hardhat
 hardhat copied to clipboard
hardhat copied to clipboard
TransactionExecutionError: Headers Timeout Error
Bug Description
When running long tests on harhat network all transactions start failing and then it stalls.
Reproducible By
This snippet should do the trick:
for (let j = 0; j < 1000000; j++) {
const amountIn = '1000';
const [signer1] = await ethers.getSigners();
const swapRouter = ISwapRouter__factory.connect('0xE592427A0AEce92De3Edee1F18E0157C05861564', signer1);
const recipient = signer1.address;
await waitEthersTx(swapRouter.exactInput({
// WETH -> USDC 3000 fee
path: "0xC02aaA39b223FE8D0A0e5C4F27eAD9083C756Cc2000bb8A0b86991c6218b36c1d19D4a2e9Eb0cE3606eB48",
amountIn: amountIn,
deadline: constants.MaxUint256,
recipient,
amountOutMinimum: 1,
}, {
value: amountIn,
}));
}
Expected Behavior
It should be working without issues
Logs & Screenshots
Transaction fails with
TransactionExecutionError: Headers Timeout Error
at HardhatNode.mineBlock (/Users/pzixel/Documents/Repos/test/node_modules/hardhat/src/internal/hardhat-network/provider/node.ts:478:15)
at async EthModule._sendTransactionAndReturnHash (/Users/pzixel/Documents/Repos/test/node_modules/hardhat/src/internal/hardhat-network/provider/modules/eth.ts:1496:18)
at async HardhatNetworkProvider.request (/Users/pzixel/Documents/Repos/test/node_modules/hardhat/src/internal/hardhat-network/provider/provider.ts:118:18)
at async EthersProviderWrapper.send (/Users/pzixel/Documents/Repos/test/node_modules/@nomiclabs/hardhat-ethers/src/internal/ethers-provider-wrapper.ts:13:20)
Caused by: HeadersTimeoutError: Headers Timeout Error
at Timeout.onParserTimeout [as _onTimeout] (/Users/pzixel/Documents/Repos/test/node_modules/undici/lib/client.js:1005:28)
at listOnTimeout (node:internal/timers:561:11)
at processTimers (node:internal/timers:502:7)
Environment
Node 16.5.0, Macos 12.3.1 M1 Pro (but I'm pretty sure it's doesn't matter)
Hardhat config if relevant:
const networks: NetworksUserConfig = {
hardhat: {
forking: {
url: myurl,
},
chainId: 1,
},
};
This issue is also being tracked on Linear.
We use Linear to manage our development process, but we keep the conversations on Github.
LINEAR-ID: d203952e-41c3-4764-a380-1abb7cff8d1e
Thank you for using Hardhat. Can you provide a more complete reproduction scenario? Perhaps in a separate repo or in an attachment? Something I can easily just run. Thanks.
I also have this issue. I tried upgradeProxy with an impersonated instance of the proxy contract to be upgraded. It's not really long running but quite some work to upgrade an upgradable contract.
I'm struggling with this, too. I call a function on a smart contract which takes a while to finish and get this error:
HeadersTimeoutError: Headers Timeout Error
at Timeout.onParserTimeout [as _onTimeout] (/dev/collab/node_modules/undici/lib/client.js:1005:28)
at listOnTimeout (node:internal/timers:559:11)
at processTimers (node:internal/timers:500:7) {
code: 'UND_ERR_HEADERS_TIMEOUT'
}
What exactly is causing this Timeout Error? I'm using mainnet fork via Alchemy. Is this timeout caused by Alchemy, Hardhat or the undici lib?
I've got it on two different endpoints (non-alchemy ones) so this must be a hardhat issue.
I might try creating a MRE but I will only be able to do so in 2 weeks or so. I hope someone comes with better example earlier.
I only got it on a hardhat local node when I was forking from a Polygon mainnet via a public node. There might be a timeout when getting the data from the live node. If I repeat the command a couple of times it disappears. Obviously when all data are downloaded the the local node eventually.
I'm closing this because it sounds like Hardhat is behaving as expected.
This error message is simply the result of a network timeout, and the mere presence of this message does not indicate a problem with Hardhat, and GitHub Issues are intended to be used exclusively for problems in Hardhat itself.
There are many reasons why such a timeout may occur, including a problem on the endpoint (eg public node). It could also be the case that the computation you're requesting the node to execute may simply be a longer-running computation than the timeout values that have been configured at various points in the networking stack (both on the client and on the server).
