til
 til copied to clipboard
til copied to clipboard
Software Quality
Software Quality
Quality begins with the intent. - W. Edwards Deming
Inspection does not improve the quality, nor guarantee quality. Inspection is too late. The quality, good or bad, is already in the product. As Harold F. Dodge said, “You can not inspect quality into a product.”


Broadly, functional requirements define what a system is supposed to do and non-functional requirements define how a system is supposed to be.
Functional requirements are usually in the form of "system shall do
In contrast, non-functional requirements are in the form of "system shall be
Non-functional requirements are often mistakenly called the quality attributes of a system, however there is a distinction between the two. Non-functional requirements are the criteria for evaluating how a software system should perform and a software system must have certain quality attributes in order to meet non-functional requirements. So when we say a system should be "secure", "highly-available", "portable", "scalable" and so on, we are talking about its quality attributes. Other terms for non-functional requirements are "qualities", "quality goals", "quality of service requirements", "constraints", "non-behavioral requirements", or "technical requirements".
Informally these are sometimes called the "ilities", from attributes like stability and portability. Qualities—that is non-functional requirements—can be divided into two main categories:
- Execution qualities, such as safety, security and usability, which are observable during operation (at run time).
- Evolution qualities, such as testability, maintainability, extensibility and scalability, which are embodied in the static structure of the system.
The OMG (Object Management Group) published a study regarding the types of software analysis required for software quality measurement and assessment. This document on "How to Deliver Resilient, Secure, Efficient, and Easily Changed IT Systems in Line with CISQ Recommendations" describes three levels of software analysis.
-
Unit Level Analysis that takes place within a specific program or subroutine, without connecting to the context of that program.
-
Technology Level Analysis that takes into account interactions between unit programs to get a more holistic and semantic view of the overall program in order to find issues and avoid obvious false positives. For instance, it is possible to statically analyze the Android technology stack to find permission errors.[13]
-
System Level Analysis that takes into account the interactions between unit programs, but without being limited to one specific technology or programming language.
A further level of software analysis can be defined.
Mission/Business Level Analysis that takes into account the business/mission layer terms, rules and processes that are implemented within the software system for its operation as part of enterprise or program/mission layer activities. These elements are implemented without being limited to one specific technology or programming language and in many cases are distributed across multiple languages, but are statically extracted and analyzed for system understanding for mission assurance.
Software Product Quality Model
The product quality model defined in ISO/IEC 25010 comprises the eight quality characteristics shown in the following figure:

The quality model is the cornerstone of a product quality evaluation system. The quality model determines which quality characteristics will be taken into account when evaluating the properties of a software product.
The quality of a system is the degree to which the system satisfies the stated and implied needs of its various stakeholders, and thus provides value. Those stakeholders' needs (functionality, performance, security, maintainability, etc.) are precisely what is represented in the quality model, which categorizes the product quality into characteristics and sub-characteristics.
Functional Suitability
This characteristic represents the degree to which a product or system provides functions that meet stated and implied needs when used under specified conditions. This characteristic is composed of the following sub-characteristics:
Functional completeness - Degree to which the set of functions covers all the specified tasks and user objectives.
Functional correctness - Degree to which a product or system provides the correct results with the needed degree of precision.
Functional appropriateness - Degree to which the functions facilitate the accomplishment of specified tasks and objectives.
Performance efficiency
This characteristic represents the performance relative to the amount of resources used under stated conditions. This characteristic is composed of the following sub-characteristics:
Time behaviour - Degree to which the response and processing times and throughput rates of a product or system, when performing its functions, meet requirements.
Resource utilization - Degree to which the amounts and types of resources used by a product or system, when performing its functions, meet requirements.
Capacity - Degree to which the maximum limits of a product or system parameter meet requirements.
Compatibility
Degree to which a product, system or component can exchange information with other products, systems or components, and/or perform its required functions while sharing the same hardware or software environment. This characteristic is composed of the following sub-characteristics:
Co-existence - Degree to which a product can perform its required functions efficiently while sharing a common environment and resources with other products, without detrimental impact on any other product.
Interoperability - Degree to which two or more systems, products or components can exchange information and use the information that has been exchanged.
Usability
Degree to which a product or system can be used by specified users to achieve specified goals with effectiveness, efficiency and satisfaction in a specified context of use. This characteristic is composed of the following sub-characteristics:
Appropriateness recognizability - Degree to which users can recognize whether a product or system is appropriate for their needs.
Learnability - Degree to which a product or system can be used by specified users to achieve specified goals of learning to use the product or system with effectiveness, efficiency, freedom from risk and satisfaction in a specified context of use.
Operability - Degree to which a product or system has attributes that make it easy to operate and control.
