DNS Resolution Issue in Kubernetes
Summary
Since version 7.0.0, the DNS resolution is no longer properly done in Kubernetes. For example, a resource, such as Git, that refers to an external URL will not be able to read from a remote repository.
Solve the problem as proposed in the documentation will not solve the problem completely. Scripts in the pipelines that refer to URLs local to Kubernetes will not be resolved anymore (e.g. "http://concourse-web.concourse.svc.cluster.local:8080).
In order for the new version of Concourse to be as easy to use as it was before in a Kubernetes environment, it would be nice if workers could get the DNS configuration of their hosts to get the same DNS resolution as in previous versions of Concourse.
This is related to the following issue: https://github.com/concourse/concourse/issues/6544
Steps to reproduce
Here are the details on the environment in which the problem can be reproduced:
- Minikube Version: 1.17.1 (using the VirtualBox driver)
- Kubernetes Version: 1.20.2
- Concourse Helm-Chart Version: 14.6.0
- Concourse Version: 7.0.0
Note: Default values with the Helm Chart will reproduce the issue.
Test Pipeline
resources:
- name: concourse-docs-git
type: git
icon: github
source:
uri: [email protected]:concourse/docs.git
branch: master
git_config:
- name: core.sshCommand
value: "ssh -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no"
private_key: |
-----BEGIN OPENSSH PRIVATE KEY-----
......
-----END OPENSSH PRIVATE KEY-----
jobs:
- name: job
public: true
plan:
- get: concourse-docs-git
trigger: true
- task: list-files
config:
inputs:
- name: concourse-docs-git
platform: linux
image_resource:
type: registry-image
source: { repository: busybox }
run:
path: ls
args: ["-la", "./concourse-docs-git"]
Triaging info
- Concourse version: 7.0.0
- Did this used to work? yes
Just got around to trying to reproduce this and I still can't!!!!?!?!
Followed your setup; minikube version v1.17.1 and k8s 1.20.2 with chart 14.6.2 using default values.yml.
- I modified the pipeline to use https instead of the ssh uri for the repo initially because I didn't want to fetch my private key
- With https the check and get worked. Okay, maybe it's just an ssh problem?
- I then changed the pipeline back to what you had; ssh uri with a private key for auth. Both check and get steps worked. No errors.
- I hijacked onto the check container ran the following command to test the cluster DNS
and it worked, I got back the html from the Concourse dashboard.curl test-web.default.svc.cluster.local:8080- I could also
pingto confirm that the DNS was resolving to the web service's IP
- I could also
- Checked
/etc/resolv.confand it contains the worker's address. Not sure if this is expected, would need to go through the code.# cat /etc/resolv.conf nameserver 172.17.0.6
Have you tried enabling DNS proxy for the workers? If you look for dnsProxyEnable in the values.yaml, you'll get two hits: one for garden and a second for containerd. Could you try enabling that and see if it fixes the problem for you? Looking at our topgun/k8s tests, in-cluster DNS resolution should work, in most circumstances, with and without the dns proxy.
https://github.com/concourse/concourse/blob/4c5121cb96c4299ee4330114ec70fdc3dfb7e102/topgun/k8s/dns_proxy_test.go#L89-L120
I have tried to set the dnsProxyEnable property. No success. If you're willing, we can organize a Slack call. I might be easier.
Let's do it! I'm good with slack, though if you're on discord you could also join the Concourse discord server. The entire team is always hanging out there: https://discord.gg/MeRxXKW
Was able to reproduce it, the difference was --driver virtualbox when starting minikube. Missed that note when I first tried reproducing.
