feathr
 feathr copied to clipboard
feathr copied to clipboard
Spark job failures when running databricks_quickstart_nyc_taxi_driver notebook in Databricks
When running the example notebook databricks_quickstart_nyc_taxi_driver in Databricks different cells raise an AnalysisException due to the to_unix_timestamp function. This may be user error although the language of the notebook leads me to believe the notebook should run with little configuration. The cells that raise this error appear to change based on the Databricks runtime used - is there a specific runtime that this notebook needs to run?
With the latest runtime 10.4 the notebook fails when calling client.get_offline_features
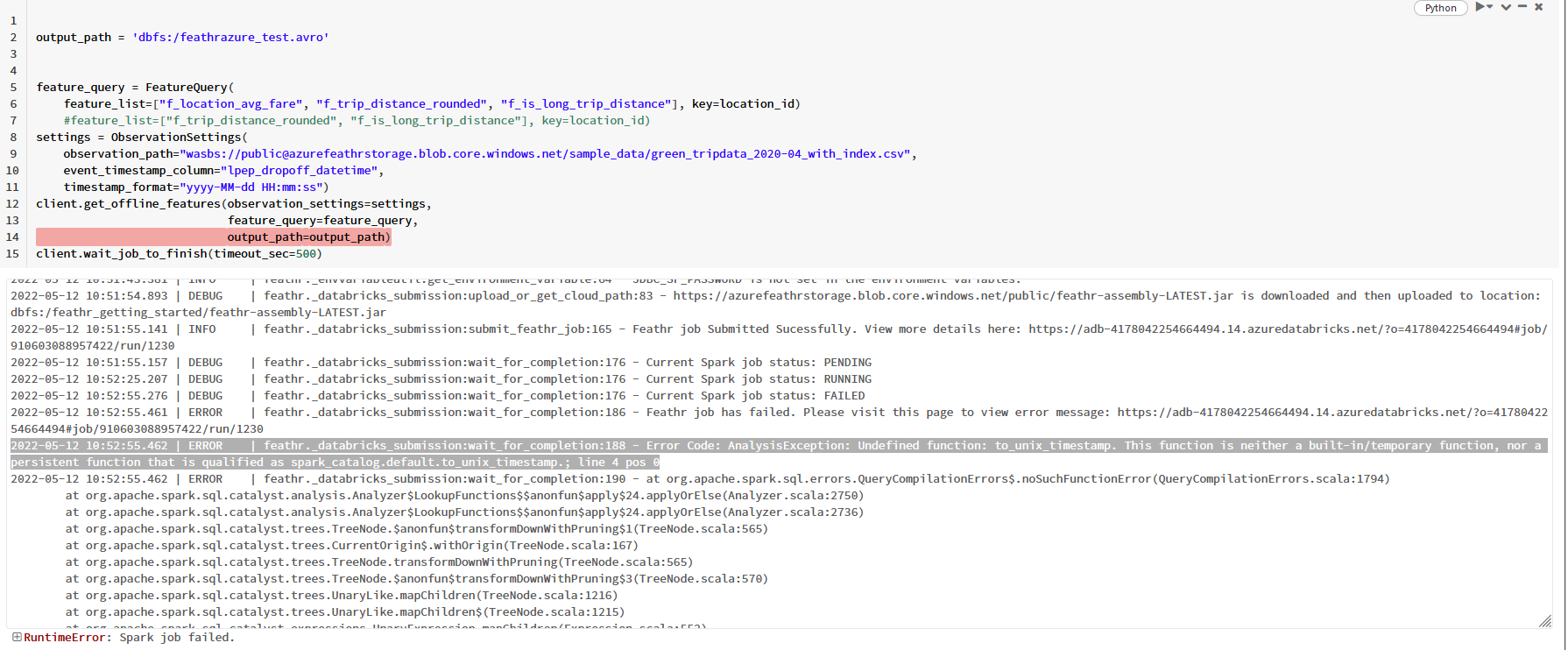
When running the cluster with runtime 9.1 client.get_offline_features runs without issue, but the later cell materializing the features fails with the same error instead.