User error protection. Degree to which a system protects users against making errors.
User interface aesthetics - Degree to which a user interface enables pleasing and satisfying interaction for the user.
Accessibility - Degree to which a product or system can be used by people with the widest range of characteristics and capabilities to achieve a specified goal in a specified context of use.
Reliability
Degree to which a system, product or component performs specified functions under specified conditions for a specified period of time. This characteristic is composed of the following sub-characteristics:
Maturity - Degree to which a system, product or component meets needs for reliability under normal operation.
Availability - Degree to which a system, product or component is operational and accessible when required for use.
Fault tolerance - Degree to which a system, product or component operates as intended despite the presence of hardware or software faults.
Recoverability - Degree to which, in the event of an interruption or a failure, a product or system can recover the data directly affected and re-establish the desired state of the system.
Security
Degree to which a product or system protects information and data so that persons or other products or systems have the degree of data access appropriate to their types and levels of authorization. This characteristic is composed of the following sub-characteristics:
Confidentiality - Degree to which a product or system ensures that data are accessible only to those authorized to have access.
Integrity - Degree to which a system, product or component prevents unauthorized access to, or modification of, computer programs or data.
Non-repudiation - Degree to which actions or events can be proven to have taken place so that the events or actions cannot be repudiated later.
Accountability - Degree to which the actions of an entity can be traced uniquely to the entity.
Authenticity - Degree to which the identity of a subject or resource can be proved to be the one claimed.
Maintainability
This characteristic represents the degree of effectiveness and efficiency with which a product or system can be modified to improve it, correct it or adapt it to changes in environment, and in requirements. This characteristic is composed of the following sub-characteristics:
Modularity - Degree to which a system or computer program is composed of discrete components such that a change to one component has minimal impact on other components.
Reusability - Degree to which an asset can be used in more than one system, or in building other assets.
Analysability - Degree of effectiveness and efficiency with which it is possible to assess the impact on a product or system of an intended change to one or more of its parts, or to diagnose a product for deficiencies or causes of failures, or to identify parts to be modified.
Modifiability - Degree to which a product or system can be effectively and efficiently modified without introducing defects or degrading existing product quality.
Testability - Degree of effectiveness and efficiency with which test criteria can be established for a system, product or component and tests can be performed to determine whether those criteria have been met.
Portability
Degree of effectiveness and efficiency with which a system, product or component can be transferred from one hardware, software or other operational or usage environment to another. This characteristic is composed of the following sub-characteristics:
Adaptability - Degree to which a product or system can effectively and efficiently be adapted for different or evolving hardware, software or other operational or usage environments.
Installability - Degree of effectiveness and efficiency with which a product or system can be successfully installed and/or uninstalled in a specified environment.
Replaceability - Degree to which a product can replace another specified software product for the same purpose in the same environment.
Quality Model Benefits In Software Development
Activities during product development that can benefit from the use of the quality models include: Identifying software and system requirements; Validating the comprehensiveness of a requirements definition; Identifying software and system design objectives; Identifying software and system testing objectives; Identifying quality control criteria as part of quality assurance; Identifying acceptance criteria for a software product and/or software-intensive computer system; Establishing measures of quality characteristics in support of these activities.
The principle of robustness
- Responsiveness : the specific ability of a system or functional unit to complete assigned tasks within a given time.
- Observability
- Recoverability
- Task Conformance
Resources
- https://www.iso.org/standard/35733.html
- https://en.wikipedia.org/wiki/Static_program_analysis
- https://iso25000.com/index.php/en/iso-25000-standards/iso-25010
- https://medium.com/dev-genius/collaboration-over-inspection-5e55fcd4e642
- https://github.com/crossminer/se-quality-models
- https://en.wikipedia.org/wiki/List_of_system_quality_attributes
- https://en.wikipedia.org/wiki/Non-functional_requirement
Architectural Quality Attributes
A quality attribute is a measurable and testable property of a system which can be used to evaluate the performance of a system within its prescribed environment with respect to its non-functional aspects.
Let us now focus on an aspect which forms the main topic for the rest of this book–Architectural Quality Attributes.
In a previous section, we discussed how an architecture balances and optimizes stakeholder requirements. We also saw some examples of contradicting stakeholder requirements, which an architect seeks to balance, by choosing an architecture which does the necessary trade-offs.
The term quality attribute has been used to loosely define some of these aspects that an architecture makes trade-offs for. It is now the time to formally define what an Architectural Quality Attribute is:
There are a number of aspects that fit this general definition of an architectural quality attribute. However, for the rest of this book, we will be focusing on the following quality attributes:
- Modifiability
- Testability
- Scalability and performance
- Availability
- Security
- Deployability
Modifiability
Many studies show that about 80% of the cost of a typical software system occurs after the initial development and deployment. This shows how important modifiability is to a system's initial architecture.
