Writing inplace a modified zarr array with dask failed
I read a zarr array, where i need to modify some values. And after i want to save at same place, with overwrite options.
import dask.array as da
from dask.distributed import Client, LocalCluster
import dask
def put_2(data):
# Put 2 at first index of block
data[0] = 2
return data
if __name__ == '__main__':
print('Version ', dask.__version__)
# Bug come, when i used a cluster
cluster = LocalCluster()
client = Client(cluster)
# Create ones matrix with two chunk
d = da.ones(10, chunks=(5,), dtype='i4')
# Save it
d.to_zarr('/tmp/data.zarr', component='d', overwrite=True)
# Read Ones
read_d = da.from_zarr('/tmp/data.zarr', component='d')
# Apply put_2 on each block
new_d = da.blockwise(put_2, 'i', read_d, 'i', dtype='i4')
print(new_d.compute())
# Save inplace of previous array
a = new_d.to_zarr('/tmp/data.zarr', component='d', overwrite='True')
# Read new save :(
read_d = da.from_zarr('/tmp/data.zarr', component='d')
print(read_d.compute())
Output
Version 2.11.0
[2 1 1 1 1 2 1 1 1 1]
[2 0 0 0 0 2 0 0 0 0]
It seems "create" command from zarr is apply before readings value, so when we try to read we get an empty dataset.
@AntSimi thank you for the bug report. I verified similar behavior but noticed that upon multiple runs it sometimes is correct. Not sure what's going on here. Can I ask you to try without distributed ?
I modify example to remove dask distributed:
import dask.array as da
def put_2(data):
# Put a zero at first index of block
data[0] = 2
return data
if __name__ == '__main__':
# Create ones matrix with two chunk
d = da.ones(100, chunks=(5,), dtype='i4')
# Save it
d.to_zarr('/tmp/data.zarr', component='d', overwrite=True)
# Read Ones
read_d = da.from_zarr('/tmp/data.zarr', component='d')
# Apply put_0 on each block
new_d = da.blockwise(put_2, 'i', read_d, 'i', dtype='i4')
# Save inplace of previous array
a = new_d.to_zarr('/tmp/data.zarr', component='d', overwrite='True', compute=False)
# a.visualize('tree.png')
a.compute()
# Read new save :(
read_d = da.from_zarr('/tmp/data.zarr', component='d')
d = read_d.compute()
print(d)
print((d!=0).all())
Several outputs
...@...:$ python zarr_dask_over_write.py
[2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1
1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1
1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1]
True
(...@...:$ python zarr_dask_over_write.py
[2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1
1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 0 0 0 0 2 0 0 0 0 2 0 0 0
0 2 0 0 0 0 2 0 0 0 0 2 0 0 0 0 2 0 0 0 0 2 0 0 0 0]
False
...@...:$ python zarr_dask_over_write.py
[2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1
1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1
1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1 2 1 1 1 1]
True
Most of the time result is good, but sometime is wrong with dask.distributed the error occurs more.
My guess is "create" step could occurs aftter or before all "from_zarr" step.
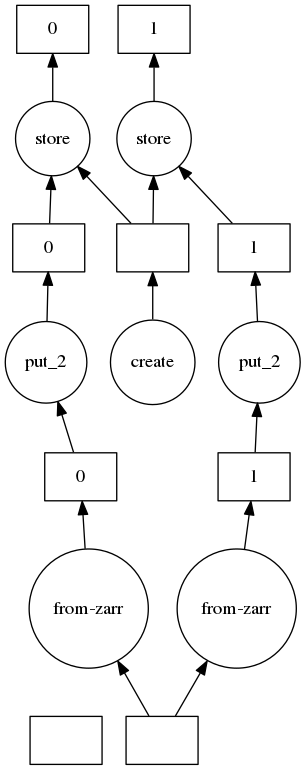 Create step with "overwrite=True" do an "rmdirs".
In my real use i have a dataset which are bigger than memory so i couldn't fully load before create step.
Create step with "overwrite=True" do an "rmdirs".