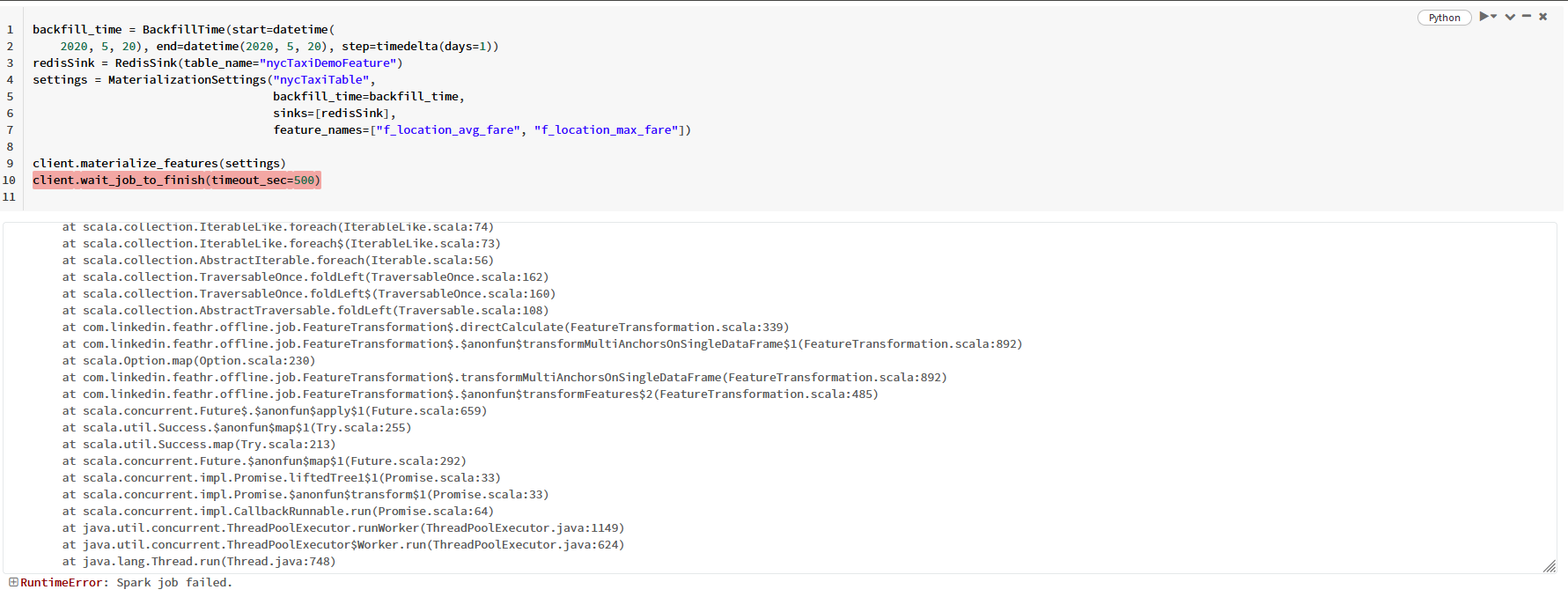
Steps to reproduce
- Follow the README.md and deploy all Feathr Resources in Azure
- Create a new Azure Databricks resource in the same resource group
- Create computer clusters within the Databricks workspace (notebook attempted on clusters with runtimes 10.4 and 9.1 )
- Import notebook into Databricks workspace from url https://github.com/linkedin/feathr/blob/main/docs/samples/databricks/databricks_quickstart_nyc_taxi_driver.ipynb
- No code is changed other than entering the redis connection details on cell 9
- Run all cells
Runtime 9.1 Full error trace
2022-05-12 10:58:48.258 | INFO | feathr._envvariableutil:get_environment_variable:64 - KAFKA_SASL_JAAS_CONFIG is not set in the environment variables. 2022-05-12 10:58:48.444 | INFO | feathr._databricks_submission:upload_or_get_cloud_path:93 - Uploading folder /databricks/driver/feature_conf/ 2022-05-12 10:58:48.913 | INFO | feathr._envvariableutil:get_environment_variable:64 - S3_ACCESS_KEY is not set in the environment variables. 2022-05-12 10:58:48.913 | INFO | feathr._envvariableutil:get_environment_variable:64 - S3_SECRET_KEY is not set in the environment variables. 2022-05-12 10:58:48.914 | INFO | feathr._envvariableutil:get_environment_variable:64 - ADLS_ACCOUNT is not set in the environment variables. 2022-05-12 10:58:48.914 | INFO | feathr._envvariableutil:get_environment_variable:64 - ADLS_KEY is not set in the environment variables. 2022-05-12 10:58:48.914 | INFO | feathr._envvariableutil:get_environment_variable:64 - BLOB_ACCOUNT is not set in the environment variables. 2022-05-12 10:58:48.914 | INFO | feathr._envvariableutil:get_environment_variable:64 - BLOB_KEY is not set in the environment variables. 2022-05-12 10:58:48.915 | INFO | feathr._envvariableutil:get_environment_variable:64 - JDBC_TABLE is not set in the environment variables. 2022-05-12 10:58:48.915 | INFO | feathr._envvariableutil:get_environment_variable:64 - JDBC_USER is not set in the environment variables. 2022-05-12 10:58:48.915 | INFO | feathr._envvariableutil:get_environment_variable:64 - JDBC_PASSWORD is not set in the environment variables. 2022-05-12 10:58:48.915 | INFO | feathr._envvariableutil:get_environment_variable:64 - JDBC_DRIVER is not set in the environment variables. 2022-05-12 10:58:48.915 | INFO | feathr._envvariableutil:get_environment_variable:64 - JDBC_AUTH_FLAG is not set in the environment variables. 2022-05-12 10:58:48.915 | INFO | feathr._envvariableutil:get_environment_variable:64 - JDBC_TOKEN is not set in the environment variables. 2022-05-12 10:58:48.930 | INFO | feathr._envvariableutil:get_environment_variable:64 - JDBC_SF_PASSWORD is not set in the environment variables. 2022-05-12 10:59:01.140 | DEBUG | feathr._databricks_submission:upload_or_get_cloud_path:83 - https://azurefeathrstorage.blob.core.windows.net/public/feathr-assembly-LATEST.jar is downloaded and then uploaded to location: dbfs:/feathr_getting_started/feathr-assembly-LATEST.jar 2022-05-12 10:59:01.436 | INFO | feathr._databricks_submission:submit_feathr_job:165 - Feathr job Submitted Sucessfully. View more details here: https://adb-4178042254664494.14.azuredatabricks.net/?o=4178042254664494#job/775221149650770/run/1399 2022-05-12 10:59:01.451 | DEBUG | feathr._databricks_submission:wait_for_completion:176 - Current Spark job status: PENDING 2022-05-12 10:59:31.485 | DEBUG | feathr._databricks_submission:wait_for_completion:176 - Current Spark job status: FAILED 2022-05-12 10:59:31.658 | ERROR | feathr._databricks_submission:wait_for_completion:186 - Feathr job has failed. Please visit this page to view error message: https://adb-4178042254664494.14.azuredatabricks.net/?o=4178042254664494#job/775221149650770/run/1399 2022-05-12 10:59:31.658 | ERROR | feathr._databricks_submission:wait_for_completion:188 - Error Code: AnalysisException: Undefined function: 'to_unix_timestamp'. This function is neither a registered temporary function nor a permanent function registered in the database 'default'.; line 1 pos 0 2022-05-12 10:59:31.658 | ERROR | feathr._databricks_submission:wait_for_completion:190 - at org.apache.spark.sql.catalyst.analysis.Analyzer$LookupFunctions$$anonfun$apply$26.