Modifiability can be defined as the ease with which changes can be made to a system, and the flexibility at which the system adjusts to the changes. It is an important quality attribute, as almost every software system changes over its lifetime—to fix issues, for adding new features, for performance improvements, and so on.
From an architect's perspective, the interest in modifiability is about the following: Difficulty: The ease with which changes can be made to a system Cost: In terms of time and resources required to make the changes Risks: Any risk associated with making changes to the system
Now, what kind of changes are we talking about here? Is it changes to code, changes to deployment, or changes to the entire architecture? The answer is: it can be at any level.
From an architecture perspective, these changes can be captured at generally the following three levels:
- Local: A local change only affects a specific element. The element can be a piece of code such as a function, a class, a module, or a configuration element such as an XML or JSON file. The change does not cascade to any neighboring element or to the rest of the system. Local changes are the easiest to make, and the least risky of all. The changes can be usually quickly validated with local unit tests.
- Non-local: These changes involve more than one element. The examples are as follows:
- Modifying a database schema, which then needs to cascade into the model class representing that schema in the application code.
- Adding a new configuration parameter in a JSON file, which then needs to be processed by the parser parsing the file and/or the application(s) using the parameter. Non-local changes are more difficult to make than local changes, require careful analysis, and wherever possible, integration tests to avoid code regressions.
- Global: These changes either involve architectural changes from top down, or changes to elements at the global level, which cascade down to a significant part of the software system. The examples are as follows:
- Changing a system's architecture from RESTful to messaging (SOAP, XML-RPC, and others) based web services
- Changing a web application controller from Django to an Angular-js based component
- A performance change requirement which needs all data to be preloaded at the frontend to avoid any inline model API calls for an online news application.
These changes are the riskiest, and also the costliest, in terms of resources, time and money. An architect needs to carefully vet the different scenarios that may arise from the change, and get his team to model them via integration tests. Mocks can be very useful in these kinds of large-scale changes.
| Level | Cost | Risk |
|---|---|---|
| Local | Low | Low |
| Non-local | Medium | Medium |
| Global | High | High |
Modifiability at the code level is also directly related to its readability: "The more readable a code is the more modifiable it is. Modifiability of a code goes down in proportion to its readability."
The modifiability aspect is also related to the maintainability of the code. A code module which has its elements very tightly coupled would yield to modification much lesser than a module which has a loosely coupled elements—this is the Coupling aspect of modifiability.
Similarly, a class or module which does not define its role and responsibilities clearly would be more difficult to modify than another one which has well-defined responsibility and functionality. This aspect is called Cohesion of a software module.
The following table shows the relation between Cohesion, Coupling, and Modifiability for an imaginary Module A. Assume that the coupling is from this module to another Module B:
| Cohesion | Coupling | Modifiability |
|---|---|---|
| Low | High | Low |
| Low | Low | Medium |
| High | High | Medium |
| High | Low | High |
It is pretty clear from the preceding table that having higher Cohesion and lower Coupling is the best scenario for the modifiability of a code module.
Other factors that affect modifiability are as follows:
- Size of a module (number of lines of code): Modifiability decreases when size increases.
- Number of team members working on a module: Generally, a module becomes less modifiable when a larger number of team members work on the module due to the complexities in merging and maintaining a uniform code base.
- External third-party dependencies of a module: The larger the number of external third-party dependencies, the more difficult it is to modify the module. This can be thought of as an extension of the coupling aspect of a module.
- Wrong use of the module API: If there are other modules which make use of the private data of a module rather than (correctly) using its public API, it is more difficult to modify the module. It is important to ensure proper usage standards of modules in your organization to avoid such scenarios. This can be thought of as an extreme case of tight Coupling.
Testability
Testability refers to how much a software system is amenable to demonstrating its faults through testing. Testability can also be thought of as how much a software system hides its faults from end users and system integration tests—the more testable a system is, the less it is able to hide its faults.
Testability is also related to how predictable a software system's behavior is. The more predictable a system, the more it allows for repeatable tests, and for developing standard test suites based on a set of input data or criteria. Unpredictable systems are much less amenable to any kind of testing, or, in the extreme case, not testable at all.
In software testing, you try to control a system's behavior by, typically, sending it a set of known inputs, and then observing the system for a set of known outputs. Both of these combine to form a testcase. A test suite or test harness, typically, consists of many such test cases.
