asammdf
 asammdf copied to clipboard
asammdf copied to clipboard
Large memory footprint during loading of file
Python version
'python=3.7.6 (default, Dec 30 2019, 19:38:28) \n' '[Clang 11.0.0 (clang-1100.0.33.16)]') 'os=Darwin-18.7.0-x86_64-i386-64bit' 'numpy=1.18.1' 'asammdf=5.18.0'
Code
MDF version
5.18.0
Code snippet
from asammdf import MDF
import sys
@profile
def open_mdf(file_path):
with MDF(name=file_path, version='4.1') as mdf:
data_bytes = mdf.iter_get('GVSP_DataPacket.DataBytes', samples_only=True)
return data_bytes
if __name__ == "__main__":
file_path = sys.argv[1]
open_mdf(file_path)
then runnning mprof run --python python test.py "path/to/mdf.mf4"
Description
We're running into issues when loading a large MDF4 file since it almost requires three times the size of the file during loading.
Below is the memory profiling of running the script on a 1.8 GB file.
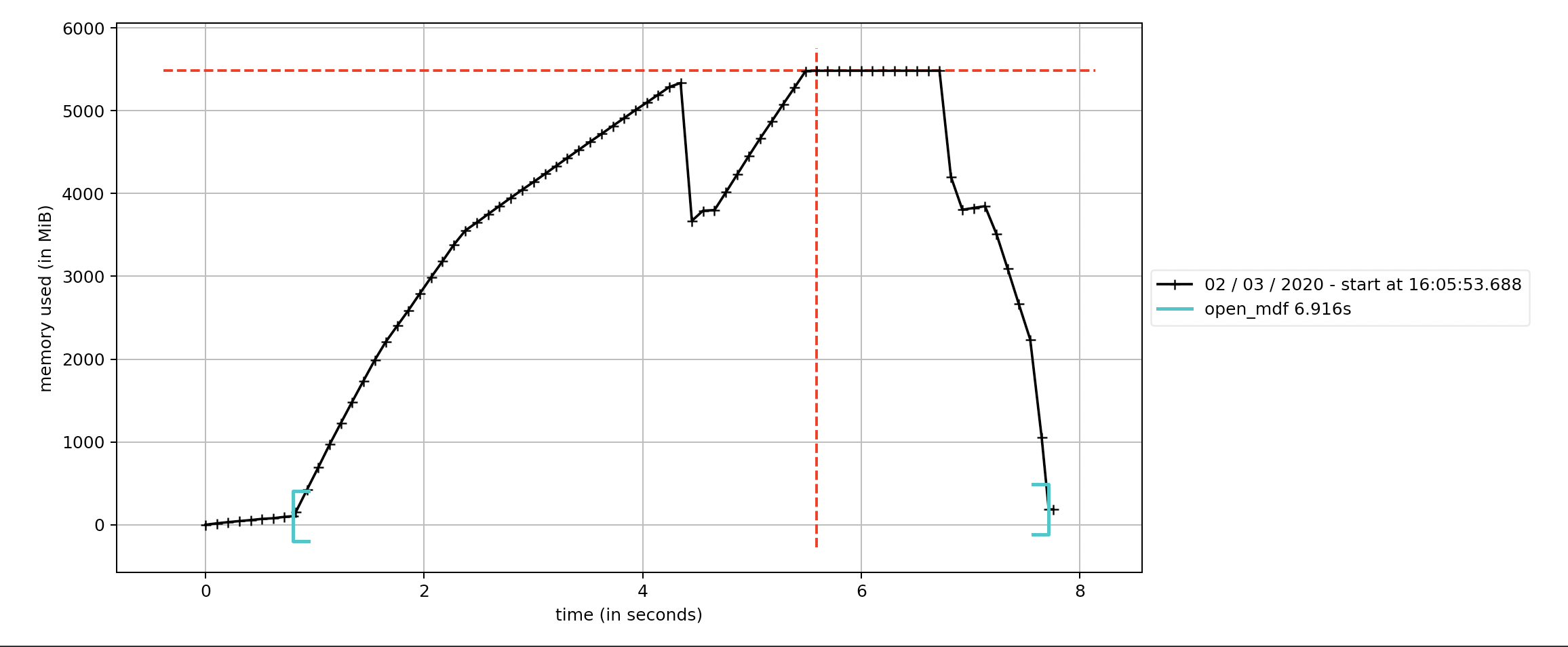
And the following is using mdf.get
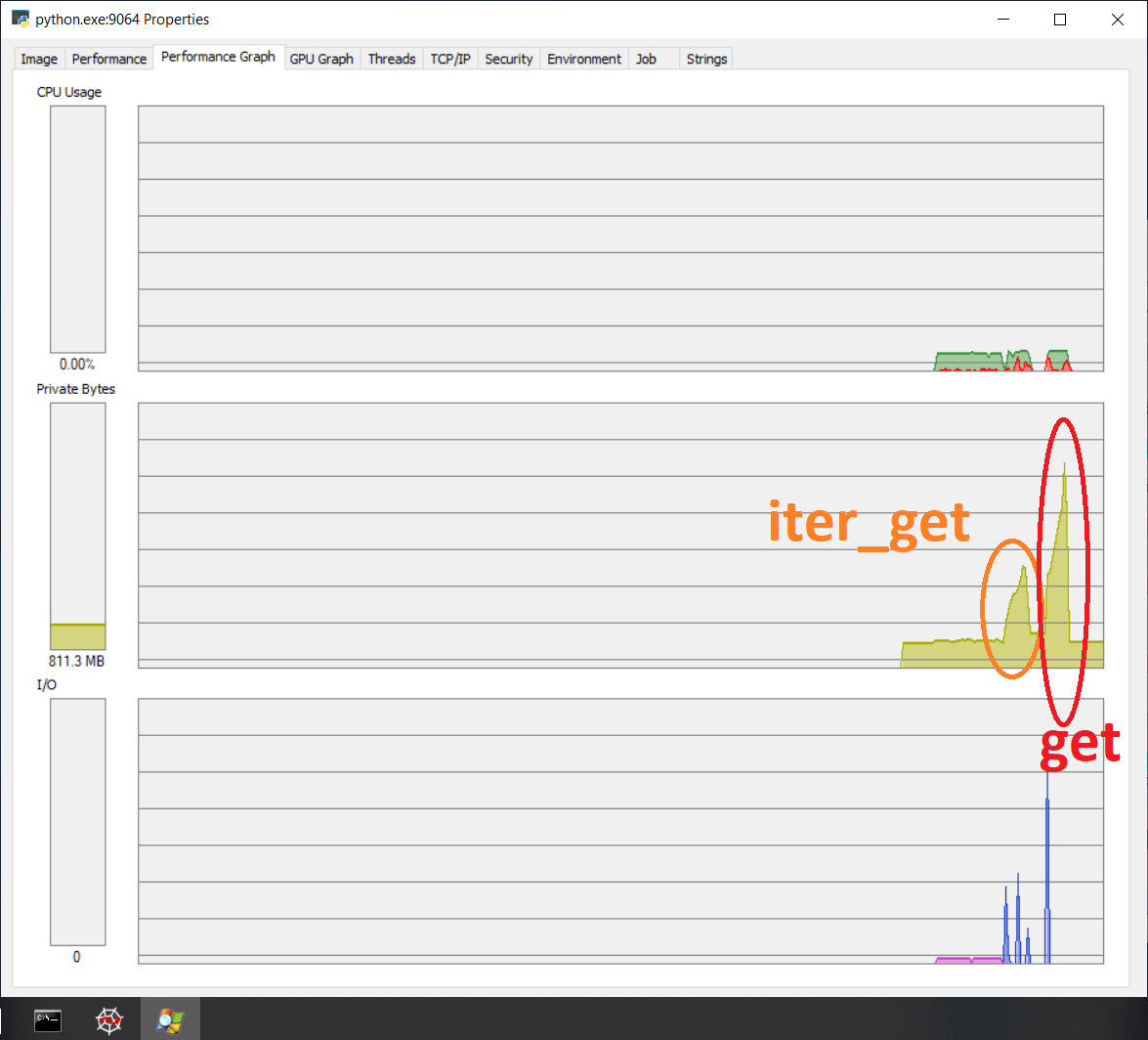
the final memory footprint of mdf.get makes sense, and for iter_get to have a much smaller footprint but what I can't understand is the high memory during loading.
Hello Fredrik,
how many channels does the file contain?
Is this some kind of bus logging? If the measurement is unsorted this might explain the high memory usage
It's uncompressed images (video stream) sent over one channel. The packets are sent in order since each image are sent over several packets.
Any other operation apart from sorting occurring during loading?