$anonfun$applyOrElse$130(Analyzer.scala:2885) at org.apache.spark.sql.catalyst.analysis.package$.withPosition(package.scala:53) at org.apache.spark.sql.catalyst.analysis.Analyzer$LookupFunctions$$anonfun$apply$26.applyOrElse(Analyzer.scala:2885) at org.apache.spark.sql.catalyst.analysis.Analyzer$LookupFunctions$$anonfun$apply$26.applyOrElse(Analyzer.scala:2875) at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$1(TreeNode.scala:484) at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:86) at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:484) at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$3(TreeNode.scala:489) at org.apache.spark.sql.catalyst.expressions.UnaryLikeExpression.mapChildren(Expression.scala:526) at org.apache.spark.sql.catalyst.expressions.UnaryLikeExpression.mapChildren$(Expression.scala:525) at org.apache.spark.sql.catalyst.expressions.UnaryExpression.mapChildren(Expression.scala:554) at org.apache.spark.sql.catalyst.expressions.UnaryExpression.mapChildren(Expression.scala:554) at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:489) at org.apache.spark.sql.catalyst.plans.QueryPlan.$anonfun$transformExpressionsDownWithPruning$1(QueryPlan.scala:164) at org.apache.spark.sql.catalyst.plans.QueryPlan.$anonfun$mapExpressions$1(QueryPlan.scala:205) at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:86) at org.apache.spark.sql.catalyst.plans.QueryPlan.transformExpression$1(QueryPlan.scala:205) at org.apache.spark.sql.catalyst.plans.QueryPlan.recursiveTransform$1(QueryPlan.scala:216) at org.apache.spark.sql.catalyst.plans.QueryPlan.$anonfun$mapExpressions$3(QueryPlan.scala:221) at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238) at scala.collection.immutable.List.foreach(List.scala:392) at scala.collection.TraversableLike.map(TraversableLike.scala:238) at scala.collection.TraversableLike.map$(TraversableLike.scala:231) at scala.collection.immutable.List.map(List.scala:298) at org.apache.spark.sql.catalyst.plans.QueryPlan.recursiveTransform$1(QueryPlan.scala:221) at org.apache.spark.sql.catalyst.plans.QueryPlan.$anonfun$mapExpressions$4(QueryPlan.scala:226) at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:322) at org.apache.spark.sql.catalyst.plans.QueryPlan.mapExpressions(QueryPlan.scala:226) at org.apache.spark.sql.catalyst.plans.QueryPlan.transformExpressionsDownWithPruning(QueryPlan.scala:164) at org.apache.spark.sql.catalyst.plans.QueryPlan.transformExpressionsWithPruning(QueryPlan.scala:135) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveExpressionsWithPruning$1.applyOrElse(AnalysisHelper.scala:240) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveExpressionsWithPruning$1.applyOrElse(AnalysisHelper.scala:239) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.$anonfun$resolveOperatorsDownWithPruning$2(AnalysisHelper.scala:172) at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:86) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.$anonfun$resolveOperatorsDownWithPruning$1(AnalysisHelper.scala:172) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.allowInvokingTransformsInAnalyzer(AnalysisHelper.scala:340) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperatorsDownWithPruning(AnalysisHelper.scala:170) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperatorsDownWithPruning$(AnalysisHelper.scala:166) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperatorsDownWithPruning(LogicalPlan.scala:29) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperatorsWithPruning(AnalysisHelper.scala:98) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperatorsWithPruning$(AnalysisHelper.scala:95) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperatorsWithPruning(LogicalPlan.scala:29) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveExpressionsWithPruning(AnalysisHelper.scala:239) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveExpressionsWithPruning$(AnalysisHelper.scala:237) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveExpressionsWithPruning(LogicalPlan.scala:29) at org.apache.spark.sql.catalyst.analysis.Analyzer$LookupFunctions$.apply(Analyzer.scala:2875) at org.apache.spark.sql.catalyst.analysis.Analyzer$LookupFunctions$.apply(Analyzer.scala:2871) at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$3(RuleExecutor.scala:221) at com.databricks.spark.util.FrameProfiler$.record(FrameProfiler.scala:80) at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$2(RuleExecutor.scala:221) at scala.collection.IndexedSeqOptimized.foldLeft(IndexedSeqOptimized.scala:60) at