Test assertions are the techniques that are used to fail a test case when the output of the element under the test does not match the expected output for the given input. These assertions are usually manually coded at specific steps in the test execution stage to check the data values at different steps of the testcase:
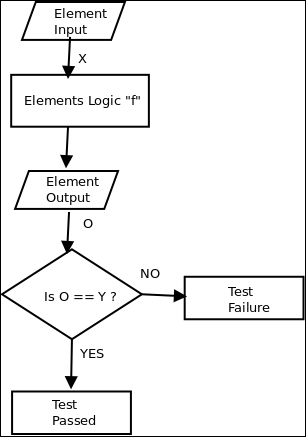
Representative flowchart of a simple unit test case for function f('X') = 'Y'
The preceding diagram shows an example of a representative flowchart for a testable function "f" for a sample input "X" with expected output "Y".
In order to recreate the session or state at the time of a failure, the record/playback strategy is often used. This employs specialized software (such as Selenium), which records all user actions that led to a specific fault, and saves it as a testcase. The test is reproduced by replaying the testcase using the same software which tries to simulate the same testcase; this is done by repeating the same set and order of UI actions.
Testability is also related to the complexity of code in a way very similar to modifiability. A system becomes more testable when parts of it can be isolated and made to work independent of the rest of the system. In other words, a system with low coupling is more testable than a system with high coupling.
Another aspect of testability, which is related to the predictability mentioned earlier, is to reduce non-determinism. When writing test suites, we need to isolate the elements that are to be tested from other parts of the system which have a tendency to behave unpredictably so that the tested element's behavior becomes predictable.
An example is a multi-threaded system, which responds to events raised in other parts of the system. The entire system is probably quite unpredictable, and not amenable to repeated testing. Instead one needs to separate the events subsystem, and possibly, mock its behavior so that those inputs can be controlled, and the subsystem which receives the events become predictable and hence, testable.
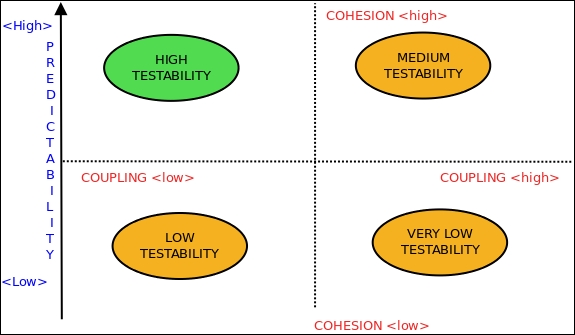
The following schematic diagram explains the relationship between the testability and predictability of a system to the Coupling and Cohesion between its components:
Scalability
Modern-day web applications are all about scaling up. If you are part of any modern-day software organization, it is very likely that you have heard about or worked on an application that is written for the cloud, which is able to scale up elastically on demand. Scalability of a system is its capacity to accommodate increasing workload on demand while keeping its performance within acceptable limits. Scalability in the context of a software system, typically, falls into two categories, which are as follows:
-
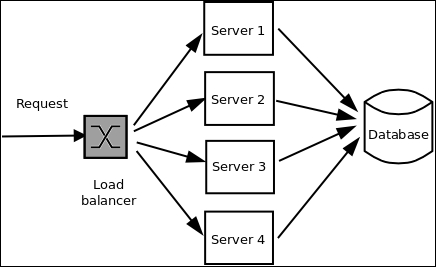
Horizontal scalability: Horizontal scalability implies scaling out/in a software system by adding more computing nodes to it. Advances in cluster computing in the last decade have given rise to the advent of commercial horizontally scalable elastic systems as services on the Web. A well-known example is Amazon Web Services. In horizontally scalable systems, typically, data and/or computation is done on units or nodes, which are, usually, virtual machines running on commodity systems known as virtual private servers (VPS). The scalability is achieved "n" times by adding n or more nodes to the system, typically fronted by a load balancer. Scaling out means expanding the scalability by adding more nodes, and scaling in means reducing the scalability by removing existing nodes:
-
Vertical scalability: Vertical scalability involves adding or removing resources from a single node in a system. This is usually done by adding or removing CPUs or RAM (memory) from a single virtual server in a cluster. The former is called scaling up, and the latter, scaling down. Another kind of scaling up is increasing the capacity of an existing software process in the system—typically, by augmenting its processing power. This is usually done by increasing the number of processes or threads available to an application. Some examples are as follows:
- Increasing the capacity of an Nginx server process by increasing its number of worker processes
- Increasing the capacity of a PostgreSQL server by increasing its number of maximum connections
Performance
Performance of a system is related to its scalability. Performance of a system can be defined as follows: "Performance of a computer system is the amount of work accomplished by a system using a given unit of computing resource. Higher the work/unit ratio, higher the performance."