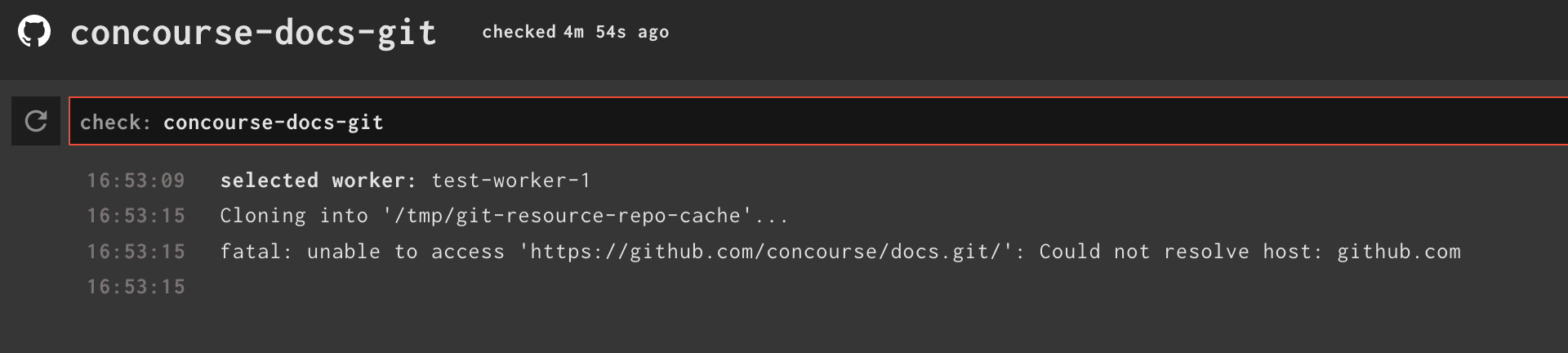
- fly hijack onto the check container
- contents of /etc/resolv.conf
- nameserver 172.17.0.6
- probably install tools like dig, ping, curl
- try reaching hostnames and IP's directly (http://github.com/ vs 140.82.113.4)
- Ping by default try to use IPv6
- using IPv4 resulted in a successful DNS lookup
# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: sit0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN qlen 1000
link/sit 0.0.0.0 brd 0.0.0.0
4: wr78739ktjel-1@if5: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP qlen 1
link/ether da:40:91:13:d3:c3 brd ff:ff:ff:ff:ff:ff
- kubectl exec onto the concourse worker
- contents of /etc/resolv.conf
- nameserver 10.96.0.10 search default.svc.cluster.local svc.cluster.local cluster.local options ndots:5
- probably install tools like dig, ping, curl
- try reaching hostnames and IP's directly (http://github.com/ vs 140.82.113.4)
- check IPtable rules
- capture IP tables rules for comparison later to a docker-compose concourse
# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: sit0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/sit 0.0.0.0 brd 0.0.0.0
3: wbrdg-0a500000: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 3e:20:6a:32:0a:d8 brd ff:ff:ff:ff:ff:ff
5: wr78739ktjel-0@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master wbrdg-0a500000 state UP mode DEFAULT group default qlen 1
link/ether 9e:69:49:f9:03:f4 brd ff:ff:ff:ff:ff:ff link-netnsid 1
14: eth0@if15: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:ac:11:00:06 brd ff:ff:ff:ff:ff:ff link-netnsid 0
- Did this stop working at a particular k8s version? Currently we're on 1.20.
- Does DNS lookup work on earlier versions of k8s with Concourses 7.x?
- k8s 1.19.8: dns lookup fails
- k8s 1.16.15: dns lookup fails
- at this point we realize that the problem is likely with a change in Concourse, not k8s
- The team's prod k8s cluster is on 1.18 and we're not seeing this issue with Concourse 7.x, though we're using containerd. We do use in-cluster dns when running the topgun/k8s tests and those are passing.
- user reported that containerd does work for them, except for local in-cluster DNS resolution
- tried initial test pipeline on k8s 1.20.2 using Concourse 6.7.5 and dns resolution works!