scala.collection.IndexedSeqOptimized.foldLeft$(IndexedSeqOptimized.scala:68) at scala.collection.mutable.WrappedArray.foldLeft(WrappedArray.scala:38) at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$1(RuleExecutor.scala:218) at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$1$adapted(RuleExecutor.scala:210) at scala.collection.immutable.List.foreach(List.scala:392) at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:210) at org.apache.spark.sql.catalyst.analysis.Analyzer.org$apache$spark$sql$catalyst$analysis$Analyzer$$executeSameContext(Analyzer.scala:271) at org.apache.spark.sql.catalyst.analysis.Analyzer.execute(Analyzer.scala:264) at org.apache.spark.sql.catalyst.analysis.Analyzer.execute(Analyzer.scala:191) at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$executeAndTrack$1(RuleExecutor.scala:188) at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:109) at org.apache.spark.sql.catalyst.rules.RuleExecutor.executeAndTrack(RuleExecutor.scala:188) at org.apache.spark.sql.catalyst.analysis.Analyzer.$anonfun$executeAndCheck$1(Analyzer.scala:246) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.markInAnalyzer(AnalysisHelper.scala:347) at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:245) at org.apache.spark.sql.execution.QueryExecution.$anonfun$analyzed$1(QueryExecution.scala:96) at com.databricks.spark.util.FrameProfiler$.record(FrameProfiler.scala:80) at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:134) at org.apache.spark.sql.execution.QueryExecution.$anonfun$executePhase$1(QueryExecution.scala:180) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:854) at org.apache.spark.sql.execution.QueryExecution.executePhase(QueryExecution.scala:180) at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:97) at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:94) at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:86) at org.apache.spark.sql.Dataset$.$anonfun$ofRows$1(Dataset.scala:95) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:854) at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:93) at org.apache.spark.sql.Dataset.withPlan(Dataset.scala:3859) at org.apache.spark.sql.Dataset.select(Dataset.scala:1499) at org.apache.spark.sql.Dataset.withColumns(Dataset.scala:2470) at org.apache.spark.sql.Dataset.withColumn(Dataset.scala:2437) at com.linkedin.feathr.offline.transformation.WindowAggregationEvaluator$.transform(WindowAggregationEvaluator.scala:62) at com.linkedin.feathr.offline.job.FeatureTransformation$.transformSingleAnchorDF(FeatureTransformation.scala:191) at com.linkedin.feathr.offline.job.FeatureTransformation$.$anonfun$directCalculate$4(FeatureTransformation.scala:342) at scala.collection.TraversableOnce.$anonfun$foldLeft$1(TraversableOnce.scala:162) at scala.collection.TraversableOnce.$anonfun$foldLeft$1$adapted(TraversableOnce.scala:162) at scala.collection.Iterator.foreach(Iterator.scala:941) at scala.collection.Iterator.foreach$(Iterator.scala:941) at scala.collection.AbstractIterator.foreach(Iterator.scala:1429) at scala.collection.IterableLike.foreach(IterableLike.scala:74) at scala.collection.IterableLike.foreach$(IterableLike.scala:73) at scala.collection.AbstractIterable.foreach(Iterable.scala:56) at scala.collection.TraversableOnce.foldLeft(TraversableOnce.scala:162) at scala.collection.TraversableOnce.foldLeft$(TraversableOnce.scala:160) at scala.collection.AbstractTraversable.foldLeft(Traversable.scala:108) at com.linkedin.feathr.offline.job.FeatureTransformation$.directCalculate(FeatureTransformation.scala:339) at com.linkedin.feathr.offline.job.FeatureTransformation$.$anonfun$transformMultiAnchorsOnSingleDataFrame$1(FeatureTransformation.scala:892) at scala.Option.map(Option.scala:230) at com.linkedin.feathr.offline.job.FeatureTransformation$.transformMultiAnchorsOnSingleDataFrame(FeatureTransformation.scala:892) at com.linkedin.feathr.offline.job.FeatureTransformation$.$anonfun$transformFeatures$2(FeatureTransformation.scala:485) at scala.concurrent.Future$.$anonfun$apply$1(Future.scala:659) at scala.util.Success.$anonfun$map$1(Try.scala:255) at scala.util.Success.map(Try.scala:213) at scala.concurrent.Future.$anonfun$map$1(Future.scala:292) at scala.concurrent.impl.Promise.liftedTree1$1(Promise.scala:33) at scala.concurrent.impl.Promise.$anonfun$transform$1(Promise.scala:33) at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:64) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