The unit of computing resource to measure performance can be one of the following: - Response time: How much time a function or any unit of execution takes to execute in terms of real time (user time) and clock time (CPU time). - Latency: How much time it takes for a system to get its stimulation, and then provide a response. An example is the time it takes for the request-response loop of a web application to complete, measured from the end-user perspective. - Throughput: The rate at which a system processes its information. A system which has higher performance would usually have a higher throughput, and correspondingly higher scalability. An example is the throughput of an e-commerce website measured as the number of transactions completed per minute.
Performance is closely tied to scalability, especially, vertical scalability. A system that has excellent performance with respect to its memory management would easily scale up vertically by adding more RAM.
Similarly, a system that has multi-threaded workload characteristics and is written optimally for a multicore CPU, would scale up by adding more CPU cores.
Horizontal scalability is thought of as having no direct connection to the performance of a system within its own compute node. However, if a system is written in a way that it doesn't utilize the network effectively, thereby producing network latency issues, it may have a problem scaling horizontally effectively, as the time spent on network latency would offset any gain in scalability obtained by distributing the work.
Some dynamic programming languages such as Python have built-in scalability issues when it comes to scaling up vertically. For example, the Global Interpreter Lock (GIL) of Python (CPython) prevents it from making full use of the available CPU cores for computing by multiple threads.
Availability
Availability refers to the property of readiness of a software system to carry out its operations when the need arises.
Availability of a system is closely related to its reliability. The more reliable a system is, the more available it is.
Another factor which modifies availability is the ability of a system to recover from faults. A system may be very reliable, but if the system is unable to recover either from complete or partial failures of its subsystems, then it may not be able to guarantee availability. This aspect is called recovery.
The availability of a system can be defined as follows:
"Availability of a system is the degree to which the system is in a fully operable state to carry out its functionality when it is called or invoked at random."
Mathematically, this can be expressed as follows: Availability = MTBF/(MTBF + MTTR)
Take a look at the following terms used in the preceding formula:
MTBF: Mean time between failures
MTTR: Mean time to repair
This is often called the mission capable rate of a system.
Techniques for Availability are closely tied to recovery techniques. This is due to the fact that a system can never be 100% available. Instead, one needs to plan for faults and strategies to recover from faults, which directly determines the availability. These techniques can be classified as follows:
- Fault detection: The ability to detect faults and take action helps to avert situations where a system or parts of a system become unavailable completely. Fault detection typically involves steps such as monitoring, heartbeat, and ping/echo messages, which are sent to the nodes in a system, and the response measured to calculate if the nodes are alive, dead, or are in the process of failing.
- Fault recovery: Once a fault is detected, the next step is to prepare the system to recover from the fault and bring it to a state where the system can be considered available. Typical tactics used here include Hot/Warm Spares (Active/Passive redundancy), Rollback, Graceful Degradation, and Retry.
- Fault prevention: This approach uses active methods to anticipate and prevent faults from occurring so that the system does not have a chance to go to recovery.
Availability of a system is closely tied to the consistency of its data via the CAP theorem which places a theoretical limit on the trade-offs a system can make with respect to consistency versus availability in the event of a network partition. The CAP theorem states that a system can choose between being consistent or being available—typically leading to two broad types of systems, namely, CP (consistent and tolerant to network failures) and AP (available and tolerant to network failures).
Availability is also tied to the system's scalability tactics, performance metrics, and its security. For example, a system that is highly horizontally scalable would have a very high availability, since it allows the load balancer to determine inactive nodes and take them out of the configuration pretty quickly.
A system which instead tries to scale up may have to monitor its performance metrics carefully. The system may have availability issues even when the node on which the system is fully available if the software processes are squeezed for system resources such as CPU time or memory. This is where performance measurements become critical, and the system's load factor needs to be monitored and optimized.
With the increasing popularity of web applications and distributed computing, security is also an aspect that affects availability. It is possible for a malicious hacker to launch remote denial of service attacks on your servers, and if the system is not made foolproof against such attacks, it can lead to a condition where the system becomes unavailable or only partially available.
Security
Security, in the software domain, can be defined as the degree of ability of a system to avoid damage to its data and logic from unauthenticated access, while continuing to provide services to other systems and roles that are properly authenticated.
A security crisis or attack occurs when a system is intentionally compromised with a view to gaining illegal access to it in order to compromise its services, copy, or modify its data, or deny access to its legitimate users.
