 168684
PID: 168684 (lf)
UID: 1000 (jameson)
GID: 1000 (jameson)
Signal: 6 (ABRT)
Timestamp: Fri 2023-07-21 19:08:13 AEST (1min 53s ago)
Command Line: lf
Executable: /usr/bin/lf
Control Group: /user.slice/user-1000.slice/session-1.scope
Unit: session-1.scope
Slice: user-1000.slice
Session: 1
Owner UID: 1000 (jameson)
Boot ID: 2515cafb98c441b398ee216a3f730e0d
Machine ID: 8e78a3564f072d699b94099062bad255
Hostname: arch
Storage: /var/lib/systemd/coredump/core.lf.1000.2515cafb98c441b398ee216a3f730e0d.168684.1689930493000000.zst (present)
Size on Disk: 1.0M
Message: Process 168684 (lf) of user 1000 dumped core.
Stack trace of thread 168709:
#0 0x000055b508e95aa1 n/a (lf + 0xc0aa1)
#1 0x000055b508e78eae n/a (lf + 0xa3eae)
#2 0x000055b508e774c7 n/a (lf + 0xa24c7)
#3 0x000055b508e95da9 n/a (lf + 0xc0da9)
#4 0x00007f3a97a65ab0 n/a (libc.so.6 + 0x39ab0)
#5 0x000055b508e95aa1 n/a (lf + 0xc0aa1)
#6 0x000055b508e78a38 n/a (lf + 0xa3a38)
#7 0x000055b508e61c91 n/a (lf + 0x8cc91)
#8 0x000055b508e61c0c n/a (lf + 0x8cc0c)
#9 0x000055b508e618bf n/a (lf + 0x8c8bf)
#10 0x000055b508e787a9 n/a (lf + 0xa37a9)
#11 0x00007f3a97a68cfd getenv (libc.so.6 + 0x3ccfd)
#12 0x00007f3a6c38ab36 _nss_systemd_getgrgid_r (libnss_systemd.so.2 + 0xeb36)
#13 0x00007f3a97afe0af getgrgid_r (libc.so.6 + 0xd20af)
#14 0x000055b508fe48ca _cgo_6f668e16310a_Cfunc_mygetgrgid_r (lf + 0x20f8ca)
#15 0x000055b508e93e01 n/a (lf + 0xbee01)
ELF object binary architecture: AMD x86-64
here is the file at /var/lib/systemd/coredump/ https://files.catbox.moe/encomw.zst
and the file generated with coredumpctl -o lf.coredump dump /usr/bin/lf
https://files.catbox.moe/9u5yir.coredump
is there any useful info here?
I started my lf wrapper from a keybind so I didn't catch the terminal output, but I assume it's the same as the log in my first comment.
Seems like a race condition between getenv and setenv. In the preview thread, exportOpts is invoked, which calls setenv several times. In the main thread, getgrgid is invoked to get the group name information of a file, which calls into _nss_systemd_getgrgid_r, and then getenv. setenv invalidates the pointers used by getenv, causing the segfault.
Seems like a race condition between
getenvandsetenv. In the preview thread,exportOptsis invoked, which callssetenvseveral times. In the main thread,getgrgidis invoked to get the group name information of a file, which calls into_nss_systemd_getgrgid_r, and thengetenv.setenvinvalidates the pointers used bygetenv, causing the segfault.
Thanks for investigating this! Incidentally, we have been discussing about removing such exports in the preview thread in #1314 as well, see https://github.com/gokcehan/lf/issues/1314#issuecomment-1631141977 for more details.
#1354 has now been merged, which removes the exportOpts call in the preview thread.
@66RING, @2084x You can try the latest version in the master branch to see if lf still crashes. If it doesn't then we can close this issue.
Closing this issue for now since #1354 has been merged and there hasn't been any further crashes reported.
@joelim-work apologies for the delayed reply. since the crashes happened at random I was waiting a couple of weeks to see if any would occur. I can now report that everything has been working perfectly, so thank you for the fix!