Runtime 10.4 Full error trace
2022-05-12 10:51:42.836 | INFO | feathr._databricks_submission:upload_or_get_cloud_path:93 - Uploading folder /databricks/driver/feature_conf/ 2022-05-12 10:51:43.360 | INFO | feathr._envvariableutil:get_environment_variable:64 - S3_ACCESS_KEY is not set in the environment variables. 2022-05-12 10:51:43.360 | INFO | feathr._envvariableutil:get_environment_variable:64 - S3_SECRET_KEY is not set in the environment variables. 2022-05-12 10:51:43.360 | INFO | feathr._envvariableutil:get_environment_variable:64 - ADLS_ACCOUNT is not set in the environment variables. 2022-05-12 10:51:43.361 | INFO | feathr._envvariableutil:get_environment_variable:64 - ADLS_KEY is not set in the environment variables. 2022-05-12 10:51:43.361 | INFO | feathr._envvariableutil:get_environment_variable:64 - BLOB_ACCOUNT is not set in the environment variables. 2022-05-12 10:51:43.361 | INFO | feathr._envvariableutil:get_environment_variable:64 - BLOB_KEY is not set in the environment variables. 2022-05-12 10:51:43.361 | INFO | feathr._envvariableutil:get_environment_variable:64 - JDBC_TABLE is not set in the environment variables. 2022-05-12 10:51:43.361 | INFO | feathr._envvariableutil:get_environment_variable:64 - JDBC_USER is not set in the environment variables. 2022-05-12 10:51:43.361 | INFO | feathr._envvariableutil:get_environment_variable:64 - JDBC_PASSWORD is not set in the environment variables. 2022-05-12 10:51:43.362 | INFO | feathr._envvariableutil:get_environment_variable:64 - JDBC_DRIVER is not set in the environment variables. 2022-05-12 10:51:43.362 | INFO | feathr._envvariableutil:get_environment_variable:64 - JDBC_AUTH_FLAG is not set in the environment variables. 2022-05-12 10:51:43.362 | INFO | feathr._envvariableutil:get_environment_variable:64 - JDBC_TOKEN is not set in the environment variables. 2022-05-12 10:51:43.381 | INFO | feathr._envvariableutil:get_environment_variable:64 - JDBC_SF_PASSWORD is not set in the environment variables. 2022-05-12 10:51:54.893 | DEBUG | feathr._databricks_submission:upload_or_get_cloud_path:83 - https://azurefeathrstorage.blob.core.windows.net/public/feathr-assembly-LATEST.jar is downloaded and then uploaded to location: dbfs:/feathr_getting_started/feathr-assembly-LATEST.jar 2022-05-12 10:51:55.141 | INFO | feathr._databricks_submission:submit_feathr_job:165 - Feathr job Submitted Sucessfully. View more details here: https://adb-4178042254664494.14.azuredatabricks.net/?o=4178042254664494#job/910603088957422/run/1230 2022-05-12 10:51:55.157 | DEBUG | feathr._databricks_submission:wait_for_completion:176 - Current Spark job status: PENDING 2022-05-12 10:52:25.207 | DEBUG | feathr._databricks_submission:wait_for_completion:176 - Current Spark job status: RUNNING 2022-05-12 10:52:55.276 | DEBUG | feathr._databricks_submission:wait_for_completion:176 - Current Spark job status: FAILED 2022-05-12 10:52:55.461 | ERROR | feathr._databricks_submission:wait_for_completion:186 - Feathr job has failed. Please visit this page to view error message: https://adb-4178042254664494.14.azuredatabricks.net/?o=4178042254664494#job/910603088957422/run/1230 2022-05-12 10:52:55.462 | ERROR | feathr._databricks_submission:wait_for_completion:188 - Error Code: AnalysisException: Undefined function: to_unix_timestamp. This function is neither a built-in/temporary function, nor a persistent function that is qualified as spark_catalog.default.to_unix_timestamp.; line 4 pos 0 2022-05-12 10:52:55.462 | ERROR | feathr._databricks_submission:wait_for_completion:190 - at org.apache.spark.sql.errors.QueryCompilationErrors$.noSuchFunctionError(QueryCompilationErrors.scala:1794) at org.apache.spark.sql.catalyst.analysis.Analyzer$LookupFunctions$$anonfun$apply$24.applyOrElse(Analyzer.scala:2750) at org.apache.spark.sql.catalyst.analysis.Analyzer$LookupFunctions$$anonfun$apply$24.applyOrElse(Analyzer.scala:2736) at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$1(TreeNode.scala:565) at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:167) at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:565) at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$3(TreeNode.scala:570) at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren(TreeNode.scala:1216) at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren$(TreeNode.scala:1215) at org.apache.spark.sql.catalyst.expressions.UnaryExpression.mapChildren(Expression.scala:552) at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:570) at org.apache.spark.sql.catalyst.plans.QueryPlan.