Still, how come get and iter_get display the same memory footprint? Is the whole file loaded into memory initially, only then to be discarded afterwards?
Hello Fredrik,
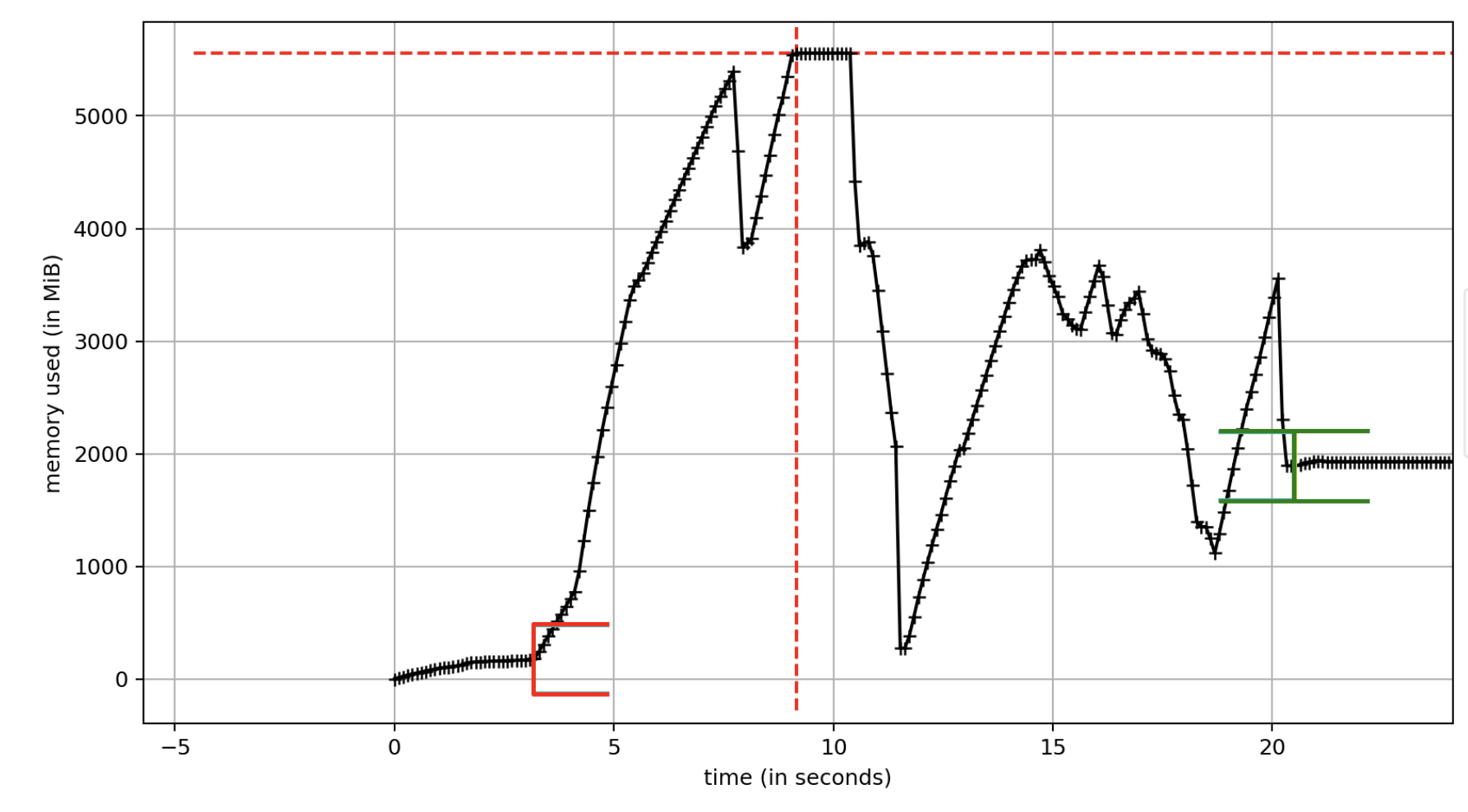
thank you for the file. With the new development branch code you should see a big reduction in memory usage during the file load phase.
Thank you, checked out the development branch and tested. This is using iter_get. I no longer see the large spikes to above 5.3 GB. However, the memory footprint does look large for using iter_get?
Could you elaborate? Does that mean there's no way to stream the databytes for this file? Sort of defeats the purpose with streaming if the file is fully loaded and then discarded?
