cockpit
 cockpit copied to clipboard
cockpit copied to clipboard
storage: LVM2 RAID support
Demo: https://www.youtube.com/watch?v=CE4YmSRD8W4
This needs changes in UDisks2 and libblockdev:
- [x] https://github.com/storaged-project/libblockdev/pull/730
- [x] https://github.com/storaged-project/libblockdev/pull/740
- [ ] https://github.com/storaged-project/udisks/pull/969
- [ ] Convert -l100%PVS into number of extents, https://bugzilla.redhat.com/show_bug.cgi?id=2121015
Todo:
- [ ] How do we present stripes?
- [ ] Where do we put the "Repair" button?
- [ ] Survive when udisks2 is too old.
For later:
- Number of stripes at creation time.
- Redo logic that decides when a PV can be removed.
- Select PVs when growing
- Replacing of PVs in stripes.
I was confused about the "degraded" state; I somehow thought "lvs -o health_status" would return "degraded" for a degraded raid5 volume. This will never happen, both health_status and attr[8] will indicate "partial" when a raid5 lv is missing a single device. I guess we need to deduce that information somewhere in the stack. At that place, we need the full segment structure of the lv, since being degraded is a per-segment property.
both health_status and attr[8] will indicate "partial" when a raid5 lv is missing a single device.
Actually, they will only report "partial" until the missing PV is removed via "vgreduce --removemissing". After that they report "refresh needed". So I guess they are not that helpful as I initially thought.
When drilling into the segments and devices and subvolumes, we can identify missing pieces by their segement type ("error" after vgreduce --removemissing) and "devices" ("[unknown]" before vgreduce --removemissing).
Just for the record, this just happened after growing the volume:

