amazoncaptcha
 amazoncaptcha copied to clipboard
amazoncaptcha copied to clipboard
Constantly Not Solved
Hello! I'm constantly getting the 'Not Solved' issue, I think because the training data used has a different style to the CAPTCHAs I'm getting from Amazon. The ones I get on Amazon have a line in the background of the text. I've attached an image.
 Is this something that could be included for a future implementation do you think?
Is this something that could be included for a future implementation do you think?
Thank-you so much!
Hi, the package currently supports only the captcha type found at https://www.amazon.com/errors/validateCaptcha
Although, just to mention, this is not the first time people asking for the implementation of solver for the type you've mentioned. Could you share the information on how to constantly get this type of captcha?
Yep! I get it through the gift card feature: https://www.amazon.co.uk/gc/redeem
You may have to enter a few dummy codes and click 'apply to your balance' for the captchas to begin appearing.
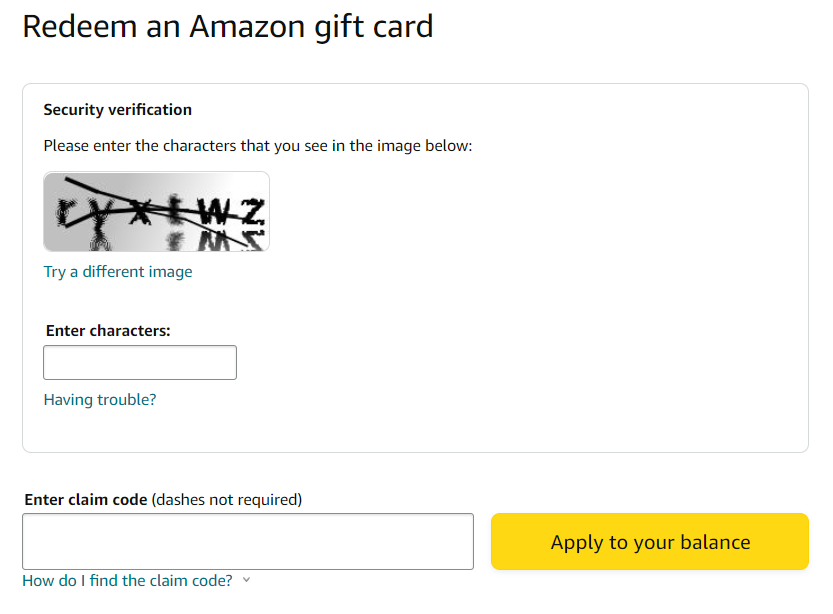
Really interested in this solution, anyway I can help or anything?
I'm not sure yet, currently a bit busy at work, so I'm not sure when I can get to this, sorry.
@a-maliarov are you looking for a way to trigger this & get images? i see from you comment https://github.com/a-maliarov/amazoncaptcha/issues/61#issuecomment-1114247618 you were asking how to do this and never received a reply.
unfortunately it is a tad harder to trigger this but i do have a consistent way to trigger this and get the link. here's what i do:
-connect to a vpn
-use a puppeteer script that launches chromium that performs the amazon auth (sign in w/ username + password)
-upon submission of the password, it will challenge you w a screen that asks you to enter your pw again and present you with the "advanced" captcha challenge like OP submitted
-inspecting the src tag on this img reveals this url: https://opfcaptcha-prod.s3.amazonaws.com/927ea861a9d24a05a829fda73bff7b7a.jpg?AWSAccessKeyId=AKIA5WBBRBBBRRCCELW3&Expires=1660299279&Signature=9Q0eNuRrPGdVWoQC%2Bc8I0Bgma8s%3D
- do note this is an AWS S3 presigned url that has a short life duration; it is possibly generated by amazon on-the-fly and not pre-rendered
if you are having trouble gaining a sample set of these more advanced captchas, i can write a node script locally on my computer that can generate a hundred or so - lmk if that would help - i could open up a branch and commit them there. but the above steps will consistently generate these captcha challenges
as an aside it looks like opfcaptcha is the name of (one of) amazon's captcha services.
 (from https://docs.aws.amazon.com/workspaces/latest/adminguide/workspaces-port-requirements.html)
(from https://docs.aws.amazon.com/workspaces/latest/adminguide/workspaces-port-requirements.html)
you can search google for "opfcaptcha" and find hits riddled with questions asking about how to solve these challenges.
to my knowledge you are the only one who might be willing to take this on, and i am game to help
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
@a-maliarov re: "Could you share the information on how to constantly get this type of captcha?"...