If anyone suspects a problem that actually lies within Hardhat, please feel free to re-open this Issue, and, ideally, provide a minimal, reproducible example.
I've taken a pcap, 100% of the RPC calls were responded to. There was one call that looked like it took 1 second to respond.
Here is each request and the latency of the request.
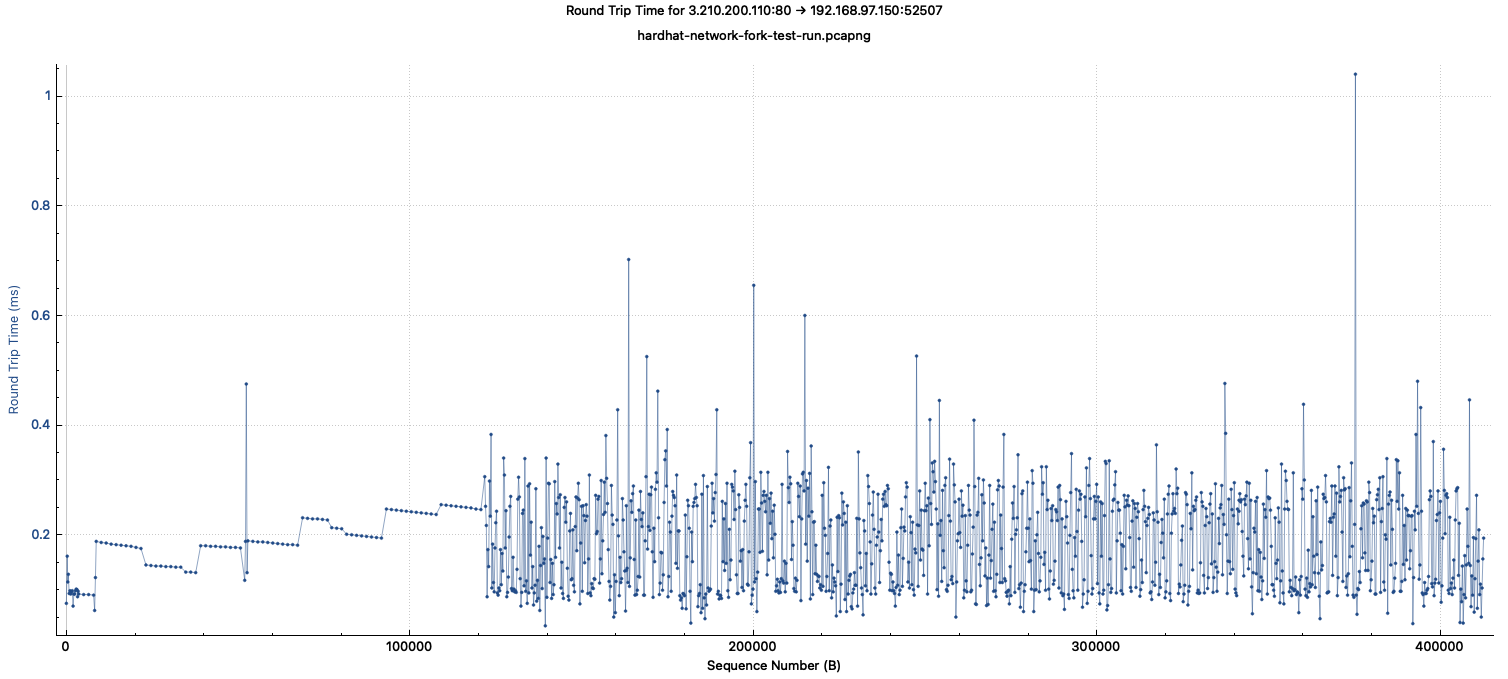
RPC HTTP Status codes

I'm not seeing any timeouts on the wire or from the server, of which I'm the only client using.
@bretep thank you for this. I've re-opened the issue. Clearly this isn't necessarily an issue connecting to the remote node. In particular, the presence of HardhatNode.mineBlock() in the call stack, which I hadn't noticed before your confirmation here, points a finger at Hardhat.
