bc-java
 bc-java copied to clipboard
bc-java copied to clipboard
Implementation of Timestamp Renewal and Hash-Tree Renewal for RFC 4998 (Evidence Record Syntax) missing(?)
I cannot find any (high-level) implementation and/or tests for Timestamp Renewal and Hash-Tree Renewal as defined in RFC 4998 5.2.. Did I miss that or is it actually missing?
For an example org.bouncycastle.tsp.ers.ERSEvidenceRecord#validatePresent(byte[], java.util.Date) does not validate correctly if an ArchiveTimestamp has no reducedHashtree field (it is allowed according to RFC 4998 5.2.). Furthermore it only validates the last time stamp and not the whole ArchiveTimeStampChain (see RFC 4998 5.3).
@dghgit, pardon, but do you have any thoughts to this issue? (I’m just guessing that you are the right person to contact.)
I think we need to sort out the chaining before I'd recommend proceeding with a pull request on this. If you'd like to submit code I'd recommend breaking it up into several (hopefully small) commits - for example I'd treat the two renewal tasks separately. It's very difficult to review and install large commits.
Commit for time stamp renewal and hash tree renewal is done: https://github.com/raubv0gel/bc-java/tree/feature-ers-renewal
I had a look. The TimeStamper interface won't work for this. Changing the API is problematic in itself, but the real issue is getting a timestamp in practice is highly asynchronous and may involve batching, errors, and retries.
Actually this does remind me of something we missed earlier, there really should be a way of fetching the state of the generator and a constructor which can use the recovered state. I'll look into this...
I've added TimeStamp renewal. There's an example of it in:
https://github.com/bcgit/bc-java/blob/0554530a86e3ca46149c810f4ab315cd1fac15f0/pkix/src/test/java/org/bouncycastle/tsp/test/ERSTest.java#L326
Looking at hash renewal now.
I've just pushed hash renewal as well. See ERSTest.testHashRenewal() for an example of usage. I think your interpretation of the algorithm was correct. I think everything is now validating correctly... still testing though, feedback would be welcome.
Time Stamp Renewal
I looked at org.bouncycastle.tsp.ers.ERSEvidenceRecord#buildTspRenewalGenerator. Is it really a good idea to ERSDataGroup timestampGroup = new ERSDataGroup(prevTimes);? 5.2. Generation says
In the case of Timestamp Renewal, the content of the
timeStampfield of the old Archive Timestamp has to be hashed and timestamped by a new Archive Timestamp. The new Archive Timestamp MAY not contain areducedHashtreefield, if the timestamp only simply covers the previous timestamp. However, generally one can collect a number of old Archive Timestamps and build the new hash tree with the hash values of the content of theirtimeStampfields.
For me it seems to be too complex to build a new hash tree for each time stamp renewal. If we create a new hash tree, we had to create multiple ArchiveTimeStamps (one for each previous timeStamp), hence multiple new EvidenceRecords, right? And keep in mind, that in general we have multiple EvidenceRecords sharing the same timeStamp that will need a renewed ArchiveTimeStamp. Adding a new simple ArchiveTimeStamp that covers the previous timeStamp seems to be more easy (one can add the new timeStamp to multiple EvidenceRecords).
However, if one wants to create a new hash tree covering all previous timeStamps, one should create a proper hash tree. atsGen.addData(timestampGroup); adds a single object data group only, right? The hash tree would only have a single data object group hash value leave (the only reduced hash tree would be rht = SEQ( SEQ(ts1, ts2, ts3, …, tsn) ) where tsi are the previous time stamps).
TimeStamper Interface
I added this interface because in both functions
public TimeStampRequest generateTimeStampRequest(TimeStampRequestGenerator tspReqGenerator, BigInteger nonce){};
and
public ERSArchiveTimeStamp generateArchiveTimeStamp(TimeStampResponse tspResponse){};
we see
PartialHashtree[] reducedHashTree = getPartialHashtrees();
// …
byte[] rootHash = rootNodeCalculator.computeRootHash(digCalc, reducedHashTree);
Because we need to call generateTimeStampRequest() and generateArchiveTimeStamp() one after another, we actually call getPartialHashtrees() and computeRootHash() twice. Both functions are computational complex (heavy hash value calculations). Hence, we unnecessarily doubled the time of calculation!
… the real issue is getting a timestamp in practice is highly asynchronous and may involve batching, errors, and retries.
That’s right and thus my TimeStamper Interface is not enough. I guess, we need a class that stores the internal state of generateTimeStampRequest() (the result of generateTimeStampRequest() and/or the result of computeRootHash()). We than can use this state in generateArchiveTimeStamp() (no need to recalculate hash values).
Btw. this analogously holds for the time stamp renewal and hash tree renewal functions.
Yes, I think finding some way to deal with the internal state is the trick. I've managed to cut a few corners with the computation as well.
With the time stamp renewal, I think they do it that way to ensure the provenance of the replacement timestamp - it's got a record of the entire history. As you guessed though using a data group then becomes the only way of doing it as otherwise you'd have multiple ArchiveTimeStamps due to the multiple reduced hash trees. At least in this case they do say there should just be one ArchiveTimeStamp so it's "obvious" what needs to be done.
You're correct as well that the timestamp response can be reused if the other evidence records are still in sync - I've included re-use in the test cases and it works fine.
Hash renewal seems to be a complete break though - as the different evidence records have different data in them it results in a break occurring for what used to be related data.
Thank you! I will have a look …
Hash renewal seems to be a complete break though - as the different evidence records have different data in them it results in a break occurring for what used to be related data.
I’m currently reviewing this. My guessing is the same, hash tree renewal seems to be broken by (RFC) design. But, I have to think more about it.
I will report back.