$anonfun$transformExpressionsDownWithPruning$1(QueryPlan.scala:161) at org.apache.spark.sql.catalyst.plans.QueryPlan.$anonfun$mapExpressions$1(QueryPlan.scala:202) at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:167) at org.apache.spark.sql.catalyst.plans.QueryPlan.transformExpression$1(QueryPlan.scala:202) at org.apache.spark.sql.catalyst.plans.QueryPlan.recursiveTransform$1(QueryPlan.scala:213) at org.apache.spark.sql.catalyst.plans.QueryPlan.$anonfun$mapExpressions$3(QueryPlan.scala:218) at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:286) at scala.collection.immutable.List.foreach(List.scala:431) at scala.collection.TraversableLike.map(TraversableLike.scala:286) at scala.collection.TraversableLike.map$(TraversableLike.scala:279) at scala.collection.immutable.List.map(List.scala:305) at org.apache.spark.sql.catalyst.plans.QueryPlan.recursiveTransform$1(QueryPlan.scala:218) at org.apache.spark.sql.catalyst.plans.QueryPlan.$anonfun$mapExpressions$4(QueryPlan.scala:223) at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:408) at org.apache.spark.sql.catalyst.plans.QueryPlan.mapExpressions(QueryPlan.scala:223) at org.apache.spark.sql.catalyst.plans.QueryPlan.transformExpressionsDownWithPruning(QueryPlan.scala:161) at org.apache.spark.sql.catalyst.plans.QueryPlan.transformExpressionsWithPruning(QueryPlan.scala:132) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveExpressionsWithPruning$1.applyOrElse(AnalysisHelper.scala:246) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$$anonfun$resolveExpressionsWithPruning$1.applyOrElse(AnalysisHelper.scala:245) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.$anonfun$resolveOperatorsDownWithPruning$2(AnalysisHelper.scala:171) at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:167) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.$anonfun$resolveOperatorsDownWithPruning$1(AnalysisHelper.scala:171) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.allowInvokingTransformsInAnalyzer(AnalysisHelper.scala:324) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperatorsDownWithPruning(AnalysisHelper.scala:169) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperatorsDownWithPruning$(AnalysisHelper.scala:165) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperatorsDownWithPruning(LogicalPlan.scala:30) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperatorsWithPruning(AnalysisHelper.scala:99) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperatorsWithPruning$(AnalysisHelper.scala:96) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperatorsWithPruning(LogicalPlan.scala:30) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveExpressionsWithPruning(AnalysisHelper.scala:245) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveExpressionsWithPruning$(AnalysisHelper.scala:243) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveExpressionsWithPruning(LogicalPlan.scala:30) at org.apache.spark.sql.catalyst.analysis.Analyzer$LookupFunctions$.apply(Analyzer.scala:2736) at org.apache.spark.sql.catalyst.analysis.Analyzer$LookupFunctions$.apply(Analyzer.scala:2730) at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$3(RuleExecutor.scala:216) at com.databricks.spark.util.FrameProfiler$.record(FrameProfiler.scala:80) at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$2(RuleExecutor.scala:216) at scala.collection.IndexedSeqOptimized.foldLeft(IndexedSeqOptimized.scala:60) at scala.collection.IndexedSeqOptimized.foldLeft$(IndexedSeqOptimized.scala:68) at scala.collection.mutable.WrappedArray.foldLeft(WrappedArray.scala:38) at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$1(RuleExecutor.scala:213) at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$execute$1$adapted(RuleExecutor.scala:205) at scala.collection.immutable.List.foreach(List.scala:431) at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:205) at org.apache.spark.sql.catalyst.analysis.Analyzer.org$apache$spark$sql$catalyst$analysis$Analyzer$$executeSameContext(Analyzer.scala:301) at org.apache.spark.sql.catalyst.analysis.Analyzer.