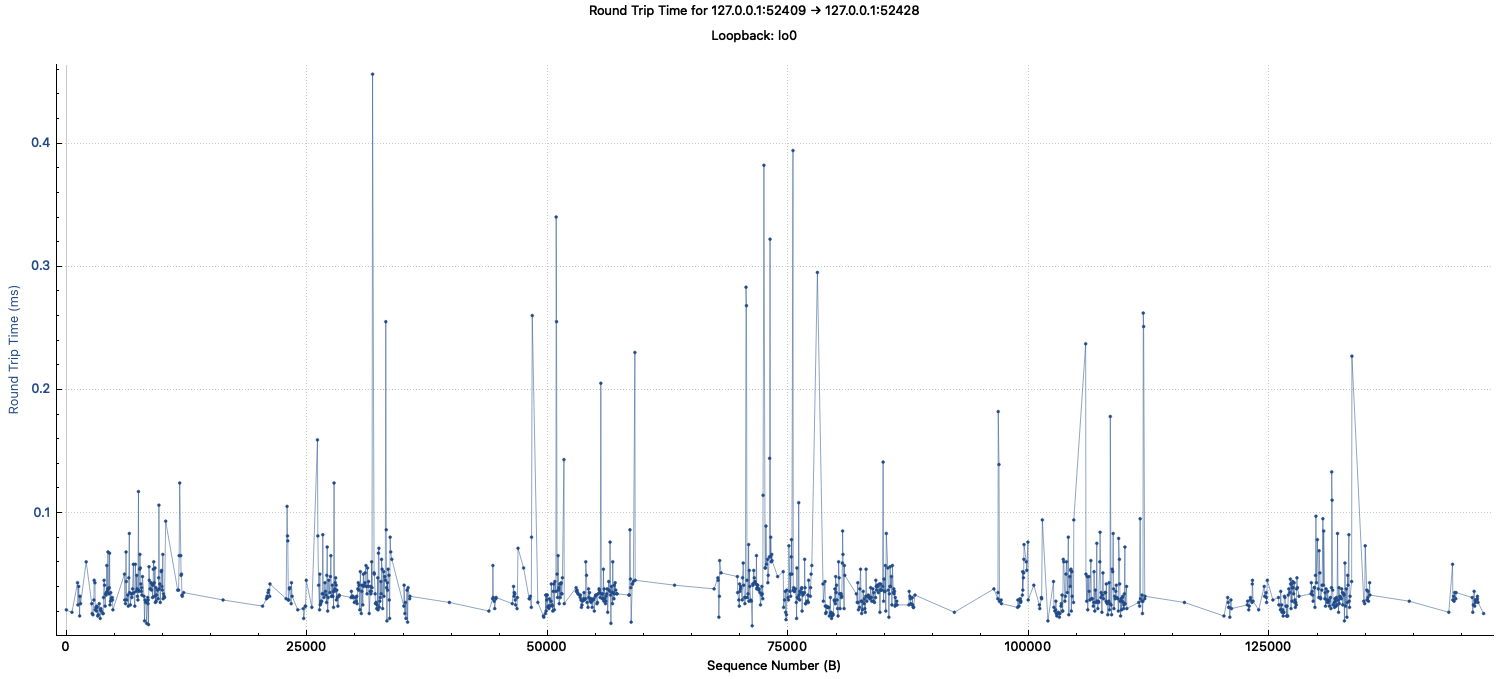
Are you able to configure Wireshark to also capture loopback traffic? (I know that is easier on some systems than others.) That would capture this activity, if I'm understanding the scenario correctly.
Also, can you confirm that you have the same symptoms as in the original Issue description? In particular, I'm interested in hearing whether HardhatNode.mineBlock() appears in your call stack.
Finally, would you happen to have a reproducible scenario for this? Even with all these wonderful clues, without a reproduction it will be difficult to even diagnose this, much less get it fixed.
Thanks again!
@bretep thank you for this. I've re-opened the issue. Clearly this isn't necessarily an issue connecting to the remote node. In particular, the presence of
HardhatNode.mineBlock()in the call stack, which I hadn't noticed before your confirmation here, points a finger at Hardhat.Are you able to configure Wireshark to also capture loopback traffic? (I know that is easier on some systems than others.) That would capture this activity, if I'm understanding the scenario correctly.
Also, can you confirm that you have the same symptoms as in the original Issue description? In particular, I'm interested in hearing whether
HardhatNode.mineBlock()appears in your call stack.Finally, would you happen to have a reproducible scenario for this? Even with all these wonderful clues, without a reproduction it will be difficult to even diagnose this, much less get it fixed.
Thanks again!
Yes, I can. I'll do that once I get back to my computer. It's going to be a few hours.
Hi, I've captured the loopback device. I didn't see anything that took more than 0.5ms.
I'll see what I can do about a reproducible scenario.
