spark
 spark copied to clipboard
spark copied to clipboard
[SPARK-40045][SQL]Optimize the order of filtering predicates
Why are the changes needed?
select id, data FROM testcat.ns1.ns2.table
where id =2
and md5(data) = '8cde774d6f7333752ed72cacddb05126'
and trim(data) = 'a'
Based on the SQL, we currently get the filters in the following order:
// `(md5(cast(data#23 as binary)) = 8cde774d6f7333752ed72cacddb05126)) AND (trim(data#23, None) = a))` comes before `(id#22L = 2)`
== Physical Plan ==
*(1) Project [id#22L, data#23]
+- *(1) Filter ((((isnotnull(data#23) AND isnotnull(id#22L)) AND (md5(cast(data#23 as binary)) = 8cde774d6f7333752ed72cacddb05126)) AND (trim(data#23, None) = a)) AND (id#22L = 2))
+- BatchScan[id#22L, data#23] class org.apache.spark.sql.connector.InMemoryTable$InMemoryBatchScan
In this predicate order, all data needs to participate in the evaluation, even if some data does not meet the later filtering criteria and it may causes spark tasks to execute slowly.
So i think that filtering predicates that need to be evaluated should automatically be placed to the far right to avoid data that does not meet the criteria being evaluated.
As shown below:
// `(id#22L = 2)` comes before `(md5(cast(data#23 as binary)) = 8cde774d6f7333752ed72cacddb05126)) AND (trim(data#23, None) = a))`
== Physical Plan ==
*(1) Project [id#22L, data#23]
+- *(1) Filter ((((isnotnull(data#23) AND isnotnull(id#22L)) AND (id#22L = 2) AND (md5(cast(data#23 as binary)) = 8cde774d6f7333752ed72cacddb05126)) AND (trim(data#23, None) = a)))
+- BatchScan[id#22L, data#23] class org.apache.spark.sql.connector.InMemoryTable$InMemoryBatchScan
How was this patch tested?
- Add new test
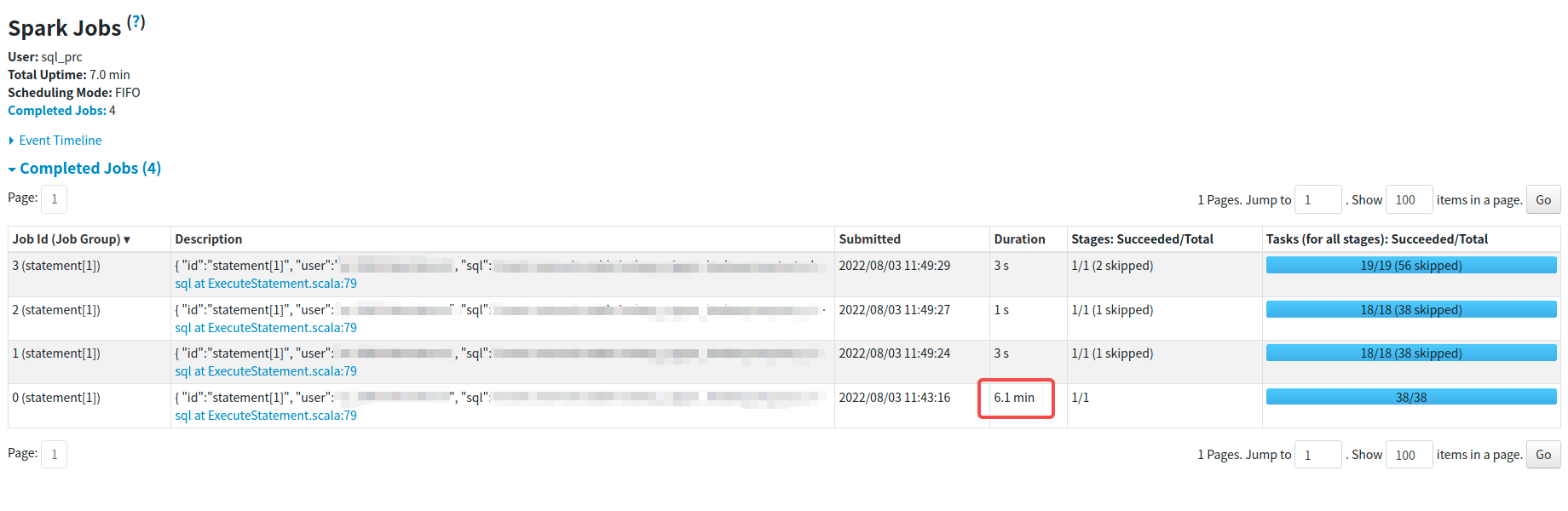
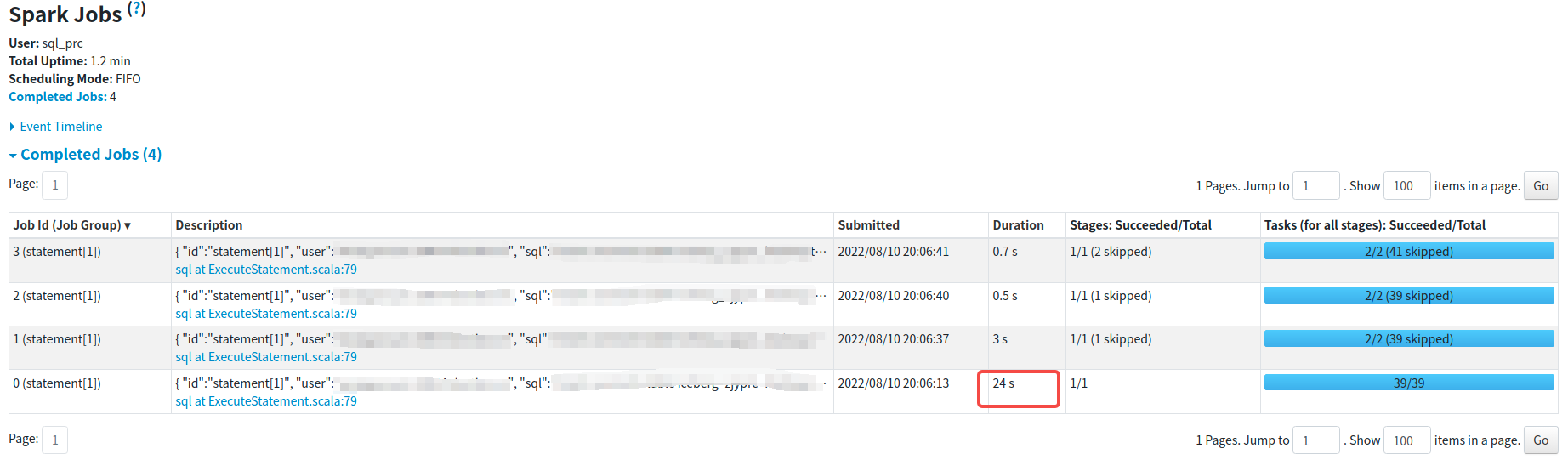
- manually test:the stage execution time for reading data dropped from 6min+ to 24s
the point is clear and valid.
what about this case: day(ts)=1 versus col1 > 13. where ts is a partition column while col1 is not. and some v2 data source implementation is capable of pushing that day function down. ? what will happen?
thought the fix should be more complicated though.
@zinking
what about this case: day(ts)=1 versus col1 > 13. where ts is a partition column while col1 is not. and some v2 data source implementation is capable of pushing that day function down. ? what will happen?
Seems to me the current implementation can only push down filters which are in the format of attribute cmp lit. Could you copy and paste the plan that pushes down day(ts)=1?