In that case I would opt in for always using the get method returning the whole array, or am I missing something?
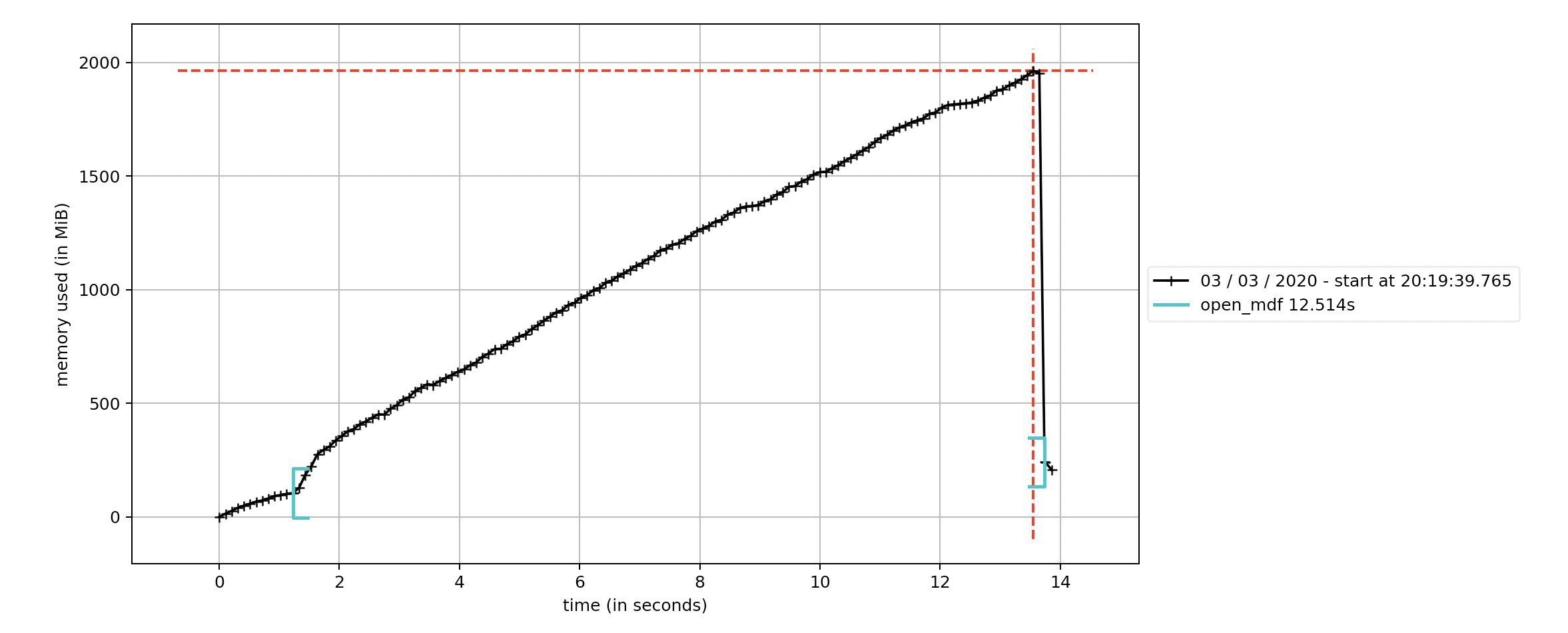
I was curious why the memory footprint grows larger than the file? I'm still peaking at around twice the size of the MDF with get method.
If due to sorting, is it possible to turn off if signals are presorted?
Sorting now is done with chunks of 32MB, while the file is opened.
On get since you have a VLSD channel (don't remember exactly if it was CAN logging or Ethernet logging) if one of the samples has a large byte count this will cause high memory usage since the samples will be loaded in a numpy array, and the item size is equal to the largest byte count
I see, that would be the case for us where all data is found within one sample. But shouldn't we stop at a memory usage equal to the file size then? Or are we keeping the bytes both as numpy array and something else?
This is were the high memory usage is produced; https://github.com/danielhrisca/asammdf/blob/master/asammdf/blocks/mdf_v4.py#L1532
since most of the data comes from the BGSJBKUODQHTDWJVPMAZYAIPA frames (99% of them are 1424 bytes).
So I'm afraid that it is unavoidable in the case of get
@fredrikjacobson I've pushed some optimizations for channels that reference signal data blocks. Please check out the development branch code (6.3.0.dev36)