In modern software systems, the users are tied to specific roles which have exclusive rights to different parts of the system. For example, a typical web application with a database may define the following roles:
- user: End user of the system with login and access to his/her private data
- dbadmin: Database administrator, who can view, modify, or delete all database data
- reports: Report admin, who has admin rights only to those parts of database and code that deal with report generation
- admin: Superuser, who has edit rights to the complete system This way of allocating system control via user roles is called access control. Access control works by associating a user role with certain system privileges, thereby decoupling the actual user login from the rights granted by these privileges.
This principle is the Authorization technique of security.
Another aspect of security is with respect to transactions where each person must validate the actual identity of the other. Public key cryptography, message signing, and so on are common techniques used here. For example, when you sign an e-mail with your GPG or PGP key, you are validating yourself—The sender of this message is really me, Mr. A—to your friend Mr. B on the other side of the e-mail. This principle is the Authentication technique of security.
The other aspects of security are as follows:
- Integrity: These techniques are used to ensure that a data or information is not tampered with in anyway on its way to the end user. Examples are message hashing, CRC Checksum, and others.
- Origin: These techniques are used to assure the end receiver that the origin of the data is exactly the same as where it is purporting to be from. Examples of this are SPF, Sender-ID (for e-mail), Public Key Certificates and Chains (for websites using SSL), and others.
- Authenticity: These are the techniques which combine both the Integrity and Origin of a message into one. This ensures that the author of a message cannot deny the contents of the message as well as its origin (himself/herself). This typically uses Digital Certificate Mechanisms.
Deployability
Deployability is one of those quality attributes which is not fundamental to the software. However, in this book, we are interested in this aspect, because it plays a critical role in many aspects of the ecosystem in the Python programming language and its usefulness to the programmer.
Deployability is the degree of ease with which software can be taken from the development to the production environment. It is more of a function of the technical environment, module structures, and programming runtime/languages used in building a system, and has nothing to do with the actual logic or code of the system.
The following are some factors that determine deployability:
- Module structures: If your system has its code organized into well-defined modules/projects which compartmentalize the system into easily deployable subunits, the deployment is much easier. On the other hand, if the code is organized into a monolithic project with a single setup step, it would be hard to deploy the code into a multiple node cluster.
- Production versus development environment: Having a production environment which is very similar to the structure of the development environment makes deployment an easy task. When the environments are similar, the same set of scripts and toolchains that are used by the developers/Devops team can be used to deploy the system to a development server as well as a production server with minor changes—mostly in the configuration.
- Development ecosystem support: Having a mature tool-chain support for your system runtime, which allows configurations such as dependencies to be automatically established and satisfied, increases deployability. Programming languages such as Python are rich in this kind of support in its development ecosystem, with a rich array of tools available for the Devops professional to take advantage of.
- Standardized configuration: It is a good idea to keep your configuration structures (files, database tables, and others) the same for both developer and production environments. The actual objects or filenames can be different, but if the configuration structures vary widely across both the environments, deployability decreases, as extra work is required to map the configuration of the environment to its structures.
- Standardized infrastructure: It is a well-known fact that keeping your deployments to a homogeneous or standardized set of infrastructure greatly aids deployability. For example, if you standardize your frontend application to run on 4 GB RAM, Debian-based 64-bit Linux VPS, then it is easy to automate deployment of such nodes—either using a script, or by using elastic compute approaches of providers such as Amazon—and to keep a standard set of scripts across both development and production environments. On the other hand, if your production deployment consists of heterogeneous infrastructure, say, a mix of Windows and Linux servers with varying capacities and resource specifications, the work typically doubles for each type of infrastructure decreasing deployability.
- Use of containers: The user of container software, popularized by the advent of technology such as Docker and Vagrant built on top of Linux containers, has become a recent trend in deploying software on servers. The use of containers allows you to standardize your software, and makes deployability easier by reducing the amount of overhead required to start/stop the nodes, as containers don't come with the overhead of a full virtual machine. This is an interesting trend to watch for.
Reference
- [x] https://subscription.packtpub.com/book/application_development/9781786468529/1/ch01lvl1sec11/architectural-quality-attributes
Latency
Time delay between the cause and the effect of some physical change in the system being observed.
Latency from a general point of view is a time delay between the cause and the effect of some physical change in the system being observed, but, known within gaming circles as "lag", latency is a time interval between the input to a simulation and the visual or auditory response, often occurring because of network delay in online games.
Latency is physically a consequence of the limited velocity which any physical interaction can propagate. The magnitude of this velocity is always less than or equal to the speed of light. Therefore, every physical system with any physical separation (distance) between cause and effect will experience some sort of latency, regardless of the nature of stimulation that it has been exposed to.
The precise definition of latency depends on the system being observed or the nature of the simulation. In communications, the lower limit of latency is determined by the medium being used to transfer information. In reliable two-way communication systems, latency limits the maximum rate that information can be transmitted, as there is often a limit on the amount of information that is "in-flight" at any one moment. In the field of human–machine interaction, perceptible latency has a strong effect on user satisfaction and usability.
