etcd
 etcd copied to clipboard
etcd copied to clipboard
ETCD fails to come up when using CIFS file share (as etcd storage) and with cache=none in mount option
What happened?
I had etcd:3.4.15-debian-10-r43 running and mounted a cifs file sharing with below mount option. Please note cache=none
rw,relatime,vers=3.1.1,cache=none,username=myname,uid=0,noforceuid,gid=1001,forcegid,addr=1.10.90.14,file_mode=0777,dir_mode=0777,soft,persistenthandles,nounix,serverino,mapposix,mfsymlinks,rsize=1048576,wsize=1048576,bsize=1048576,echo_interval=60,actimeo=30
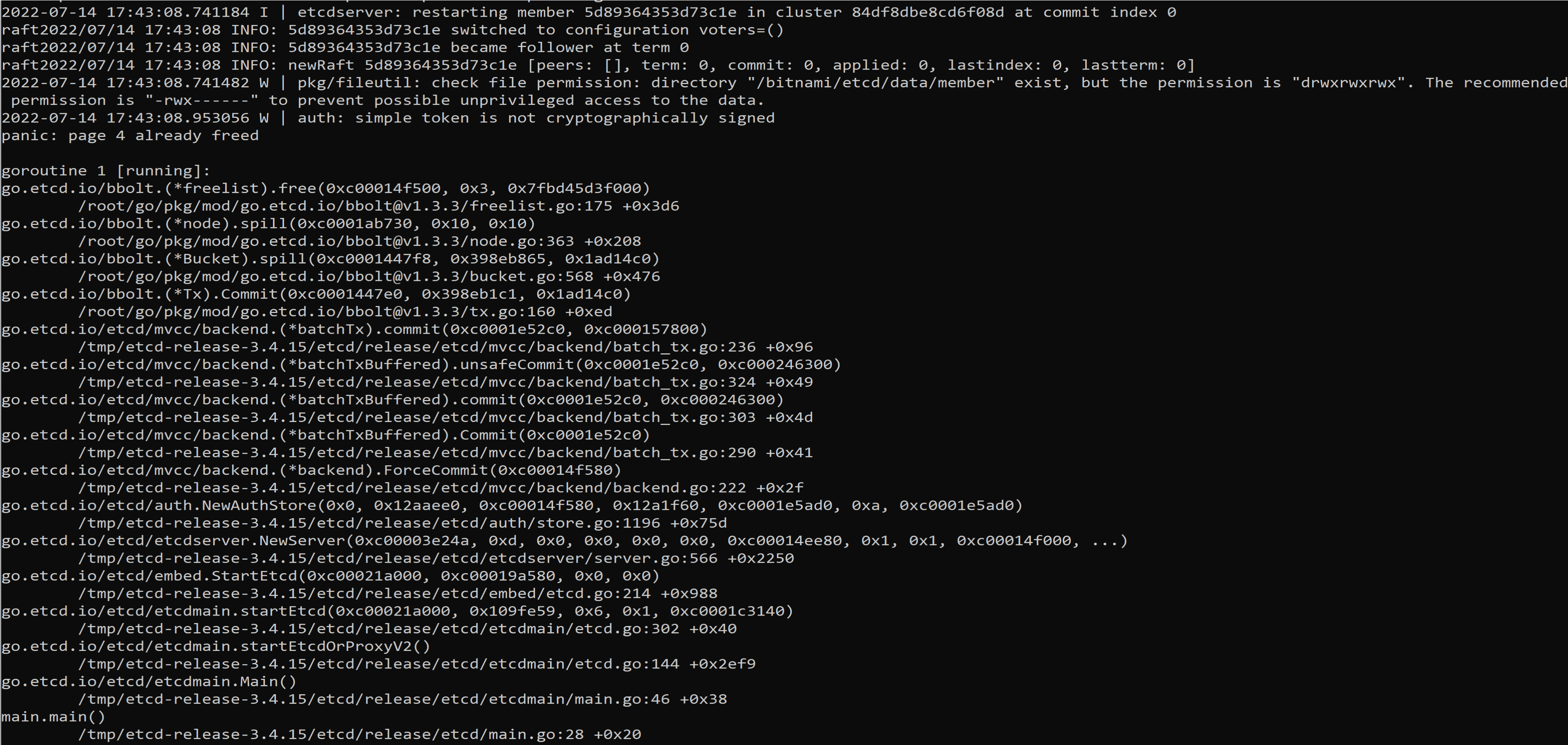
The etcd is failing to comeup with below panic
Since per discussion in https://github.com/etcd-io/etcd/issues/9670 , I tried cache=none for cifs. With same mount option, if I make it cache=strict, everything works fine.
What did you expect to happen?
Etcd must not panic
How can we reproduce it (as minimally and precisely as possible)?