$anonfun$execute$1(Analyzer.scala:294) at org.apache.spark.sql.catalyst.analysis.AnalysisContext$.withNewAnalysisContext(Analyzer.scala:196) at org.apache.spark.sql.catalyst.analysis.Analyzer.execute(Analyzer.scala:294) at org.apache.spark.sql.catalyst.analysis.Analyzer.execute(Analyzer.scala:222) at org.apache.spark.sql.catalyst.rules.RuleExecutor.$anonfun$executeAndTrack$1(RuleExecutor.scala:184) at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:126) at org.apache.spark.sql.catalyst.rules.RuleExecutor.executeAndTrack(RuleExecutor.scala:184) at org.apache.spark.sql.catalyst.analysis.Analyzer.$anonfun$executeAndCheck$1(Analyzer.scala:274) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.markInAnalyzer(AnalysisHelper.scala:331) at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:273) at org.apache.spark.sql.execution.QueryExecution.$anonfun$analyzed$1(QueryExecution.scala:128) at com.databricks.spark.util.FrameProfiler$.record(FrameProfiler.scala:80) at org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:151) at org.apache.spark.sql.execution.QueryExecution.$anonfun$executePhase$1(QueryExecution.scala:262) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:958) at org.apache.spark.sql.execution.QueryExecution.executePhase(QueryExecution.scala:262) at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:129) at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:126) at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:118) at org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:103) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:958) at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:101) at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:793) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:958) at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:788) at com.linkedin.feathr.swj.SlidingWindowJoin$.addLabelDataCols(SlidingWindowJoin.scala:109) at com.linkedin.feathr.swj.SlidingWindowJoin$.join(SlidingWindowJoin.scala:31) at com.linkedin.feathr.offline.swa.SlidingWindowAggregationJoiner.$anonfun$joinWindowAggFeaturesAsDF$12(SlidingWindowAggregationJoiner.scala:218) at com.linkedin.feathr.offline.swa.SlidingWindowAggregationJoiner.$anonfun$joinWindowAggFeaturesAsDF$12$adapted(SlidingWindowAggregationJoiner.scala:163) at scala.collection.Iterator.foreach(Iterator.scala:943) at scala.collection.Iterator.foreach$(Iterator.scala:943) at scala.collection.AbstractIterator.foreach(Iterator.scala:1431) at scala.collection.IterableLike.foreach(IterableLike.scala:74) at scala.collection.IterableLike.foreach$(IterableLike.scala:73) at scala.collection.AbstractIterable.foreach(Iterable.scala:56) at com.linkedin.feathr.offline.swa.SlidingWindowAggregationJoiner.joinWindowAggFeaturesAsDF(SlidingWindowAggregationJoiner.scala:163) at com.linkedin.feathr.offline.join.DataFrameFeatureJoiner.joinSWAFeatures(DataFrameFeatureJoiner.scala:324) at com.linkedin.feathr.offline.join.DataFrameFeatureJoiner.joinFeaturesAsDF(DataFrameFeatureJoiner.scala:195) at com.linkedin.feathr.offline.client.FeathrClient.joinFeaturesAsDF(FeathrClient.scala:266) at com.linkedin.feathr.offline.client.FeathrClient.doJoinObsAndFeatures(FeathrClient.scala:185) at com.linkedin.feathr.offline.job.FeatureJoinJob$.getFeathrClientAndJoinFeatures(FeatureJoinJob.scala:115) at com.linkedin.feathr.offline.job.FeatureJoinJob$.feathrJoinRun(FeatureJoinJob.scala:163) at com.linkedin.feathr.offline.job.FeatureJoinJob$.run(FeatureJoinJob.scala:68) at com.linkedin.feathr.offline.job.FeatureJoinJob$.main(FeatureJoinJob.scala:314) at $line213b2342dfcc4c9dbb5b41bd4b23135425.$read$$iw$$iw$$iw$$iw$$iw$$iw.(command--1:1) at $line213b2342dfcc4c9dbb5b41bd4b23135425.$read$$iw$$iw$$iw$$iw$$iw. (command--1:43) at $line213b2342dfcc4c9dbb5b41bd4b23135425.$read$$iw$$iw$$iw$$iw. (command--1:45) at $line213b2342dfcc4c9dbb5b41bd4b23135425.$read$$iw$$iw$$iw. (command--1:47) at $line213b2342dfcc4c9dbb5b41bd4b23135425.$read$$iw$$iw. (command--1:49) at $line213b2342dfcc4c9dbb5b41bd4b23135425.$read$$iw. (command--1:51) at $line213b2342dfcc4c9dbb5b41bd4b23135425.$read. (command--1:53) at $line213b2342dfcc4c9dbb5b41bd4b23135425.$read$. (command--1:57) at $line213b2342dfcc4c9dbb5b41bd4b23135425.$read$. (command--1) at $line213b2342dfcc4c9dbb5b41bd4b23135425.$eval$.$print$lzycompute( :7) at $line213b2342dfcc4c9dbb5b41bd4b23135425.$eval$.$print( :6) at $line213b2342dfcc4c9dbb5b41bd4b23135425.$eval.