binary-husky
![]()
binary-husky
> > from transformers import AutoModel, AutoTokenizer > > chatglm_tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True) > > device = 'cpu' > > if device=='cpu': > > chatglm_model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float() > >...
> > > from transformers import AutoModel, AutoTokenizer > > > chatglm_tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True) > > > device = 'cpu' > > > if device=='cpu': > > > chatglm_model...
> 好的,感谢大佬回复。这个本地模型看起来资源消耗不小,明天切换到集群上试一下。 在我的服务器上吃了13GB显存
> 我的个人电脑最高只有8G 3060Ti,但是集群上可以部署一个A100, 这个是不是可以调用更高规格的ChatGLM。 那必须的,a100至少40G显存呢 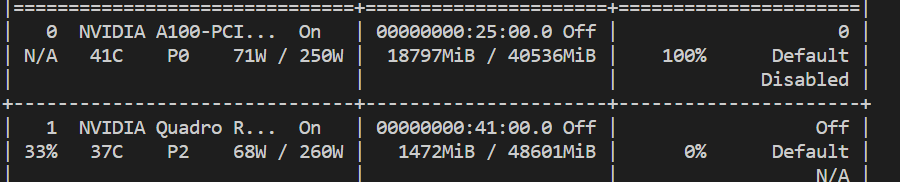
能,所有的后端都是模块化的,在config中禁用即可(request_llm中的对应代码也可以移除) 作为一个模块化的平台,剥离任何一个组件都不影响主体
暂无此计划
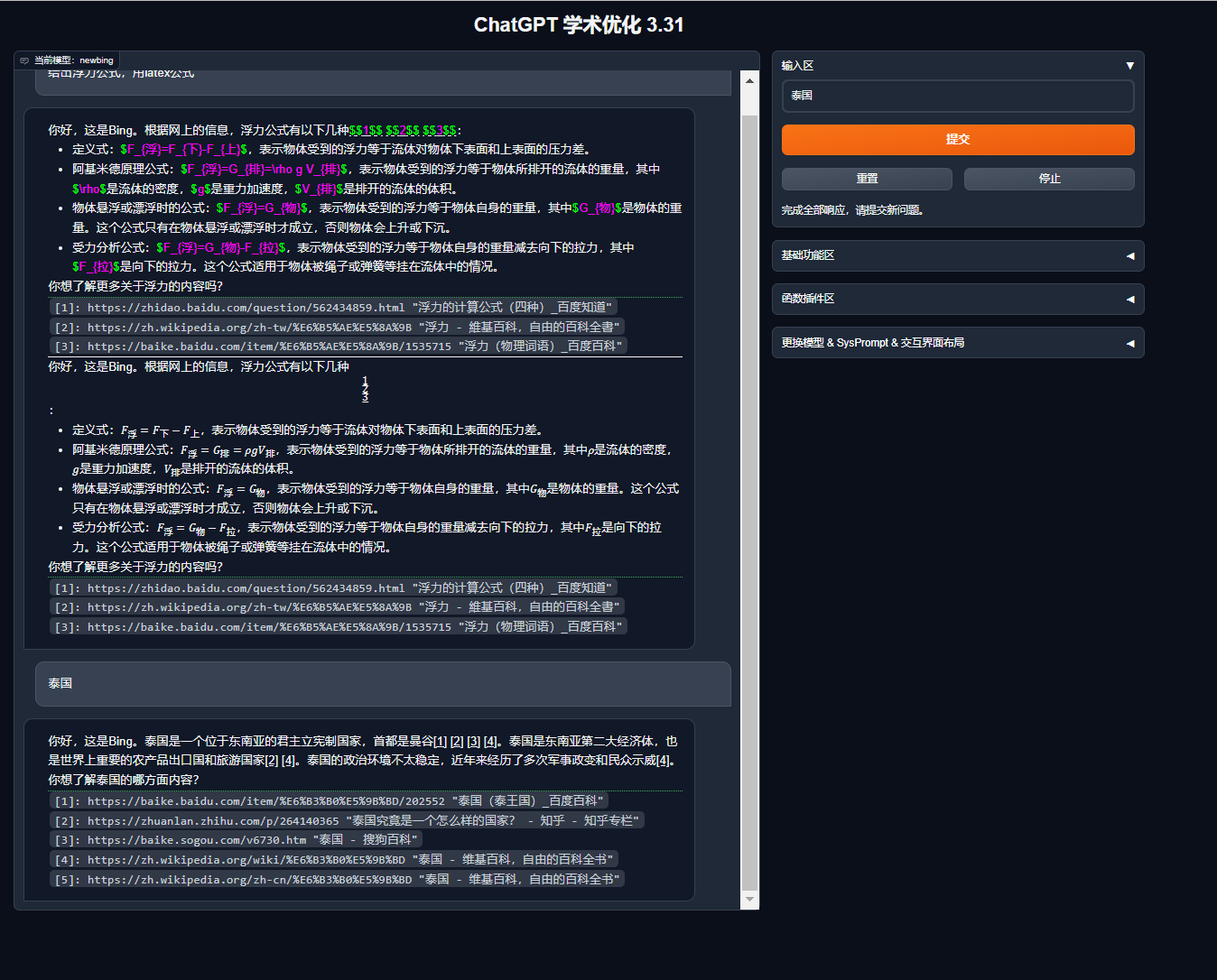 3.32修复
和markdown的语法撞了,先暂时把[]替换成()解决吧,效果还行 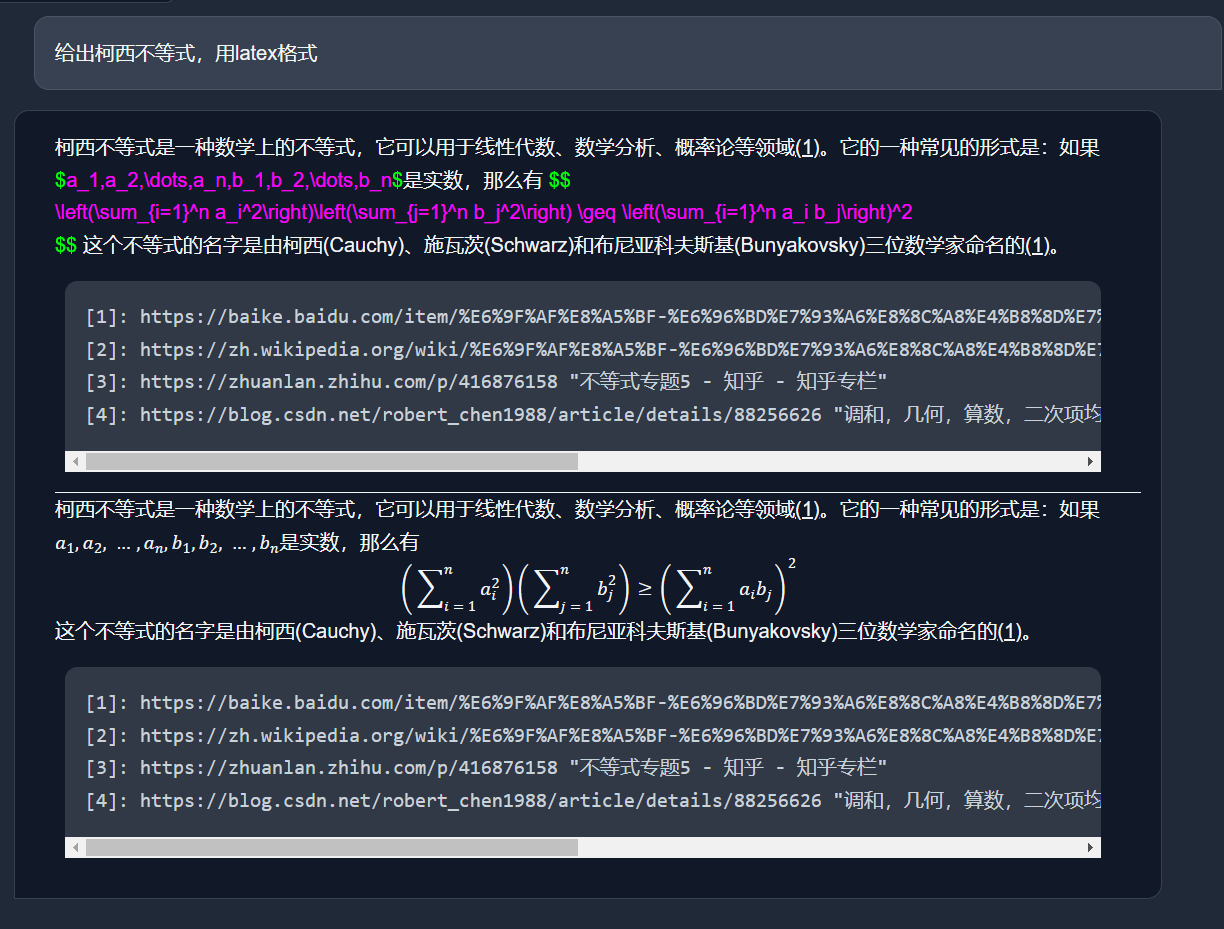
已添加,请更新代码,有问题在这儿随时反馈 https://github.com/binary-husky/gpt_academic/commit/6c17f3e9c826074c16496b69e6bfa2ef4f1b4bca
@Jiyang00 #597 #345 #230