In my real use i have a dataset which are bigger than memory so i couldn't fully load before create step.
I am taking a look at this now and can only reproduce with the distributed case. I think the issue is happening within the to_zarr method actually. If you add compute=False to the to_zarr, it seems to work as expected:
import dask.array as da
from distributed import Client
client = Client()
def put_2(data):
# Put 2 at first index of block
data[0] = 2
return data
# Create ones matrix with two chunk
d = da.ones(10, chunks=(5,), dtype='i4')
# Save it
d.to_zarr('/tmp/data.zarr', component='d', overwrite=True)
# Read Ones
read_d = da.from_zarr('/tmp/data.zarr', component='d')
# Apply put_2 on each block
new_d = da.blockwise(put_2, 'i', read_d, 'i', dtype='i4')
print(f"NEW: {new_d.compute()}")
# Save inplace of previous array
new_d.to_zarr('/tmp/data.zarr', component='d', overwrite=True, compute=False)
print(f"AFTER WRITE: {new_d.compute()}")
# Read new save :(
read_d = da.from_zarr('/tmp/data.zarr', component='d')
print(f"READ: {read_d.compute()}")
With compute=False I get:
NEW: [2 1 1 1 1 2 1 1 1 1]
AFTER WRITE: [2 1 1 1 1 2 1 1 1 1]
READ: [1 1 1 1 1 1 1 1 1 1]
With compute=True I get:
NEW: [2 1 1 1 1 2 1 1 1 1]
AFTER WRITE: [2 0 0 0 0 2 0 0 0 0]
READ: [2 0 0 0 0 2 0 0 0 0]
I am able to recreate similar error with huge array, original array have only 1 and we put some 2, but several times i found zeros in array
import dask.array as da
def put_2(data):
# Put a zero at first index of block
data[0] = 2
return data
if __name__ == '__main__':
# Create ones matrix with two chunk
d = da.ones(100000000, chunks=(2500000,), dtype='i4')
# Save it
d.to_zarr('/tmp/data.zarr', component='d', overwrite=True)
# Read Ones
read_d = da.from_zarr('/tmp/data.zarr', component='d')
# Apply put_2 on each block
new_d = da.blockwise(put_2, 'i', read_d, 'i', dtype='i4')
# Save inplace of previous array
a = new_d.to_zarr('/tmp/data.zarr', component='d', overwrite='True', compute=False)
a.compute()
# Read new save :(
read_d = da.from_zarr('/tmp/data.zarr', component='d')
d = read_d.compute()
print((d!=0).all())
Print result must be always True, but several time i get False I used python 3.7.10 with dask-core-2021.3.0 and zarr 2.6.1
I was able to get the desired output with this diff:
diff --git a/dask/array/core.py b/dask/array/core.py
index 9aa10950..f45a3619 100644
--- a/dask/array/core.py
+++ b/dask/array/core.py
@@ -3318,10 +3318,9 @@ def to_zarr(
# sharded across workers (not done serially on the originating
# machine). Or the caller may decide later to not to do this
# computation, and so nothing should be written to disk.
- z = delayed(zarr.create)(
- shape=arr.shape,
+ z = delayed(zarr.array)(
+ data=arr,
chunks=chunks,
- dtype=arr.dtype,
store=mapper,
path=component,
overwrite=overwrite,
Would you be able to see if that works for you?
I'm not sure what the implications are for performance, but that seems like a reasonable solution to me. I'll open a PR to carry on the conversation.
After a quick look to dask graph.
I think there will be a problem for array larger than memory, because if i understood correctly the graph all data must be loaded before to start storage.