@zinking
what about this case: day(ts)=1 versus col1 > 13. where ts is a partition column while col1 is not. and some v2 data source implementation is capable of pushing that day function down. ? what will happen?
Seems to me the current implementation can only push down filters which are in the format of attribute cmp lit. Could you copy and paste the plan that pushes down
day(ts)=1?
just wondering this simple patch might not work for some weird edge cases, anyways I don't have that at hand yet. this is good for now.
the point is clear and valid.
what about this case:
day(ts)=1versuscol1 > 13. wheretsis a partition column whilecol1is not. and some v2 data source implementation is capable of pushing thatdayfunction down. ? what will happen?thought the fix should be more complicated though.
@zinking
I think currently only simple predicates can be pushed down and in your case, is it possible to convert day(ts)=1 and col1 > 13 to ts=20220801 and day(ts)=1 and col1 > 13?
So partition column ts can be push down and after the data scan, day(ts)=1 can be reused for filtering.
@caican00 Could you change the filters order in case r: SupportsPushDownV2Filters too?
@caican00 Could you change the filters order in
case r: SupportsPushDownV2Filterstoo?
@huaxingao ok, i will optimize this case
@caican00 Could you change the filters order in
case r: SupportsPushDownV2Filterstoo?
@huaxingao Updated
@caican00 Do you think this PR is ready for another round of review? In our organization, we have seen a number of users impacted by this after migration to DSv2, so it would be nice to get this merged.
Hey @caican00! Haven't seen an update from your side in the last few months. Are you still interested in contributing this patch to Spark?
@caican00 Do you want to finish this? I think you can just remove implementing SupportsPushDownV2Filters here https://github.com/apache/spark/blob/10dbd4239787ad8db80b06cfde90380c3696c386/sql/catalyst/src/test/scala/org/apache/spark/sql/connector/catalog/InMemoryTable.scala#L258, then it's ready to be merged.
@caican00 if you don't have time for this any more, is it OK with you that I take this over and finish it up? We have quite some customers using DS V2, it would be nice if this fix can be merged. Thanks!
@caican00 I have opened a new PR https://github.com/apache/spark/pull/39892. I don't have your github account email to add you as a co-author. You can add yourself as a co-author to get the commit credit.