dgraph-operator-archive
 dgraph-operator-archive copied to clipboard
dgraph-operator-archive copied to clipboard
Feature Request: Support for Bulk Loading
We'd like to use a k8s dgraph operator and bulk loading is part of our primary use case. So, I don't think we could use the operator much if there is no bulk loading support. Similarly, I'd expect others would find a general bulk loading solution valuable in the operator?
Bulk Loading Overview: A zero within the cluster needs to read in the bulk data to generate any UIDs and create the binary data the alpha will read. After this data is transferred to the alphas, the alphas can be started. It is up to the user to decide on replication and sharding and to transfer sharded data to the correct alpha groups.
The following is an implementation suggestion using custom alpha init container + custom zero sidecar container. This is a little more complex than I'd like and the complexity results from these bulk loader requirements:
- The alpha cannot start until after bulk loading
- The zero that does the bulk loading must be the same zero that the alphas use in the cluster.
If either of these requirements is removed, the bulk loading orchestration could be simpler.
The dgraph cluster can be created as desired by the user (number of replicas, shards, cpu/mem/storage resources) and the cluster will start up and wait for the zero sidecar and alpha init containers to finish the bulk loading orchestration (related to https://github.com/dgraph-io/dgraph/blob/d84551febd87aff1600851a18f58dae63296158d/contrib/config/kubernetes/dgraph-ha/dgraph-ha.yaml#L239). The custom containers allow for custom logic supporting different ways to pull raw data and load it into the alphas.
Zero Sidecar Behavior I'm assuming that only 1 zero needs to be used to run bulk loading for all alpha groups. The pod should continue running when this sidecar exits normally.
- If this isn't the 0th pod, or if the bulk loader has already ran, exit 0
- Generate and/or pull down bulk data in raw format (could be RDF, SQL, JSON, CSV, etc)