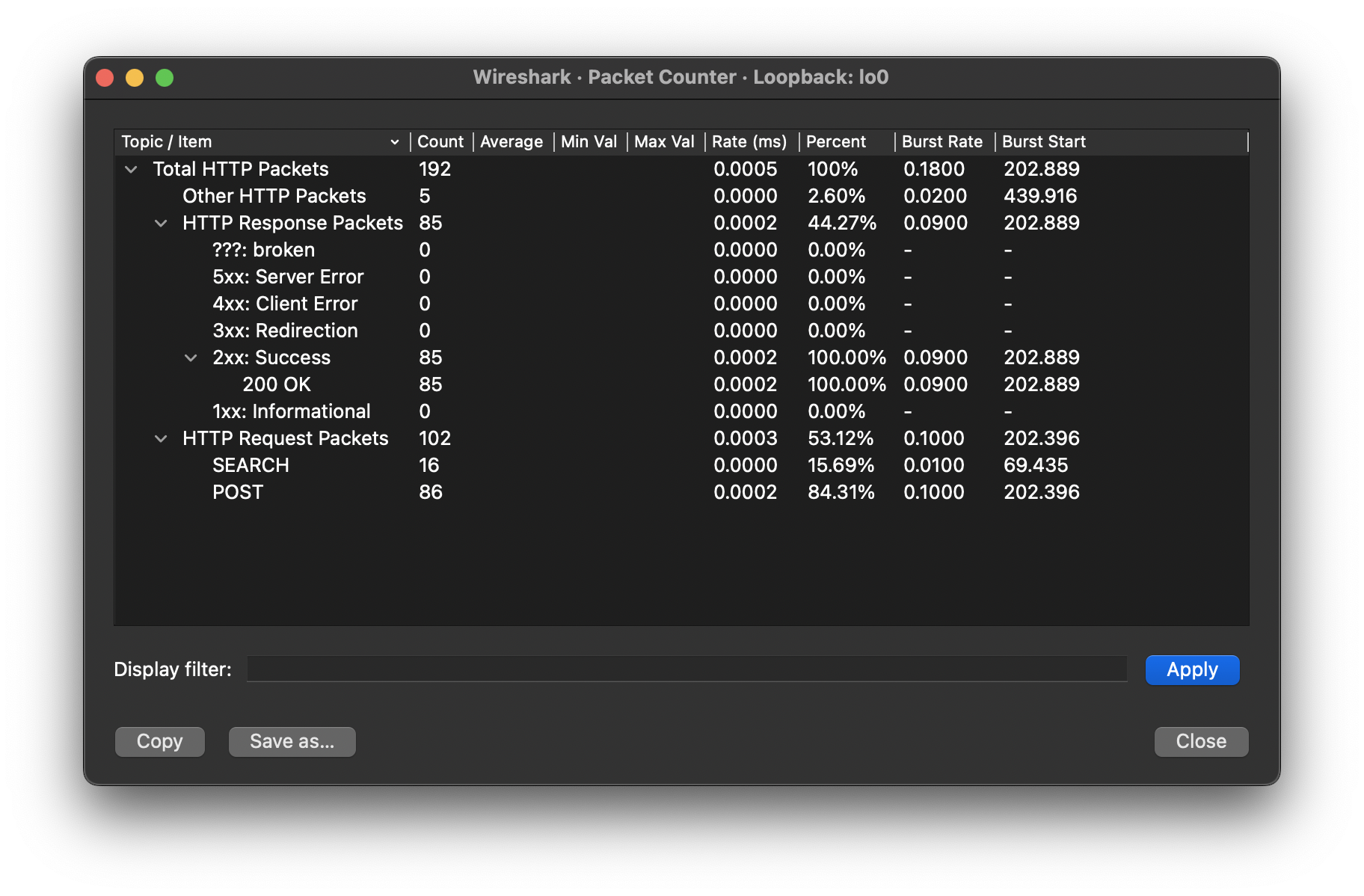
hardhat v2.9.6 Specifically getting the following error:
HeadersTimeoutError: Headers Timeout Error
at Timeout.onParserTimeout [as _onTimeout] (node_modules/undici/lib/client.js:1005:28)
at listOnTimeout (node:internal/timers:561:11)
at processTimers (node:internal/timers:502:7)
To lend some credence to the mined block thread while i work on a minimum viable, these are some of the errors that I see. While I do not see the same error, but it seems very similar: takes a long time to do anything / mine a block
Mined block #14361014
Block: 0xd6005a46c9070513722990be5765c6f465178475e91be0e69c2b7c2ecbd50886
Base fee: 0
Transaction: 0xf5ba928fb13b3a7f0e5472d16497fd45914832e51d439f4701c006586dcd987e
Contract call: Swap#uniswapV3ExactInputSingle
From: 0xf42b8cf17ad3bbc0a203b2d2b5e7be373650f456
To: 0x9d634360c39aa1b9a75b013a66a137bb390924d5
Value: 0 ETH
Gas used: 9692216 of 10000000
Error: Transaction reverted without a reason string
at <UnrecognizedContract>.<unknown> (0xc2e9f25be6257c210d7adf0d4cd6e3e881ba25f8)
at <UnrecognizedContract>.<unknown> (0xe592427a0aece92de3edee1f18e0157c05861564)
at Swap.uniswapV3ExactInputSingle (contracts/Swap.sol:208)
at async HardhatNode._mineBlockWithPendingTxs (.../node_modules/hardhat/src/internal/hardhat-network/provider/node.ts:1773:23)
at async HardhatNode.mineBlock (.../node_modules/hardhat/src/internal/hardhat-network/provider/node.ts:466:16)
at async HardhatModule._intervalMineAction (.../node_modules/hardhat/src/internal/hardhat-network/provider/modules/hardhat.ts:175:20)
at async HardhatNetworkProvider._sendWithLogging (.../node_modules/hardhat/src/internal/hardhat-network/provider/provider.ts:139:22)
at async HardhatNetworkProvider.request (.../node_modules/hardhat/src/internal/hardhat-network/provider/provider.ts:116:18)
at async MiningTimer._mineFunction (.../node_modules/hardhat/src/internal/hardhat-network/provider/provider.ts:325:9)
at async MiningTimer._loop (.../node_modules/hardhat/src/internal/hardhat-network/provider/MiningTimer.ts:98:5)
this is a simple uniswapv3 swap, which should only cost <50k gas, but for whatever reason, it ends up costing near the hard coded gas limit provided by the client. this gas usage varies wildly but is almost always > 1m
when i try to inspect the transaction using hardhat-tracer, i get this error https://github.com/zemse/hardhat-tracer/issues/16