Throughput
Throughput is the rate of production or the rate at which something is processed.
Software Quality Metrics
Coupling, Complexity, Cohesion and Size are the fundamental internal quality attributes of a software.
Size
Size is one of the oldest and most common forms of software measurement. Measured by the number of lines or methods in the code. A very high count might indicate that a class or method is trying to do too much work and should be split up. It might also indicate that the class might be hard to maintain.
######Size Metrics CLOC (Class Lines of Code): The number of all nonempty, non-commented lines of the body of the class. CLOC is a measure of size and also indirectly related to the class complexity. NOF (Number of Fields): The number of fields (attributes) in a class NOM (Number of Methods): The number of methods in a class. NOSF (Number of Static Fields): The number of static fields in a class. NOSM (Number of Static Methods): The number of static methods in a class. CM-LOC (Class-Methods Lines of Code): Total number of all nonempty, non-commented lines of methods inside a class. NoI (Number of Interfaces): Total number of Interfaces. NoCls (Number of Classes):Total number of classes. NoE (Number of Entities): Total number of Interfaces and classes. NORM (Number of Overridden Methods): The number of Overridden Methods. nofP (Number of Packages): Number of Packages in the project nofPa (Number of External Packages): Number of External Packages referenced by the project nofEE (Number of External Entities): Number of External classes and interfaces referenced by the project
Complexity
Implies being difficult to understand and describes the interactions between a number of entities. Higher levels of complexity in software increase the risk of unintentionally interfering with interactions and so increases the chance of introducing defects when making changes.
Complexity Metrics
WMC (Weighted Method Count): The weighted sum of all class’ methods and` represents the McCabe complexity of a class. It is equal to number of methods, if the complexity is taken as 1 for each method. The number of methods and complexity can be used to predict development, maintaining and testing effort estimation. In inheritance if base class has high number of method, it affects its’ child classes and all methods are represented in subclasses. If number of methods is high, that class possibly domain specific. Therefore they are less reusable. Also these classes tend to more change and defect prone.
DIT (Depth of Inheritance Tree): The position of the class in the inheritance tree. Has 0 (zero) value for root and non-inherited classes.For the multiple inheritance, the metric shows the maximum length. Deeper class in the inheritance tree, probably inherit. Therefore, it is harder to predict its behavior. Also this class relatively complex to develop, test and maintain.
RFC (Response For a Class) : The number of the methods that can be potentially invoked in response to a public message received by an object of a particular class. If the number of methods that can be invoked at a class is high, then the class is considered more complex and can be highly coupled to other classes. Therefore more test and maintain effort is required.
SI (Specialization Index) : Defined as NORM * DIT / NOM. The Specialization Index metric measures the extent to which subclasses override their ancestors classes. This index is the ratio between the number of overrid- den methods and total number of methods in a Class, weighted by the depth of inheritance for this class. Lorenz and Kidd precise : Methods that invoke the superclass’ method or override template are not included.
Coupling
Coupling between two classes A and B if: A has an attribute that refers to (is of type) B. A calls on services of an object B. A has a method that references B (via return type or parameter). A has a local variable which type is class B. A is a subclass of (or implements) class B.
Tightly coupled systems tend to exhibit the following characteristics: A change in a class usually forces a ripple effect of changes in other classes. Require more effort and/or time due to the increased dependency. Might be harder to reuse a class because dependent classes must be included.
Coupling Metrics
NOC (Number of Children): The number of direct subclasses of a class. The size of NOC approximately indicates how an application reuses itself. It is assumed that the more children a class has, the more responsibility there is on the maintainer of the class not to break the children’s behaviour. As a result, it is harder to modify the class and requires more testing.
CBO (Coupling Between Object Classes): The number of classes that a class is coupled to. It is calculated by counting other classes whose attributes or methods are used by a class, plus those that use the attributes or methods of the given class. Inheritance relations are excluded. As a measure of coupling CBO metric is related with reusability and testability of the class. More coupling means that the code becomes more difficult to maintain because changes in other classes can also cause changes in that class. Therefore these classes are less reusable and need more testing effort.
CBO Lib: The number of dependent library classes.
CBO App: The number of dependent classes in the application.
EC (Efferent Coupling): Outgoing Coupling. The number of classes in other packages that the classes in the package depend upon is an indicator of the package’s dependence on externalities.
AC(Afferent Coupling): Incoming Coupling. The number of classes in other packages that depend upon classes within the package is an indicator of the package’s responsibility.