Either LVM2 has made fantastically bad decisions about where to put stuff, or I messed up the data structures...
(A single failure of either sdc or sda1 will kill two stripes.)
(A single failure of either sdc or sda1 will kill two stripes.)
We probably want to warn about unsafe configurations.
Some people may want to run with unsafe setups, as they might back data up anyway... but some people don't. Warnings are useful.
But then: What would be "unsafe"? Anything with worse fail rates than a single disk? Or anything not redundant?
This isn't about preventing people from setting up unsafe RAIDs; just letting them know that what they're doing would lead to data loss... probably with a helper text warning at the bottom of a dialog and possibly even an (i) explaining it more in depth?
This isn't about preventing people from setting up unsafe RAIDs; just letting them know that what they're doing would lead to data loss... probably with a helper text warning at the bottom of a dialog and possibly even an (i) explaining it more in depth?
Yes, this would be useful. In this case, LVM2 has made all the decisions, but we will also allow people to select which drives to use, and there we should warn about selecting "unsafe" ones, like putting two stripes on the same physical disk.
But again, what has just happened in this concrete case counts as a bug in LVM2 (if Cockpit presents the situation correctly, which I think it does). LVM2 should have used sdc to extend the second strip instead of the first, and sda1 to extend the third stripe instead of the second. This should have been possible since all stripe extensions are the same size. shrug I keep an eye out for this.