Its very straightforward with the given mount option
Anything else we need to know?
No response
Etcd version (please run commands below)
$ etcd --version
# paste output here
$ etcdctl version
# paste output here
etcdctl version: 3.4.15 API version: 3.4
Etcd configuration (command line flags or environment variables)
paste your configuration here
Etcd debug information (please run commands blow, feel free to obfuscate the IP address or FQDN in the output)
$ etcdctl member list -w table
# paste output here
$ etcdctl --endpoints=<member list> endpoint status -w table
# paste output here
Relevant log output
In the screenshot
why use cifs as etcd storage? any benefits from cifs? it keep fsync on directory. CIFS mount with cache=none caused read very slow.
this is not bug, this is default behavior or you can use below params ./etcd --unsafe-no-fsync
-
We are looking at to ensure data is not lost due to cache. So trying with cache=none
-
When you say this is default behaviour, the panic is expected?
this is not bug, this is default behavior
- We are looking at to ensure data is not lost due to cache. So trying with cache=none
- When you say this is default behaviour, the panic is expected?
this is not bug, this is default behavior
for question 2, the panic is expected. see source code: https://github.com/etcd-io/bbolt/blob/master/freelist.go#L175
Meanwhile, I need fsync to happen. What I am looking for is, if I have cache enabled with CIFS, there is a potential possibility of data loss. So I tried disabling cache.
But --unsafe-no-fsync means, dont do fsync correct? A put(key,value), must write to the stable storage immediately. If my understanding is correct I cant use --unsafe-no-fsync flag.
@xiaods FYI I tried using cache=none option along with --unsafe-no-fsync. Didnt help.
unsafe-no-fsync
sad news, i review and see the --unsafe-no-fsync comments, it warning: "Disables fsync, unsafe, will cause data loss" so it's not match your requirements. don't use it anymore.
Can anyone help me how do I stop etcd/bbolt panicking from given cifs + cache=none option?
hey @hasethuraman,
I've been looking a bit into this today, since I have a samba share at home and wanted to debug bbolt a little. I don't have a fix for you just yet, but I just want to mentally write down what I found so far.
The panic can be easily reproduced by running this simple test case on the share: https://github.com/etcd-io/bbolt/blob/master/manydbs_test.go#L33-L60
The panic is caused by a bucket that is not found after it was created in this method: https://github.com/etcd-io/bbolt/blob/master/bucket.go#L165-L183
The cursor seek does not return an existing bucket for the root node, thus it will create a new one with the same page id, which causes the panic on the freelist.
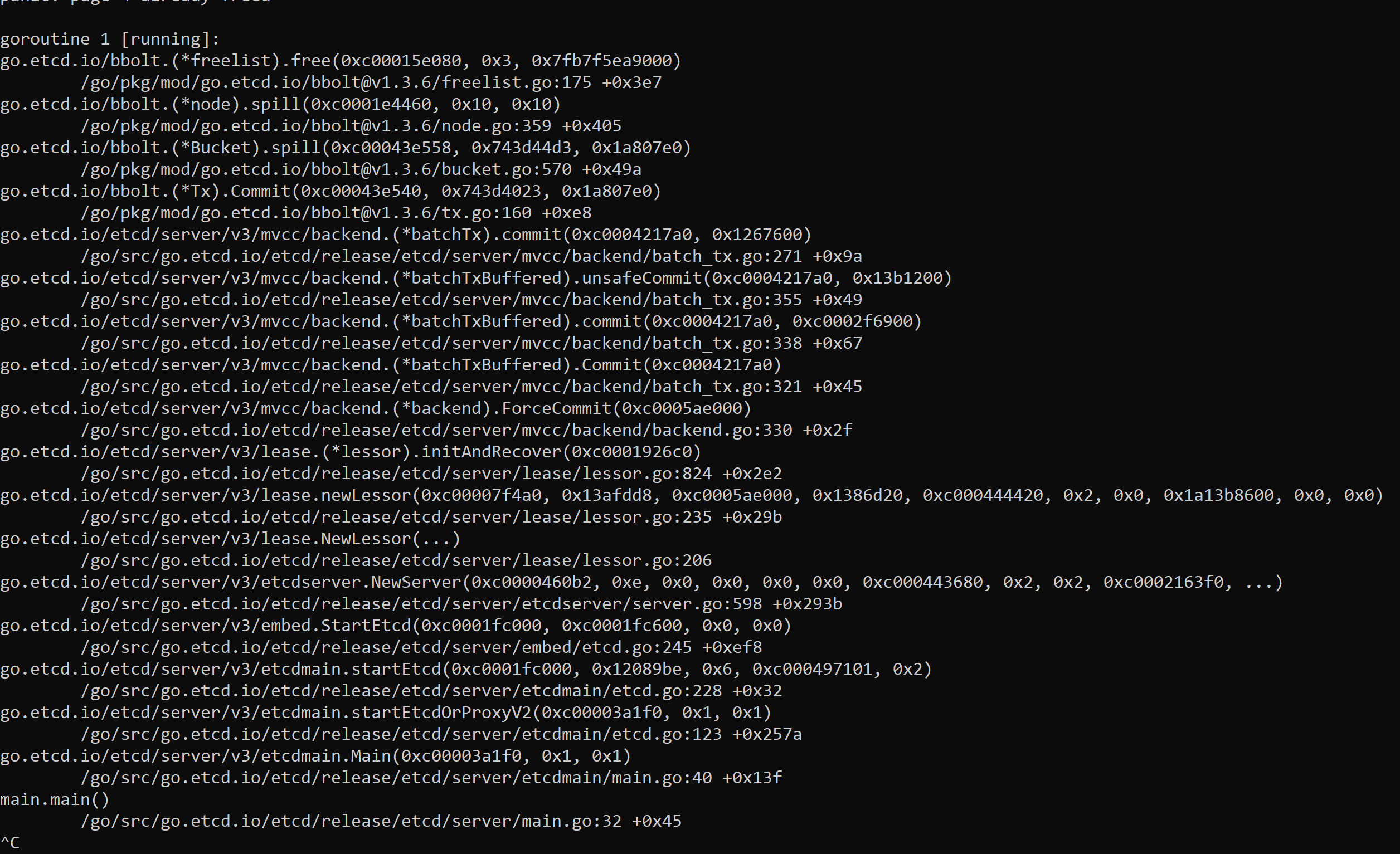
@hasethuraman @tjungblu could you try to reproduce this issue with etcd 3.5.4?
I will try this in 3.5.4 too