So the problem is in Concourse, between versions 6.7.x and 7.x
- gdn and runc versions are the same in the latest 6.7.x and 7.0.x and 7.1.x - gdn version is 1.19.18, runc is v1.0.0-rc92
- not sure what else we could have changed that would cause this issue between these versions of Concourse
- Could it be something that changed in the Concourse chart? Did we add something to the worker templates? Maybe try using an older version of the chart with Concourse 7.x?
- Tried this and got the same dns error. it's something we changed in 7.x
- Review commits made in the
worker/dir between 6.7.x and 7.0.x
With Concourse 7.0.0 On the concourse worker container, we looked at the veth device that Concourse made vs the one that k8s made:
# concourse veth device
root@concourse-worker-1:/# ip addr show wr9aqgv7r5b4-0
5: wr9aqgv7r5b4-0@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master wbrdg-0a500000 state UP group default qlen 1
link/ether be:14:2c:7f:de:66 brd ff:ff:ff:ff:ff:ff link-netnsid 1
# k8s veth device
root@concourse-worker-1:/# ip addr show eth0
52: eth0@if53: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:07 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.7/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
We thought the bridge device was not being made but we were wrong. It is being made, we just didn't notice it until we looked at 6.7.5 for some reason.
With Concourse 6.7.5 On the Concourse worker container we get the following which looks the same as 7.0.0
root@concourse-worker-0:/# ip addr show wr9c9b9chlma-0
8: wr9c9b9chlma-0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master wbrdg-0a500000 state UP group default qlen 1
link/ether 32:d7:ff:bf:4c:02 brd ff:ff:ff:ff:ff:ff link-netnsid 1
root@concourse-worker-0:/# ip addr show eth0
76: eth0@if77: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:07 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.7/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
root@concourse-worker-0:/# ip addr show wbrdg-0a500000
6: wbrdg-0a500000: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether b6:79:6d:80:be:79 brd ff:ff:ff:ff:ff:ff
inet 10.80.0.1/30 brd 10.80.0.3 scope global wbrdg-0a500000
valid_lft forever preferred_lft forever
@chenbh mentioned this looked similar to https://github.com/concourse/concourse/issues/6038
We updated our pipeline to use the ubuntu based version of the git-resource:
resource_types:
- name: git
type: registry-image
source:
repository: concourse/git-resource
tag: ubuntu
resources:
- name: concourse-docs-git
type: git
check_every: 99h
icon: github
source:
uri: https://github.com/concourse/docs.git
jobs:
- name: job
public: true
plan:
- get: concourse-docs-git
trigger: true
- task: list-files
config:
inputs:
- name: concourse-docs-git
platform: linux
image_resource:
type: registry-image
source: { repository: busybox }
run:
path: ls
args: ["-la", "./concourse-docs-git"]
and it worked!
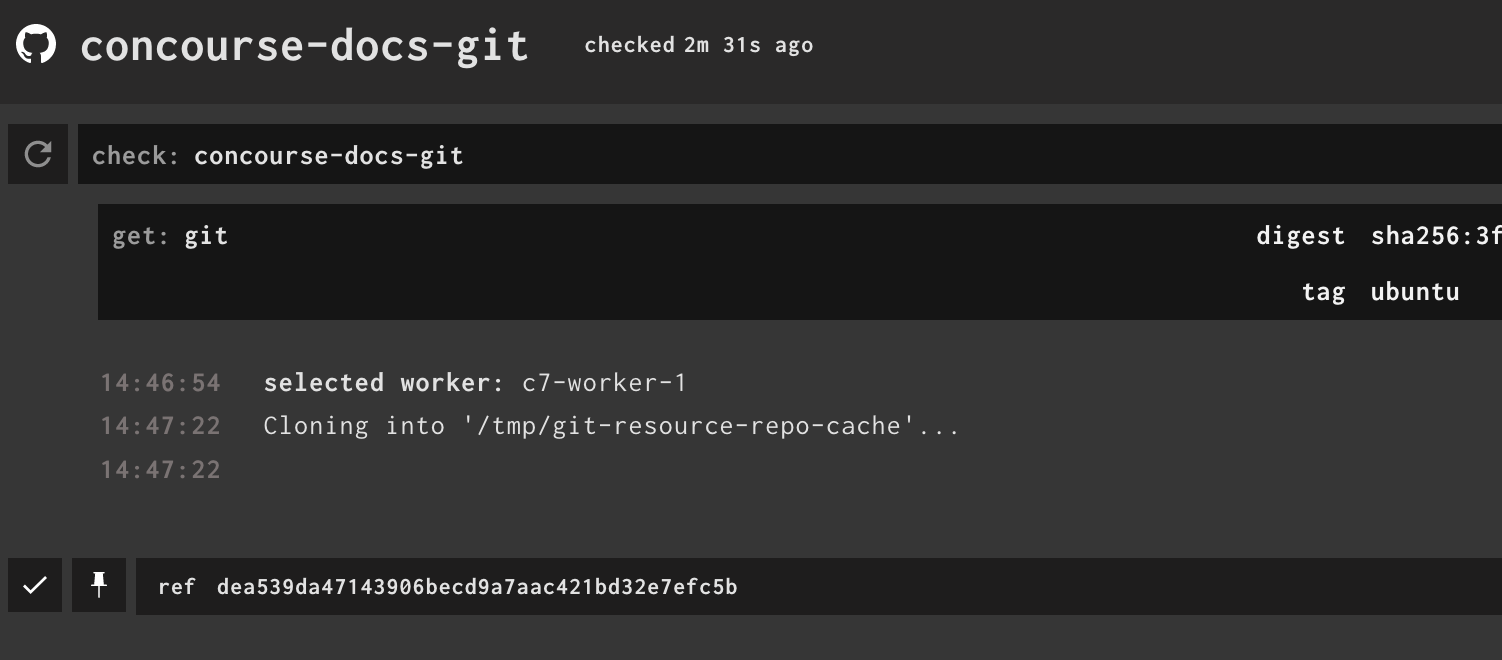
So something in the alpine image our resources are based on is causing dns lookup to fail in k8s.
Decided to see what happens if we run the git-resource as a pod directly on k8s:
$ kubectl run git-alpine -it --image=concourse/git-resource:1.12 -- sh
# ping github.com
ping: bad address 'github.com'
...
It fails!
That would also explain why 6.7.5 works - the base resource types it comes with uses an older image, which also means an older library.
Can you try changing the the vm's dns resolver to --natdnsproxy as suggested by https://gitlab.alpinelinux.org/alpine/aports/-/issues/11879#note_111445
Shakes fist at VirtualBox + Mac
@srheaume Besides virtualbox, what other k8s environments are you seeing this issue in? GKE? EKS? other cloud providers? See Daniel's comment above^
I tried reproducing on GKE v1.18.12-gke.1210 but could not.
$ kubectl run git-alpine -it --image=concourse/git-resource:1.12 -- sh
If you don't see a command prompt, try pressing enter.
/usr/lib # ping github.com
PING github.com (140.82.114.3): 56 data bytes
64 bytes from 140.82.114.3: seq=0 ttl=50 time=26.893 ms
64 bytes from 140.82.114.3: seq=1 ttl=50 time=27.110 ms
^C
--- github.com ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 26.893/27.001/27.110 ms
Stopped my minikube vm and ran VBoxManage modifyvm minikube --natdnsproxy1 on as per Daniel' comment. That didn't fix the problem though. Tried VBoxManage modifyvm minikube --natdnsproxy2 on and still got the error. 🤷
@taylorsilva Sorry for the delay, I had a crazy week. I successfully deployed the latest version of Concourse on OpenShift. I think the problem seems to be related with VirtualBox.
Thanks for verifying. I'm going to de-prioritize this for the team but leave it open.
To re-cap, the issue is with alpine-based container images running on k8s on virtualbox. A workaround is to use the ubuntu-based images instead which one can get using the ubuntu tag on any of the concourse/<resoruce> resources.