FWIW, I wrote in-depth about RAID levels @ https://github.com/cockpit-project/cockpit/discussions/16440#discussioncomment-3178556.
Summary:
- Some RAID levels should never be shown in creation (RAID 2 - 4, 0+1, and even RAID 5).
- Other RAID levels should come with warnings, as they either should not be used (RAID 5, if do show it) or could easily result in data loss (and someone should really know what they're doing, such as with RAID 0).
- During RAID creation and viewing, we should display what the RAID level means. (It should be shorter than what I wrote there.)
BUT, this is for RAID in general. LVM2 RAID is a conceptual subset of RAID, of course.
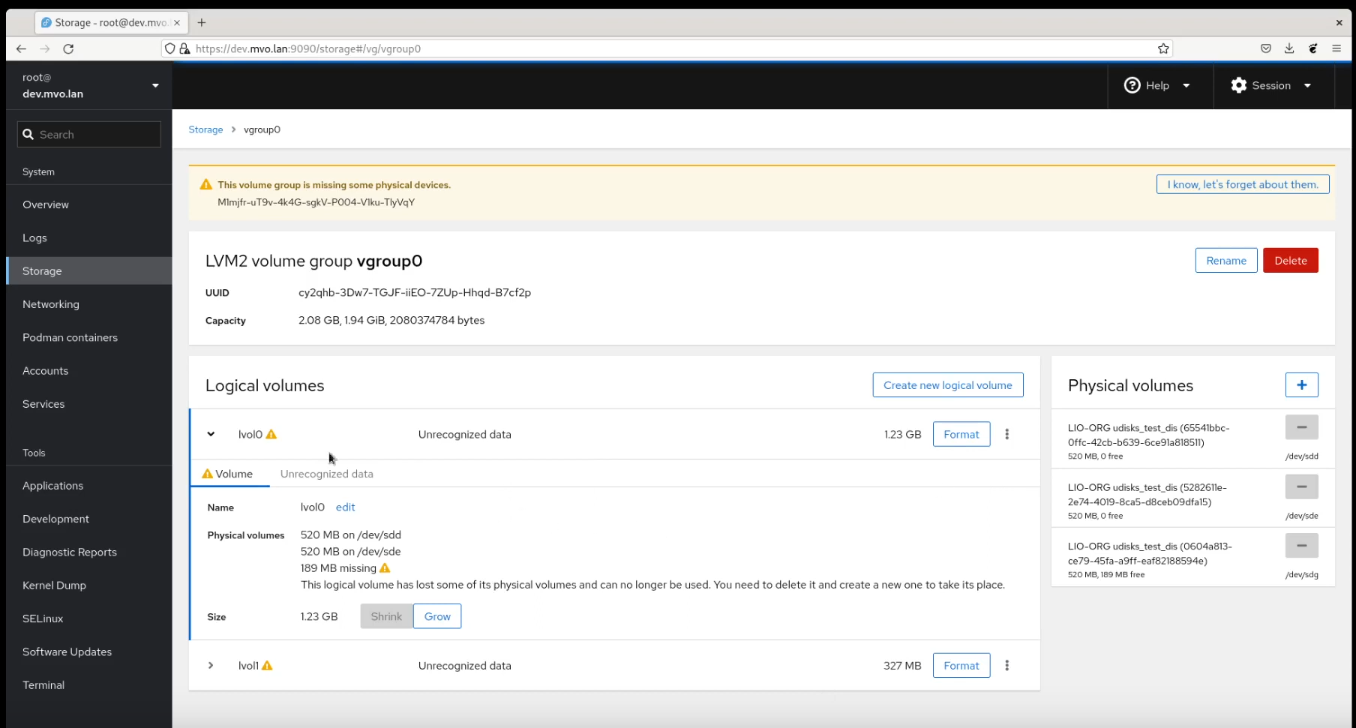
If the filesystem is corrupt and it has to be deleted and restored from backup, it's not supposed to be a warning, it's actuall a critical error.
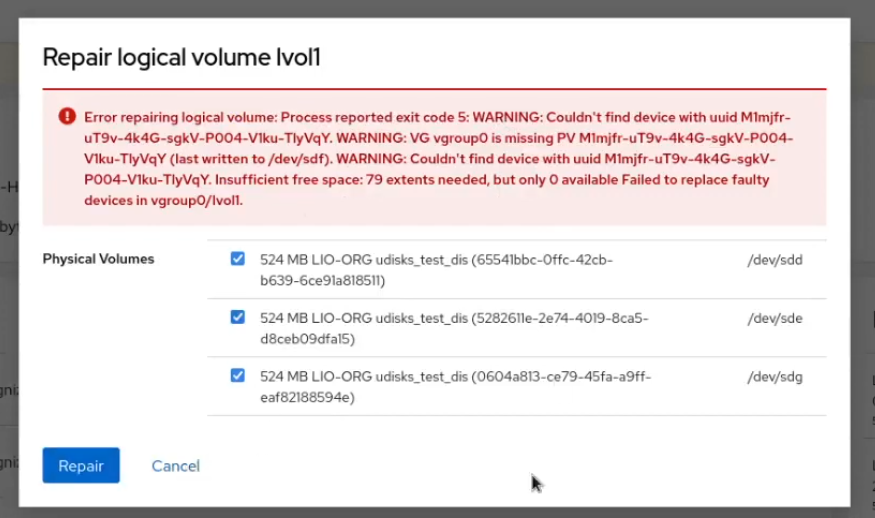
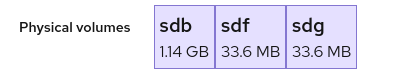
Is there a way to determine which volumes are doing what within this UI?
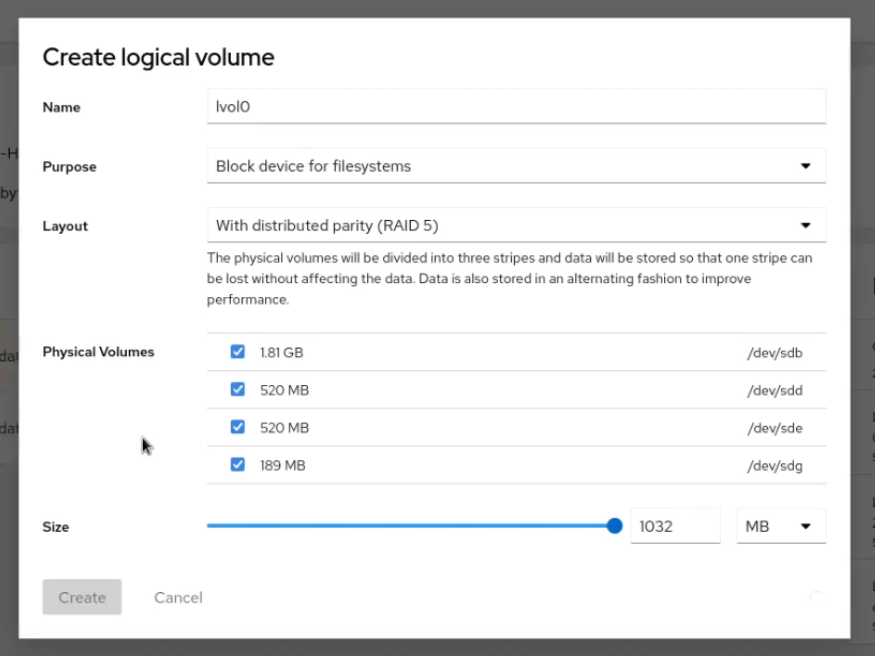
For example, sdb is there for the striping, data will be on sdd, sde is a mirror of sdd, etc.
We should also show that information here as well:
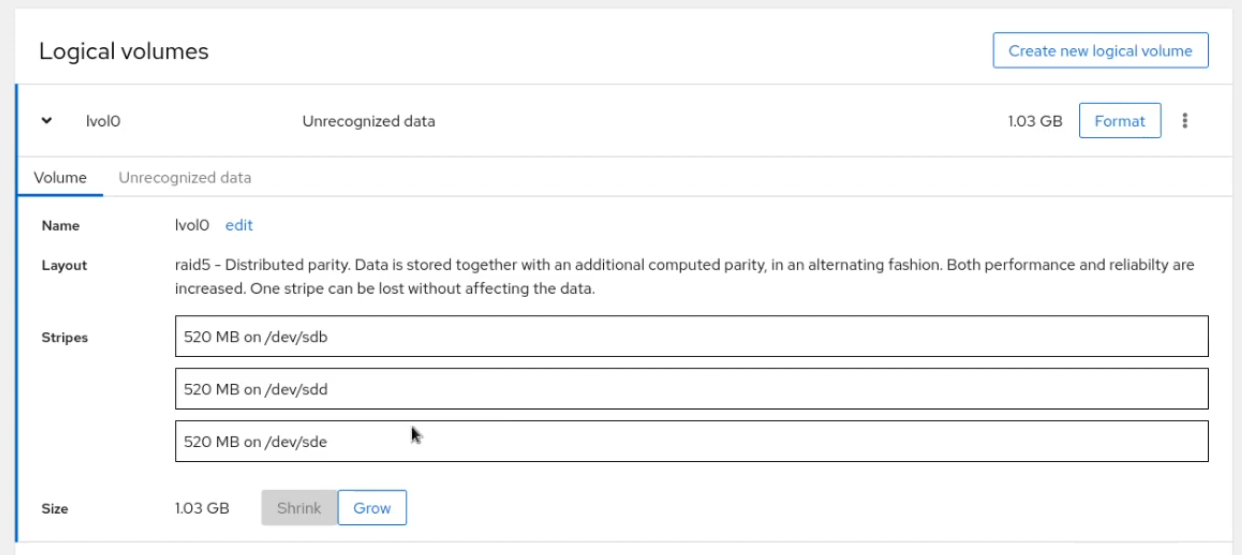
(The outlines make them look like improperly styled text fields here. But I'm sure that's just a placeholder for now.)
OK, one last observation on this quick look:
- Can we make formatting a part of the process, instead of a second step? (After creating a logical volume, everyone's going to want to format it with a filesystem, right?)