I spent some time and kind of getting some direction. When we have the cache=none, it looks like the page cache wont reflect (mmap) any changes as the latest commits flushes to the db; as page cache wont reflect (because of cache is disabled) the db.meta will never reflect new page id and so the free will try to release the same page (since db.meta still points to same pageid) causing this panic.
yep that's about it, the guarantees for mmap are different via CIFS with cache=none.
@hasethuraman @tjungblu could you try to reproduce this issue with etcd 3.5.4?
Yes, but it's not really related to an etcd version, it is due to the mmap usage of bbolt.
I tried to see if refreshing the first two pages (length = 2*4KB in my case) can help in tx.init(). It throws invalid arg. Everything looks good. Any other way I can try a fix locally to validate my theory?
Syscall6(SYS_REMAP_FILE_PAGES, ptr, uintptr(length), uintptr(syscall.PROT_READ), uintptr(0), uintptr(syscall.MAP_POPULATE|syscall.MAP_SHARED), 0)
Can someone help me in with this below understanding?
- User calls etcdctl put key value
- etcd server first writes to WAL
- then get consensus through RAFT
- RAFT is in progress
- at this point - physical machine restarts and assuming that raft changes were about to flush to permanent storage
- after the server restart, will the entry in WAL be replayed and data loss is avoided?
FYI. https://github.com/ahrtr/etcd-issues/blob/master/docs/cncf_storage_tag_etcd.md
I will try this in 3.5.4 too
@hasethuraman Have you tried this? What's the test result?
Thank you @ahrtr for sharing. I think that confirms.
I am planning to close the issue because WAL cover up the main reason (data loss) and trying to disable the cache. I will wait for a week and close. Please let me know if any one think that I need to keep this open.
@hasethuraman Have you tried this? What's the test result?
Its the same
Its the same
Please provide the log and panic call stack for 3.5.4.
Please provide the following info,
- Just to double confirm, you are running etcd on a Linux server, but the data-dir is actually mounted CIFS, correct?
- Please clean up all directories & file in the etcd data dir (
--data-dir), and try to start the etcd 3.5.4. Afterwards, provide the log and panic call stack if any.
I tried to setup a CIFS on a linux server, but failed somehow:-(. I am not sure if it's possible for someone share a CIFS share for me to debug this.
Previously based on the discussion in https://github.com/etcd-io/etcd/issues/9670, CIFS doesn't support sync. Not sure whether it's still the case. Would love to double confirm it if possible.
@ahrtr I dont see any difference in call stack. Atleast with the CIFS (cache=strict) I tried, I dont see any error related to sync.
@ahrtr do you think we can document before closing this defect? I dont know if etcd or boltdb can cover up this issue.
Probably we can add a known issues section in boltDB/README.md.
BoltDB doesn't work with CIFS file share mounted with cache=none, but it works with CIFS mounted with cache=strict.
What do you think? @spzala
This issue has been automatically marked as stale because it has not had recent activity. It will be closed after 21 days if no further activity occurs. Thank you for your contributions.