I wrote a little selenium to help grab a set of the AWS-style CAPTCHA images, intending to start training some models and testing...
import os
import sys
import time
import argparse
import urllib.request
import urllib.parse
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.keys import Keys
# Variables grabbed from CLI arguments
parser = argparse.ArgumentParser(
description='Download Amazon CAPTCHA examples.')
parser.add_argument(
'-e', '--email',
help="Valid AWS Account Email Address",
required=True
)
parser.add_argument(
'-c', '--count',
help="The number of CAPTCHA images to download. Default is 200.",
required=False,
default=200
)
args = parser.parse_args()
download_directory = "./CAPTCHAs/"
if not os.path.exists(download_directory):
os.makedirs(download_directory)
# ChromeDriver options
options = webdriver.ChromeOptions()
#options.add_argument('--headless')
options.add_argument("--window-size=1920x1080")
options.add_argument("--remote-debugging-port=9222")
options.add_argument('--no-sandbox')
options.add_argument("--disable-gpu")
options.add_argument('--disable-dev-shm-usage')
options.add_experimental_option("prefs", {
"download.default_directory": "./",
"download.prompt_for_download": False,
})
# Initiate ChromeDriver
driver = webdriver.Chrome(executable_path='chromedriver', options=options)
#driver.fullscreen_window()
# Allow downloading
driver.command_executor._commands["send_command"] = ("POST", '/session/$sessionId/chromium/send_command')
params = {'cmd': 'Page.setDownloadBehavior', 'params': {'behavior': 'allow', 'downloadPath': download_directory}}
command_result = driver.execute("send_command", params)
# Set the default selenium timeout
delay = 30 # seconds
# Abort function
def abort_function():
print ("Aborting!")
driver.close()
sys.exit(1)
# Wait for download function
def download_wait(path_to_downloads):
seconds = 0
dl_wait = True
while dl_wait and seconds < 30:
time.sleep(1)
dl_wait = False
for fname in os.listdir(path_to_downloads):
if fname.endswith('.crdownload'):
dl_wait = True
seconds += 1
return seconds
# Login function
def enter_username():
# Navigate to and wait for the page to load
print("Navigating to the login page...")
driver.get("https://console.aws.amazon.com/console/home")
try:
myElem = WebDriverWait(driver, delay).until(
EC.presence_of_element_located((By.ID, 'resolving_input'))
)
print ("Login page is ready!")
time.sleep(2)
# Provide a valid root account email
try:
elem = driver.find_element(By.ID, "resolving_input")
print("Entering the username...")
elem.clear()
elem.send_keys(args.email)
elem.send_keys(Keys.RETURN)
# Click the forgot password
try:
myElem = WebDriverWait(driver, delay).until(
EC.presence_of_element_located((By.ID, 'password'))
)
elem = driver.find_element(By.ID, "root_forgot_password_link")
driver.execute_script("arguments[0].click();", elem)
time.sleep(2)
# Login failed
except TimeoutException:
print (
"Failed to click the 'root_forgot_password_link' link...")
abort_function()
# Login failed or webpage had another issue, abort.
except TimeoutException:
print ("Failed to initiate login, load the webpage or there was another issue!")
abort_function()
# Webpage fails to load, abort.
except TimeoutException:
print ("Took too much time to load the webpage or there was another finding 'resolving_input'...")
abort_function()
# Download Captcha Image function
def download_captchas(total):
try:
myElem = WebDriverWait(driver, delay).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="password_recovery_captcha_image"]'))
)
try:
elem = driver.switch_to.active_element
try:
for i in range(0, total):
# refresh the captcha image
elem = driver.find_element(By.ID, "password_recovery_refresh_captcha")
driver.execute_script("arguments[0].click();", elem)
myElem = WebDriverWait(driver, delay).until(
EC.presence_of_element_located((By.ID, 'password_recovery_refresh_captcha'))
)
print("Downloading the Captcha image '" + str(i + 1) + "' of '" + str(total) + "'...")
# get the image source
img = driver.find_element(By.XPATH, '//*[@id="password_recovery_captcha_image"]')
url = img.get_attribute('src')
print("img source: " + url)
try:
# get the file name
split = urllib.parse.urlsplit(url)
filename = split.path.split("/")[-1]
# download the image
urllib.request.urlretrieve(url, download_directory + filename)
# Wait for the download to complete
download_wait(download_directory) # wait for the download to finish
except urllib.error.URLError as e:
print(e.reason)
except TimeoutException:
print("Could not download the image...")
except TimeoutException:
print("Could not switch to password_recovery dialog frame...")
abort_function()
except TimeoutException:
print("Could not find 'password_recovery_captcha_image...")
abort_function()
# Navigate to the AWS root login for password reset
enter_username()
# Download the captcha
print("Downloading '" + args.count + "' CAPTCHA images...")
download_captchas(int(args.count))
# Close the ChromeDriver
driver.close()
It basically just continually refreshes the password reset CAPTCHA image and downloads them. I've done up to 2000 at once and AWS didn't ban my IP or anything ;) ... Here's a link to the batch of 5000 images I'd collected using that code: AWS-CAPTCHAs.zip
This project looks absolutely fantastic, great stuff! It would be pretty cool if it was capable of solving the AWS-style CAPTCHA as well. Since I just started looking into trying to accomplish this again (the last time was ~2 years ago) I will look through the code here in amazoncaptcha (I only just discovered today) and see if/how I can contribute.
There are certain observations I was starting with: like... step 1) take the image and cut off the bottom 45% (mirror image portion), and ~15% of the top (where junk is added), and do some other basic clean up, at the time I'd thought of using techniques found in https://github.com/danielpontello/cnn-captcha-solving ... and I've solved enough by hand/eye to know things like it's always a "g", if ever in doubt...or, similarly, it's always a "y", never an "x". I was never sure what to do with that.
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.