- If need be, convert that data to RDF or JSON (whatever is fed to the dgraph bulk loader)
- Run the bulk loader against the zero at localhost
- Write the data to external storage, or possibly to the alphas directly.
- exit 0
alpha init container behavior:
- If the data is already loaded, exit 0
- Wait for dgraph binary data to be available in the expected location for this custom workflow, be it remote or local storage.
- If need be, copy the data locally e.g. to
/dgraph - exit 0
Here's a diagram of how this might look:
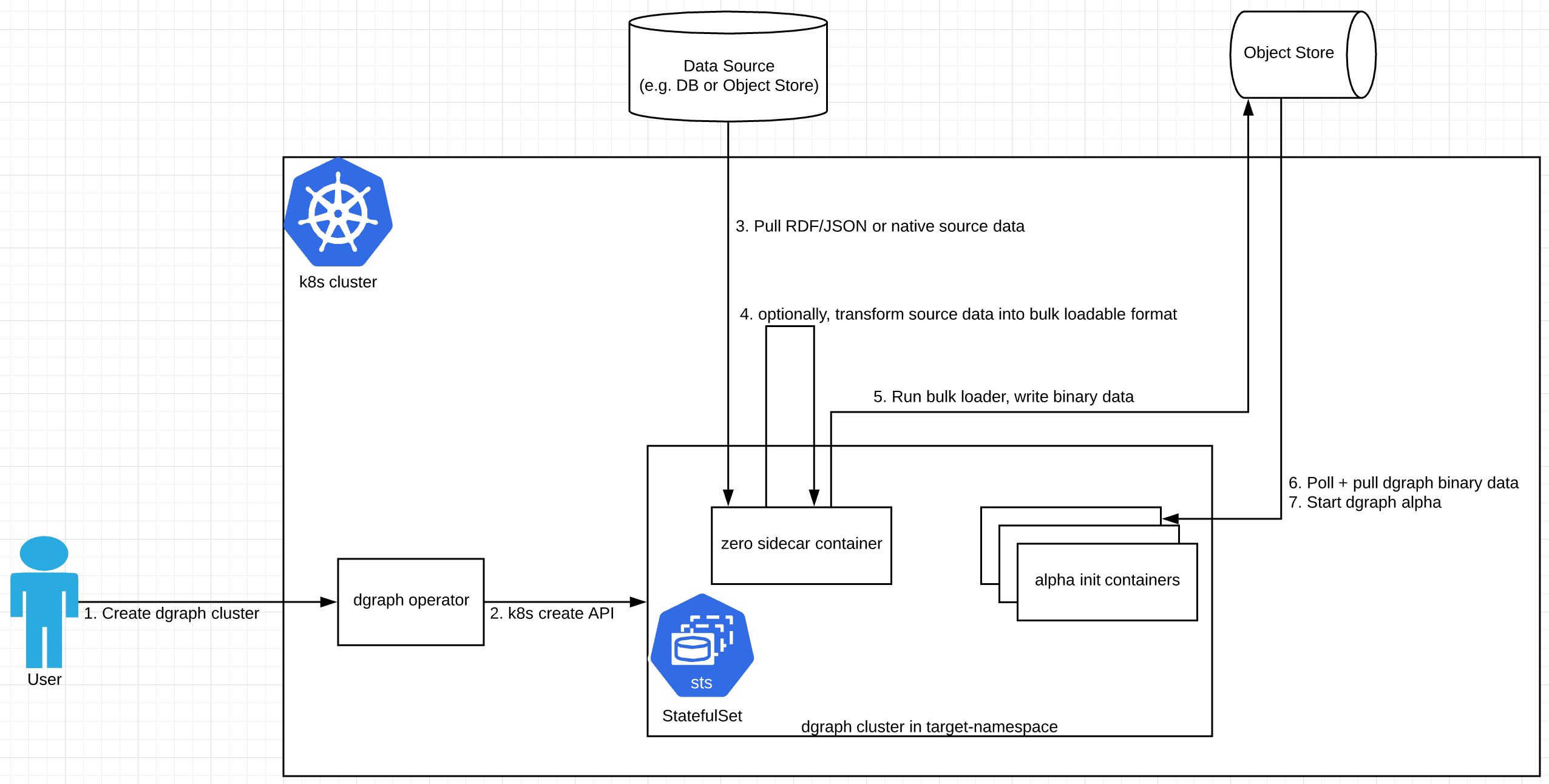
Custom container requirements (k8s statefulset spec): The custom zero and alpha containers will need ability to load custom secrets (env vars or files), maybe config maps, and pod volumes (for file-based secrets or even raw data?). So the operator would need to allow customizations to the statefulset object to allow such workflows.
Is your bulk loading workflow different than what's done with initContainers approach in the dgraph-ha.yaml K8s sample config? https://github.com/dgraph-io/dgraph/blob/v1.1.1/contrib/config/kubernetes/dgraph-ha/dgraph-ha.yaml#L219-L260
Yes it's different, but it's similar to that approach. In my example above, the init container will not just wait for the data to appear (as in your url), but it will poll an object store for the data.
In addition there is a zero sidecar container that will run the bulk loader against the zero and then upload it to the object store for the alpha init container to consume.
The alpha init logic and the zero sidecar logic will be different depending on the data source and object store, hence the need for custom containers. These containers may also have runtime requirements like secret volumes, env vars, image pull secrets and such. Surfacing all these customizations of the statefulsets admittedly doesn't seem very simple. I'm open to simpler approaches that accomplish the same goal.
I'm working on a proof-of-concept for the kind of bulk loading logic I described above, I'll report back if it works :-).
