SwiftPackageIndex-Server
 SwiftPackageIndex-Server copied to clipboard
SwiftPackageIndex-Server copied to clipboard
Back-end support for gathering author information
- [ ] Extend schema
- [ ] Collect data
Here's a basic plan:
- Any contributor with more than 10 commits is eligible to be listed here. This rule will save projects where someone fixes a typo in a README in a newly released project with just an "Initial commit."
- For all eligible contributors, they are listed if they have made more than 5% of the total commits.
- The name should be fetched from the GitHub API for the username
- The link should go to the contributors GitHub profile.
Some git commands to get info:
- commit counts
git shortlog -sne
❯ git shortlog -sne
11318 swift-ci <[email protected]>
6523 Doug Gregor <[email protected]>
5113 Slava Pestov <[email protected]>
4536 Chris Lattner <[email protected]>
4444 Dmitri Gribenko <[email protected]>
4409 Joe Groff <[email protected]>
So looking at apple/swift as an extreme example (and obviously not a package!) we'd be getting this result:
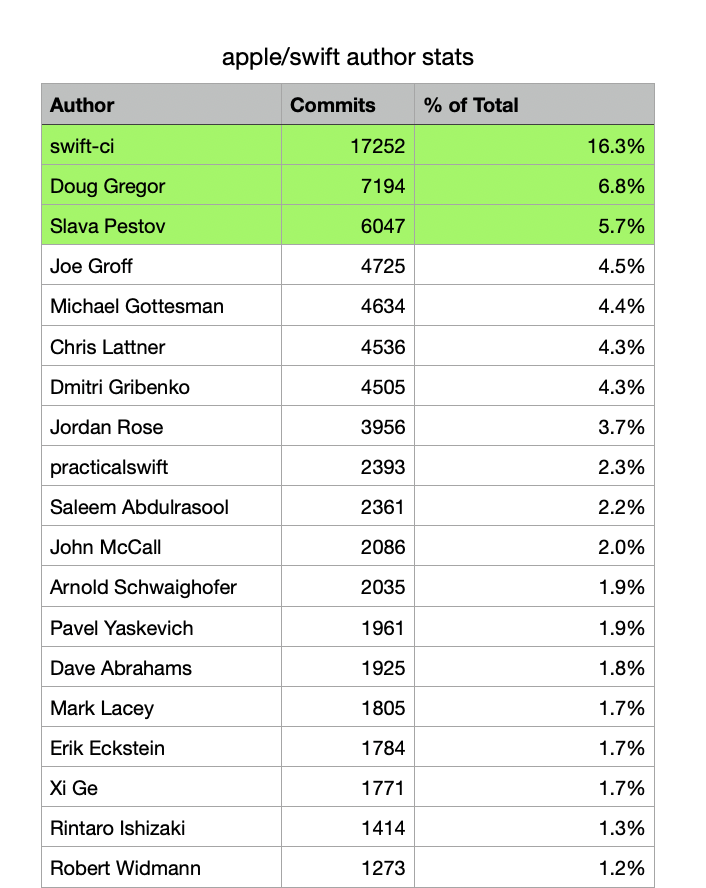
It's probably not a typical result in the sense that the ci bot is in there but I think it hints at another potential issue and one where stats we gather could cause some bad vibes: I'm sure there are going to be many cases where the cutoff is going to be unfortunate.
I guess we could come up with algorithms to call it a "Team effort" where are aren't any obvious cliffs but this is going to be fiddly...
My gut feeling is that this is perhaps better left to the package maintainers to control via the metadata file.
In any case, gathering the stats is pretty straighforward, so I'll prep the schema for it and start filling the db.
One big technical problem I see is with respect to the Github lookups: that's going to blow our request budget very easily. I think we're currently making 3 requests per package but this will easily double or triple that and make it dependent on factors we don't directly control.
I think without having a GraphQL approach that'll allow us to get everthing in one or two requests and in a controlled manner this is going to be tricky.
It's probably not a typical result in the sense that the ci bot is in there but I think it hints at another potential issue and one where stats we gather could cause some bad vibes: I'm sure there are going to be many cases where the cutoff is going to be unfortunate.
I guess we could come up with algorithms to call it a "Team effort" where are aren't any obvious cliffs but this is going to be fiddly...
Yea, I don't think we should try and spend too much time thinking about this because as you noted, the solution to this is to let package maintainers define their own author's list. We should get a very basic version implemented, warts and all, and then make the top priority the adoption of that metdata file so we have somewhere to point people if they don't like the data we're gathering.
One big technical problem I see is with respect to the Github lookups: that's going to blow our request budget very easily. I think we're currently making 3 requests per package but this will easily double or triple that and make it dependent on factors we don't directly control.
This is a great point, and I just had a whole solution to the problem typed up and then deleted it all in favour of something simpler. 😂 If you want the authors on our Package pages to link to your GitHub profile, or your Twitter, or anything, you implement the metadata file. It's that simple. We gather author information from the local git repository and show the name from there. No link.
We should put a link at the end of this to a FAQ about author information, and that's it. No GitHub API requests at all. What do you think?
I think that's best and great point about where to link to. I guess a lot of people would actually prefer a Twitter link or something. (Although we'll probably have to spam proof the metadata file at some point...)
I'll get to pulling in the author info. Dropping the requests will make it a lot simpler!
We'll probably have to spam proof the metadata file at some point...
Almost certainly, but the fact that it's a file in a git repository makes it immune to bots, which are the main problem. I'll probably be wrong, but I don't think it's going to be a huge issue. 😬 You should keep a link to this comment handy to shove in my face when I'm wrong 😂
Should we push towards populating the author field via metadata entirely instead of trying to parse it from git?
Should we push towards populating the author field via metadata entirely instead of trying to parse it from git?
That's a good idea, but we should have all other fields (categories, description, etc...) ready to go before we ask people to do this. Getting them to add their author information is a nice carrot to get them to adopt this file fully, so we should have a nice template file for them to copy and amend, including all the fields before we do this.
I think we can close this, as the plan is now to collect this via the metadata file and not the git repo itself. Do you agree, @daveverwer ?
There's a part of me that wants to still parse out author information from the git repository. One problem with relying completely on the metadata file is that when it doesn't exist for a package, we'll have nothing to show for authors, and so will probably omit the author information completely.
If we parse out information from git, it won't be perfect, and it won't have links, but it will show something. Package authors can then get curious about how to fix/change the information we have parsed, and it might drive adoption of the metadata file as they'll discover all the things they can do with it.
I think I'd like to leave this open and consider it again when we actually get to implementing this.