ATFD (Access to Foreign Data): is the number of classes whose attributes are directly or indirectly reachable from the investigated class. Classes with a high ATFD value rely strongly on data of other classes and that can be the sign of the God Class.
Degree: Degree of corresponding graph vertex of the class
InDegree: In-degree of corresponding graph vertex of the class
OutDegree: Out-degree of corresponding graph vertex of the class
Cohesion
Measure how well the methods of a class are related to each other. High cohesion (low lack of cohesion) tend to be preferable, because high cohesion is associated with several desirable traits of software including robustness, reliability, reusability, and understandability. In contrast, low cohesion is associated with undesirable traits such as being difficult to maintain, test, reuse, or even understand.
Cohesion Metrics
LCOM (Lack of Cohesion of Methods): Measure how methods of a class are related to each other. Low cohesion means that the class implements more than one responsibility. A change request by either a bug or a new feature, on one of these responsibilities will result change of that class. Lack of cohesion also influences understandability and implies classes should probably be split into two or more subclasses. LCOM3 defined as follows LCOM3 = (m – sum(mA)/a) / (m-1) where :
m number of procedures (methods) in class
a number of variables (attributes) in class. a contains all variables whether shared (static) or not.
mA number of methods that access a variable (attribute)
sum(mA) sum of mA over attributes of a class
LCAM (Lack of Cohesion Among Methods(1-CAM)): CAM metric is the measure of cohesion based on parameter types of methods. LCAM = 1-CAM
LTCC (Lack Of Tight Class Cohesion (1-TCC)): The Lack of Tight Class Cohesion metric measures the lack cohesion between the public methods of a class. That is the relative number of directly connected public methods in the class. Classes having a high lack of cohesion indicate errors in the design.
- https://www.codemr.co.uk/features
- https://press.princeton.edu/books/hardcover/9780691174952/the-tyranny-of-metrics
Software Metric
A software metric is a standard of measure of a degree to which a software system or process possesses some property. Even if a metric is not a measurement (metrics are functions, while measurements are the numbers obtained by the application of metrics), often the two terms are used as synonyms. Since quantitative measurements are essential in all sciences, there is a continuous effort by computer science practitioners and theoreticians to bring similar approaches to software development. The goal is obtaining objective, reproducible and quantifiable measurements, which may have numerous valuable applications in schedule and budget planning, cost estimation, quality assurance, testing, software debugging, software performance optimization, and optimal personnel task assignments.
- https://en.wikipedia.org/wiki/Software_metric
Type System
In programming languages, a type system is a logical system comprising a set of rules that assigns a property called a type to the various constructs of a computer program, such as variables, expressions, functions or modules. These types formalize and enforce the otherwise implicit categories the programmer uses for algebraic data types, data structures, or other components (e.g. "string", "array of float", "function returning boolean"). The main purpose of a type system is to reduce possibilities for bugs in computer programs[2] by defining interfaces between different parts of a computer program, and then checking that the parts have been connected in a consistent way. This checking can happen statically (at compile time), dynamically (at run time), or as a combination of both. Type systems have other purposes as well, such as expressing business rules, enabling certain compiler optimizations, allowing for multiple dispatch, providing a form of documentation, etc.
A type system associates a type with each computed value and, by examining the flow of these values, attempts to ensure or prove that no type errors can occur. The given type system in question determines what constitutes a type error, but in general, the aim is to prevent operations expecting a certain kind of value from being used with values for which that operation does not make sense (logic errors). Type systems are often specified as part of programming languages and built into interpreters and compilers, although the type system of a language can be extended by optional tools that perform added checks using the language's original type syntax and grammar.
 -https://cloud.google.com/blog/products/devops-sre/using-the-four-keys-to-measure-your-devops-performance
-https://cloud.google.com/blog/products/devops-sre/using-the-four-keys-to-measure-your-devops-performance

Quality attributes checklist is a must have tool when we are thinking of a system, either designing, developing, delivering or maintaining it.
The theory of best practice should be based on achieving only those required quality metrics at a certain point of time because it is hard ( or impossible ) to 100% guaranteed at all at once.
Tensions exists between each quality components in a system based on some context. Some are high and against each other, and others complimentary.
Experienced programmers with architectural skills ( i.e. having deep knowledge and understanding of principles and patterns of software design and the domain ) makes the necessary tradeoffs in order to deliver efficient and effective solution. Their expertise is expressed in the clever compromises to win the forces acting for or against qualities built in the desired application.
They clearly identify and select the primary qualities and start building based on them. As the system adapts and evolves in the ecosystem that it was designed for, during every refactoring, on one hand they improve existing qualities and while on the other hand they add other qualities as per demand of the users from the feedback received from the users.