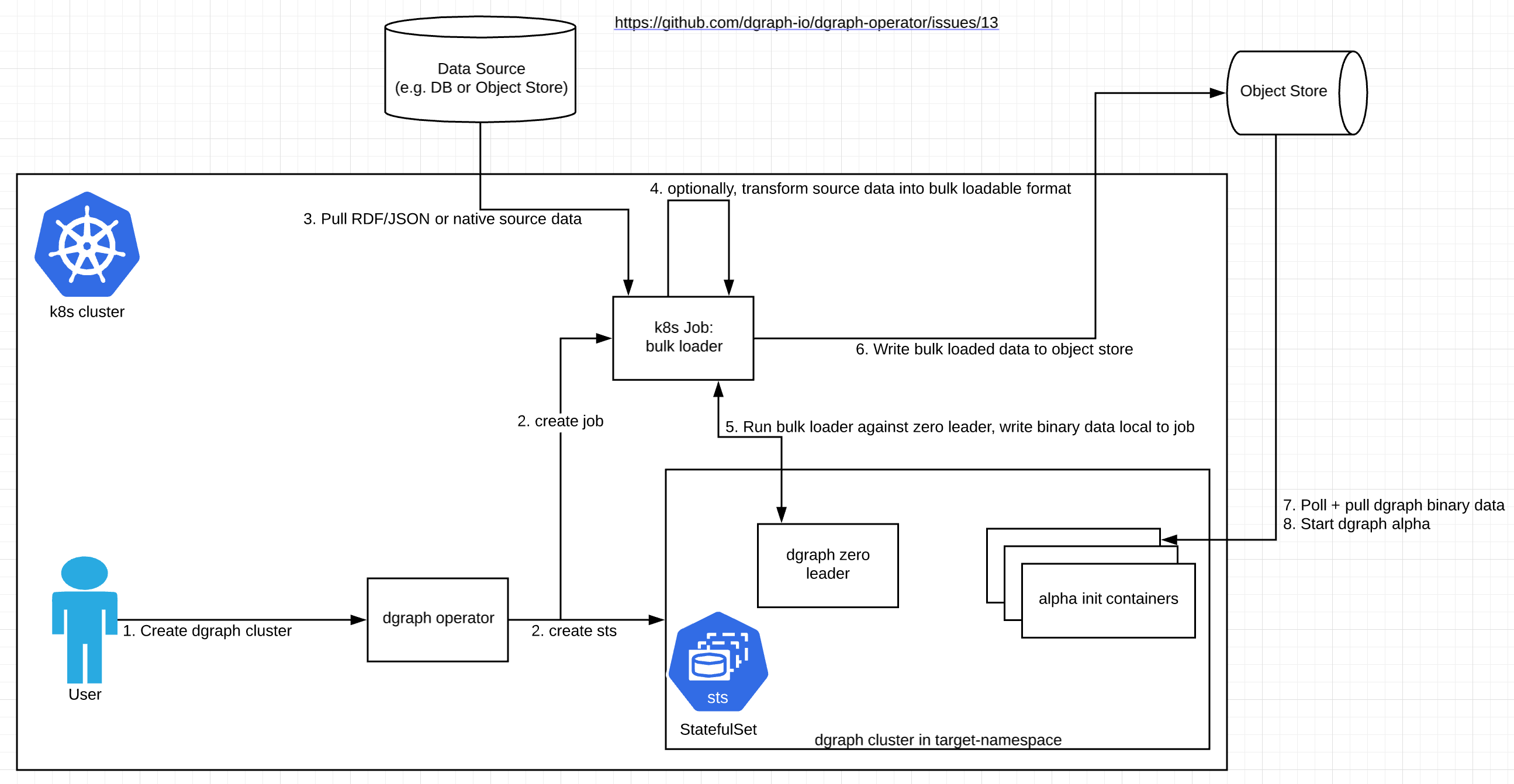
Reporting back that the proof of concept does indeed work, but I've learned some things along the way and I'm going to change my approach above. Instead of a zero sidecar, I'm recommending creating a kubernetes Job for the following reasons:
- we only need to run the bulk loader in one process (not 3 as is the default the case with zero sidecars)
- we cannot let the zero sidecar container exit, or else k8s restarts the whole pod because it's a statefulset (https://github.com/kubernetes/community/issues/458)
- bulk loader needs to talk only with the one dgraph zero leader
- which zero is going to be leader is non-deterministic (please correct me if I'm wrong).
I originally wanted to run the bulk loader as a zero sidecar for reasons of data locality and performance. However, the above issues make this very difficult to accomplish and the Job approach is a much better fit with kuberenetes primitives. Another benefit of this approach is we no longer need to support dgraph-zero podspec customizations just for bulk loading.
The updated diagram looks like this:
If anyone is wondering how to implement a bulk loader in kubernetes, here's some bash from the proof-of-concept that handles the zero coordination (assumes 3 zero nodes):
echo "Waiting for zero cluster to become functional to avoid leader elections causing instability"
num_nodes=$( (curl -sf "http://dgraph-zero:6080/state" || echo '{"zeros": []}') | jq '[.zeros[]] | length')
while [ "$num_nodes" -lt "3" ]; do
echo -n "."
sleep 1
num_nodes=$( (curl -sf "http://dgraph-zero:6080/state" || echo '{"zeros": []}') | jq '[.zeros[]] | length')
done;
leader_host=$(curl -s http://dgraph-zero:6080/state | jq -r '.zeros | map(select(.leader == true))[0].addr')
dgraph bulk -z $leader_host -f dgraph_bulk.gz --format rdf -s schema.dgraph
note: if the zero leader changed during bulk load, I expect the bulk load would fail.