I guess the problem with hash renewal is you really do have to have access to the original data - in some ways thinking about this does make me sympathetic to the decision to split the Merkle tree across different evidence records. It does break the problem of getting the original data up and there may be many reasons why dealing with or processing all the original data might be a non-technical issue.
Hash Tree Renewal
The current implementation org.bouncycastle.tsp.ers.ERSEvidenceRecord#renewHash does not correspond to 5.2. Generation actually. To generate a new hash tree we have to rehash all original data objects d_i and concatenate the DER encoded ArchiveTimeStampSequence of ER(d_i). That is, we need all original data objects and all corresponding EvidenceRecords. The current implementation rehashes only a single data object (ERSData data) …
Moreover, org.bouncycastle.tsp.ers.ERSEvidenceRecord#validate is not complete in the sense of hash tree renewal (see 5.3. Verification).
My guessing is the same, hash tree renewal seems to be broken by (RFC) design.
Now, I think, it’s not broken – implementation should be possible.
I wondered that initially, it's quite explicit though:
Section 5.2, Point 2: Select data objects d(i) referred to by initial Archive Timestamp (objects that are still present and not deleted). Generate hash values h(i) = H((d(i)).
This means the objects in the first partial hash tree.
The other thing I realised it doesn't make sense to do so either - because the hash of the ArchiveTimeStampSequence is also included, even if all the objects were present, you still have to time stamp each evidence record from the original set individually as the root of the Merkle tree will never be the same. Consequently, adding all the original objects as well would just create a lot of work for nothing (you can't tell if they're there as they are not in the primary partial hash tree and only the primary time stamp will tell you that two ERs are related).
Yes, full validation needs more work. I could really use some help with more tests as well.
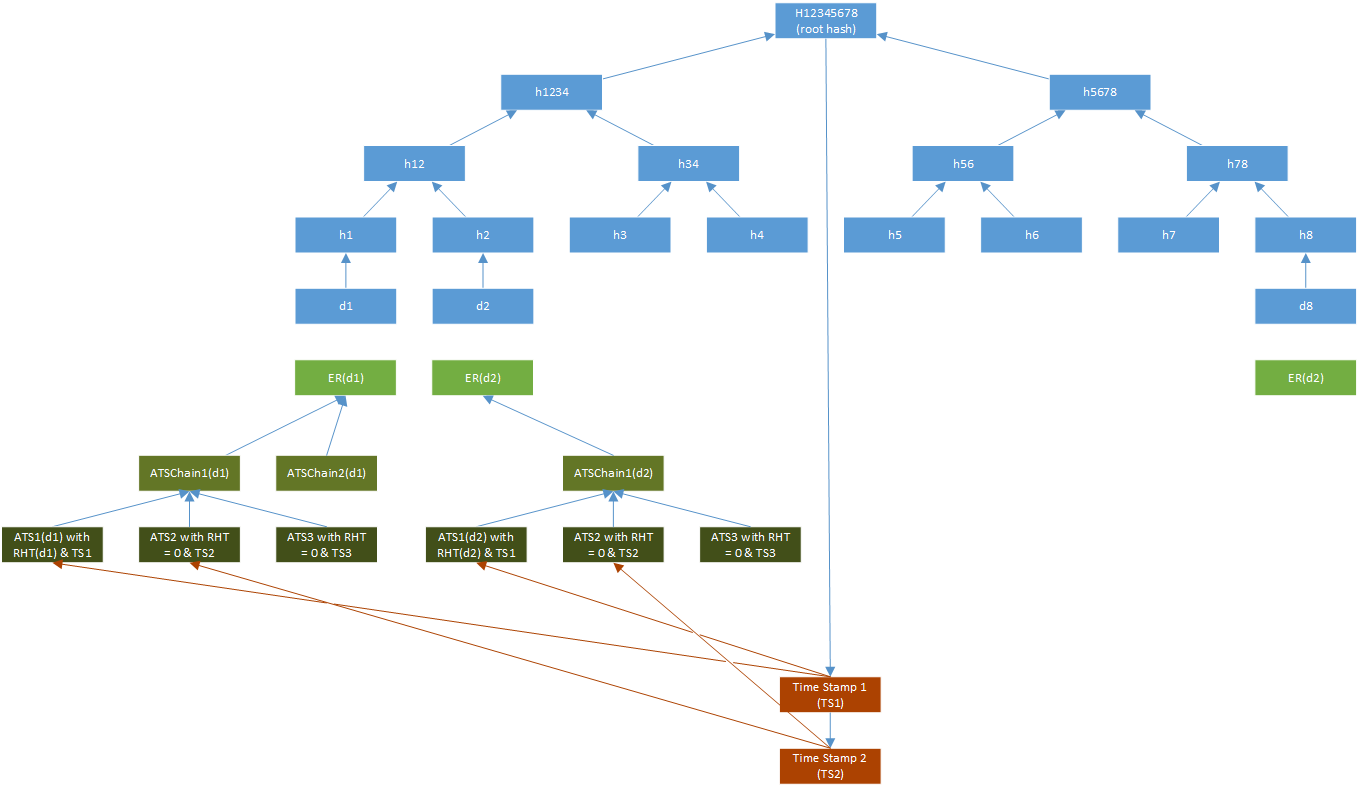
@dghgit, does it help if I write a new, more complex, unit test? Let’s say, like in the tree image (with data d1 to d8) above? I would try to choose data with easy to understand hash values (in the sense of sorting).
Furthermore, I can possibly do a code review if the implementation is “complete”. Would that be desired?
@raubv0gel absolutely "yes" to both. I've also put up a beta release in https://www.bouncycastle.org/betas if it's any help.
Okay, I think one is settled. Still waiting on the test data #1164 but I will close this one off now.