$print( ) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at scala.tools.nsc.interpreter.IMain$ReadEvalPrint.call(IMain.scala:747) at scala.tools.nsc.interpreter.IMain$Request.loadAndRun(IMain.scala:1020) at scala.tools.nsc.interpreter.IMain.$anonfun$interpret$1(IMain.scala:568) at scala.reflect.internal.util.ScalaClassLoader.asContext(ScalaClassLoader.scala:36) at scala.reflect.internal.util.ScalaClassLoader.asContext$(ScalaClassLoader.scala:116) at scala.reflect.internal.util.AbstractFileClassLoader.asContext(AbstractFileClassLoader.scala:41) at scala.tools.nsc.interpreter.IMain.loadAndRunReq$1(IMain.scala:567) at scala.tools.nsc.interpreter.IMain.interpret(IMain.scala:594) at scala.tools.nsc.interpreter.IMain.interpret(IMain.scala:564) at com.databricks.backend.daemon.driver.DriverILoop.execute(DriverILoop.scala:219) at com.databricks.backend.daemon.driver.ScalaDriverLocal.$anonfun$repl$1(ScalaDriverLocal.scala:225) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at com.databricks.backend.daemon.driver.DriverLocal$TrapExitInternal$.trapExit(DriverLocal.scala:971) at com.databricks.backend.daemon.driver.DriverLocal$TrapExit$.apply(DriverLocal.scala:924) at com.databricks.backend.daemon.driver.ScalaDriverLocal.repl(ScalaDriverLocal.scala:225) at com.databricks.backend.daemon.driver.DriverLocal.$anonfun$execute$11(DriverLocal.scala:605) at com.databricks.logging.Log4jUsageLoggingShim$.$anonfun$withAttributionContext$1(Log4jUsageLoggingShim.scala:28) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62) at com.databricks.logging.AttributionContext$.withValue(AttributionContext.scala:94) at com.databricks.logging.Log4jUsageLoggingShim$.withAttributionContext(Log4jUsageLoggingShim.scala:26) at com.databricks.logging.UsageLogging.withAttributionContext(UsageLogging.scala:205) at com.databricks.logging.UsageLogging.withAttributionContext$(UsageLogging.scala:204) at com.databricks.backend.daemon.driver.DriverLocal.withAttributionContext(DriverLocal.scala:60) at com.databricks.logging.UsageLogging.withAttributionTags(UsageLogging.scala:240) at com.databricks.logging.UsageLogging.withAttributionTags$(UsageLogging.scala:225) at com.databricks.backend.daemon.driver.DriverLocal.withAttributionTags(DriverLocal.scala:60) at com.databricks.backend.daemon.driver.DriverLocal.execute(DriverLocal.scala:582) at com.databricks.backend.daemon.driver.DriverWrapper.$anonfun$tryExecutingCommand$1(DriverWrapper.scala:615) at scala.util.Try$.apply(Try.scala:213) at com.databricks.backend.daemon.driver.DriverWrapper.tryExecutingCommand(DriverWrapper.scala:607) at com.databricks.backend.daemon.driver.DriverWrapper.executeCommandAndGetError(DriverWrapper.scala:526) at com.databricks.backend.daemon.driver.DriverWrapper.executeCommand(DriverWrapper.scala:561) at com.databricks.backend.daemon.driver.DriverWrapper.runInnerLoop(DriverWrapper.scala:431) at com.databricks.backend.daemon.driver.DriverWrapper.runInner(DriverWrapper.scala:374) at com.databricks.backend.daemon.driver.DriverWrapper.run(DriverWrapper.scala:225) at java.lang.Thread.run(Thread.java:748)
Thanks for reporting. A quick workaround is - can you try to use a non-ML cluster?
I also got similar error report from another use case. The steps are: Use a databricks pool to submit the jobs. For the first time, the job run will be successful. However the same pool will throw out the above error message if you run the job second times. The issue will be gone if the pool restarts.
I'll have someone fix this issue.
Sorry I should have specified, this was with non-ML clusters. To be thorough I've ran the notebook on ML clusters with runtimes 9.1 and 10.4 with no GPU, and both run perfectly until cell 38 materializing the features where I get the same to_unix_timestamp function error.
I can also confirm the similar error report - the cell calling client.get_offline_features only fails if the cluster has been used to submit a job before, if the cluster has just been started then that cell runs without issue. This behaviour is consistent across the runtimes I've tried so that part of my initial issue was incorrect.
The later client.materialize_features cell still fails regardless of whether jobs have been submitted to the cluster beforehand.
Thanks for your help so far
We are working with Azure Databricks team to understand if this happens at the cluster level and any workaround for this.