If the filesystem is corrupt and it has to be deleted and restored from backup, it's not supposed to be a warning, it's actuall a critical error.
Good point. The Storage page can only show warnings right now, so that needs to be extended.
Is there a way to determine which volumes are doing what within this UI?
Not really... For most RAID types, the stripes have identical roles, no? RAID10 is special, where some stripes are for striping and others for mirroring, but I think even there things are quite mixed up.
Wow, this error! open_mouth
Yeah, let's hope we can avoid this error. In this specific case there was not enough space to repair the logical volume, and I think we can detect that upfront.
In other cases, we wont let the user do actions that will fail when there are PVs missing.
- Can we make formatting a part of the process, instead of a second step? (After creating a logical volume, everyone's going to want to format it with a filesystem, right?)
That was an open issue for a long time, but I'd say it is out of scope here.
(The outlines make them look like improperly styled text fields here. But I'm sure that's just a placeholder for now.)
It's a placeholder, but i also don't have any better idea right now.
I was thinking we should show the disks horizontally, not vertically.
Consider the standard RAID illustrations, as seen on https://dahuawiki.com/Backup/RAID_Intro (but look similar everywhere else):
RAID 0:
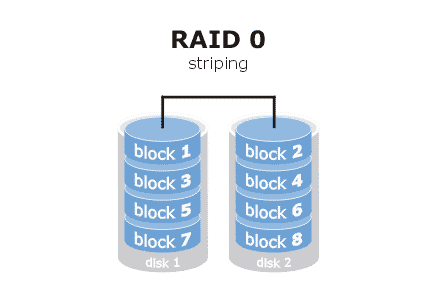 RAID 1:
RAID 1:
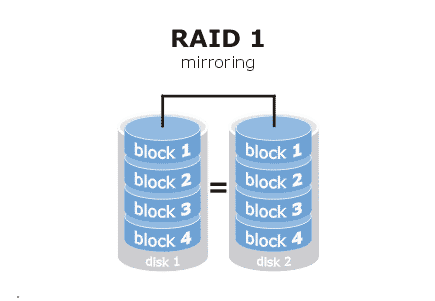 RAID 3:
RAID 3:
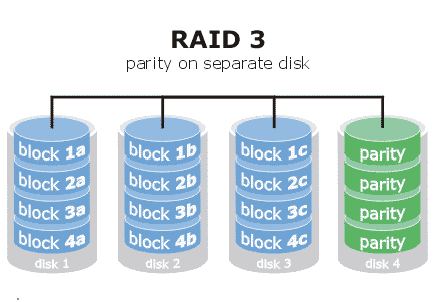 RAID 5:
RAID 5:
 RAID 10:
RAID 10:
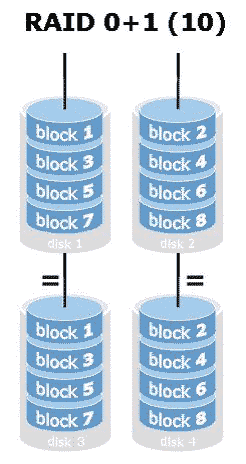
Notice anything? The disks are 1 (no RAID), 2, 4.
You can go higher... but then you start to hit limits like how many disks can a controller hold. I've looked around ant it can go up to 10, 20, 24... but it usually doesn't.
How many disks across can we fit in a typical desktop screen and still have it work? We could use flex or grid for this. If we expand the illustration to be 2D (horizontal and vertical) instead of 1D (just horizontal or just veritcal), then we could effectively cut the disks in half if we have mirrored disks stacked (for example)... which would be useful for RAID 10 visualization.
You can actually see this on the RAID 10 illustration above! Unlike most. It's why I picked these specific RAID illustrations to talk about.
Here's a typical one that just goes across (from seagate):
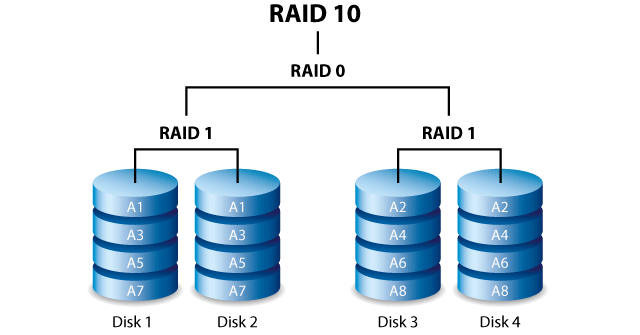
However, I don't think we need to get so detailed that we should show blocks or specific places where parity might be. But we could show a parity disk or sections of disks with parity (which could all be at the bottom and even not to scale... whatever... it's an illustration).
Summary: Illustration goes sideways. And sometimes stack vertically, when there are mirrors. We could use color for data and another color for parity.
Anyway, this is what I had in mind and why I asked if we could know if a disk is a mirror, parity, etc. and if we could map the specific drive label into an illustration.
So, taking my comment above into account, your version could look something like this instead:

And mirrored disks could perhaps be something like this, where there's less vertical space, so they're paired with the disks they mirror:

Or this; we could change the color to show the grouping a bit more (shown without parity this time, but that could be added back in with stipple like above, if it's needed):
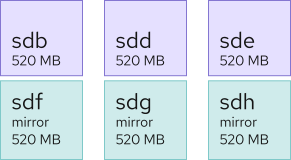
Or have a dedicated disk for parity, such as:

We could do something with grid, so the layout would basically build itself. (Grid items can have named locations, so if something is a mirror, it goes to the mirror area; same for parity, unless it's just inside the disk itself anyway in the layout, which might make sense really)
The next step would be deciding on what you and I makes sense and then I can make a HTML+CSS mockup for the layout. (Which could be translated into PF grid stuff, or we could just use CSS itself, as PF might overcomplicate it in this case otherwise.)
@garrett, thanks!
Yes, let's arrange stripes horizontally. As you say, that is what everybody else is doing in their RAID illustrations.
However:
-
I don't think we need to treat mirrors differently in general. There is no such thing as a RAID level with parity and mirroring.
-
With LVM2, a "stripe" is not always just a single disk, we can also have situations like this:

This is a RAID5 with three "stripes" (what would be disks with mdraid), and each stripe is stored on two disks. Also, stripes don't always use full disks.
We could arrange multiple disks vertically.
-
I think we shouldn't try to show which disk / stripe has the parity bits. The parity bits are not really different from the data bits.
We could provide a separate statement for the whole logical volume like "YYY MB used for protection". This could also be shown in the creation dialog.
I'll put stripes horizontally in a grid layout, and physical volumes within stripes vertically.
There is no such thing as a RAID level with parity and mirroring.
Ah, right. Of course. I was just trying to make some quick mockups. :wink:
I'll put stripes horizontally in a grid layout, and physical volumes within stripes vertically.
OK, cool. Looking forward to the next iteration.
Ok, this is what I have now.
RAID 5 where each stripe extents over two disks:
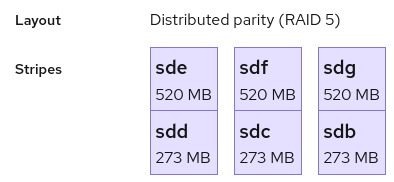
Regular RAID 5 with just a single disk per stripe:

RAID 1 with one mirror, where each mirror half uses two disks:

RAID 6:

We can show redundancy in a mostly symbolic way. For example, for RAID 5, we show how the parity bits combine to fill one stripe worth of space, but are distributed over all the stripes:

Or for a RAID 5 with 5 stripes:

RAID 6:
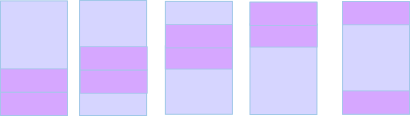
RAID 1 / Mirror:

But showing both this and the division of a stripe into physical volumes (and the text for that) will be too busy I am afraid.
Here is an interesting case:

Stripes should clearly be the same size visually. I need to fix that.
Here is a severely damaged RAID5:

And here is one that has merely lost its redundancy:

The "Repair" button clearly needs better placement.
You have successfully added a new shellcheck configuration differential-shellcheck. As part of the setup process, we have scanned this repository and found no existing alerts. In the future, you will see all code scanning alerts on the repository Security tab.
You have successfully added a new CodeQL configuration /language:python. As part of the setup process, we have scanned this repository and found 13 existing alerts. Please check the repository Security tab to see all alerts.
:boom:  :boom:
(looking forward to this PR going further! :+1: )
About https://bugzilla.redhat.com/show_bug.cgi?id=2181573:
The allocation algorithm used by lvcreate and lvextend has no protection against producing "stupid" configurations, where one PV is used for more than one stripe. Such a configuration does work, but the resulting LV has less redundancy than claimed by the RAID type. For example, people expect a RAID5 volume to survive the loss of one PV without data loss, but if a PV is used for two stripes, losing that PV will destroy both stripes and the RAID5 volume is no longer operational.
Here is an example of a "stupid" configuration:

In that example, the LV consists of two segments (386 MB and 134 MB), but the PVs are assigned to these two segments in such a way that /dev/sdf is used both for the first and the second stripe.
In theory, it is very much possible to survive the loss of /dev/sdf in this example. One just has to treat each segment as a separate RAID5 configuration. The 386 MB lost in the first stripe can be reconstructed from the second and third stripe, and the 134 MB lost in the second stripe can be reconstructed from the first and third stripe.
LVM2 can not do this, however. There is only one dmraid device mapper entry. Running "vgreduce --removemissing" will replace the full second and third stripe with "error" targets.
The allocation algorithm will only create "stupid" configurations when given more PVs than stripes (I think). The example above was created by asking lvcreate to make a RAID5 with three stripes on four PVs.
Thus, we should be able to prevent LVM2 from creating "stupid" configurations by only giving it the "right" amount of PVs. I guess this is what most people do anyway and that this is the reason the world hasn't exploded yet. (It does negate some of the flexibility of LVM2, however, and it makes putting mdraid on top of LVM2 look like the better option, IMO.)
Determining the maximum size should be pretty easy when "number of PVS" == "number of stripes", it's just the minimum of the free space on all PVs (minus some meta data overhead). So that's a big win in that regard as well.
We can add a little convenience by finding the subset of the selected PVs that gives the largest maximum size and use that subset, with or without telling the user about that. Or we could force the user the select exactly the right amount of PVs. That is probably best since people really should be planning their raid volumes much more carefully than linear volumes.
With https://github.com/cockpit-project/bots/pull/4615 we can already run some tests here on fedora-testing.