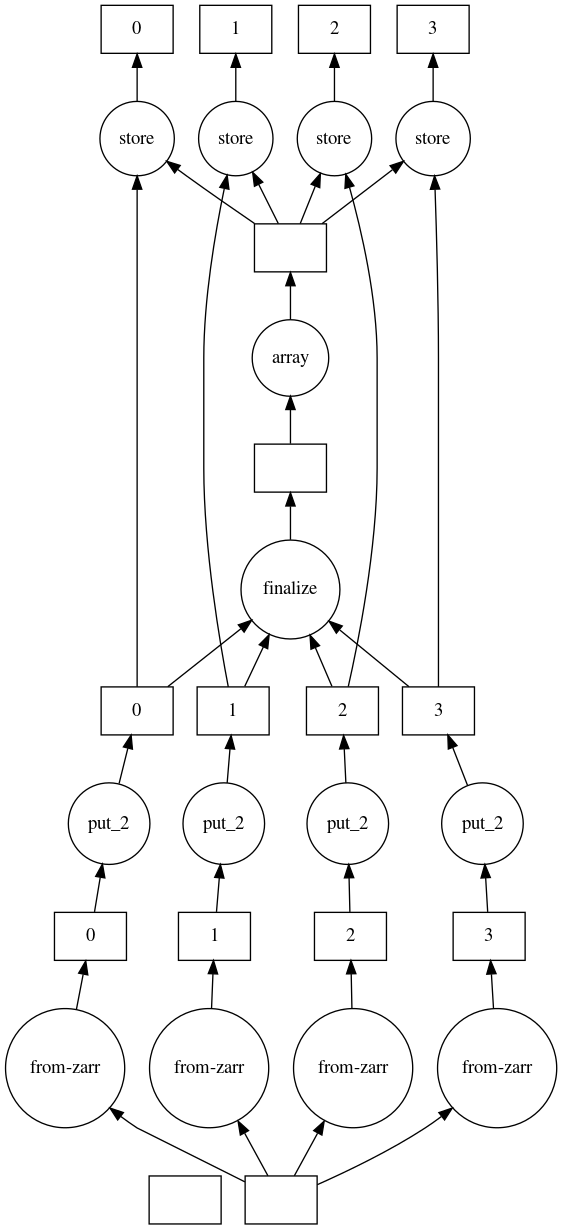
Hi there, quick question: Is this issue considered as closed? The corresponding PR https://github.com/dask/dask/pull/7379 was not brought forward and -if I understand correctly- it would force the whole execution before writing data to disk, which doesn't play well with large data.
I am hitting this issue again: I load large amount of data via from_zarr(), I do some processing, and then I'd like to use to_zarr(..., overwrite=True) - but something goes wrong and I end up with very small files (correct shape and chunks, wrong data).
My current quick&dirty workaround is to save data to a new zarr component and then play with folders (remove old one, move new one to correct path), but it means that I have to create/remove/move large temporary folders (to_zarr can be called to save a 30G array, for instance).
Code:
Click to expand!
import shutil
def to_zarr_custom(newzarrurl=None, array=None, component="", overwrite=False):
"""
Custom workaround for dask issue
(https://github.com/dask/dask/issues/5942), where a dask array loaded with
from_zarr cannot be written with to_zarr(..., overwrite=True).
:param newzarrurl: ouput zarr file
:type newzarrurl: str
:param array: dask array to be stored
:type array: dask array
:param component: target subfolder of the zarr file (optional, default "")
:type component: str
:param overwrite: overwrite existing data (optional, default False)
:type overwrite: boolean
"""
# Check required arguments
if newzarrurl is None:
raise Exception("ERROR: Missing newzarrurl arg in to_zarr_custom")
if array is None:
raise Exception("ERROR: Missing array arg in to_zarr_custom")
# Sanitize arguments
if component.endswith("/"):
component = component[:-1]
if not newzarrurl.endswith("/"):
newzarrurl += "/"
if overwrite:
tmp_suffix = "_TEMPORARY_ZARR_ARRAY"
array.to_zarr(
newzarrurl,
component=component + tmp_suffix,
dimension_separator="/",
)
shutil.rmtree(newzarrurl + component)
shutil.move(
newzarrurl + component + tmp_suffix, newzarrurl + component
)
else:
array.to_zarr(newzarrurl, component=component, dimension_separator="/")
I am happy to provide more context/tests if it is useful, but more generally I'd like to know whether @AntSimi or others found any workaround that they are happy with. Thanks!