minimal.zip i attempted to create a minimal example - did not quite get all the way to the originally mentioned header error, but got to the one i posted above.
yarn
yarn run compile
yarn run fork # separate terminal to view logs
yarn run start
it should stop after mining the 3rd tx and hit the failure with the high gas consumption on the 4th - after stalling for a couple minutes
#1 deploy #2 approve #3 deposit weth #4 swap - odd failure
to see the 0x0 error one has to add their transaction hash to the following command:
node_modules/.bin/hardhat --network hardhat trace --hash 0x99e005a537c5e8639c0cf75db734c78504fc53005895b8decfe7e5ae4ab4f3b9 --rpc http://localhost:8545
This Issue has been added to the team's backlog. Thanks @3commascapital for your help on this repro!
also, just some extra information, it looks like, both the hardhat fork as well as the polling side get "stuck", as in when one is polling for a transaction hash, the requests return just fine the first couple of rounds, but often on the 3rd check (on a ~1s poll interval and a 3s block time) the response for eth_getTransactionReceipt freezes as well - is there an internal db that is locking transaction receipts there which could offer a clue?
not sure if it's the same issue, but i also got this error recently
hardhat_intervalMine
Unexpected error calling hardhat_intervalMine: TransactionExecutionError: the tx doesn't have the correct nonce. account has nonce of: 31 tx has nonce of: 27 (vm hf=arrowGlacier -> block number=14361621 hash=0x5f9b8d32f78e2086dacb20d46304b4454311de11312a92a108a977bdcf0df80a hf=arrowGlacier baseFeePerGas=0 txs=0 uncles=0 -> tx type=0 hash=0x8c9b94664842afe482f39bff752c65bcbfc8faf3ad75572d36bd2238af5ab374 nonce=27 value=0 signed=true hf=arrowGlacier gasPrice=1000000000)
found it kind of odd that the nonce was having difficulties given that the system that is testing this / where this is happening is fairly solid
I would really like to see this issue resolved. So far it seems like it's a stochastic error to me... sometimes it happens, sometimes it doesn't (with the same exact code). Not sure if it depends on network latency, or some other random parameters... been trying things out for 3 hours and can't put my finger on it.
UPDATE: I managed to solve this problem this morning by increase the timeout parameter on my localhost connection...
localhost: {
timeout: 100_000
},
Seems like the local node has to do a lot of calls to the backend forked network, and this takes ages... but I feel like hardhat should give users a much more explicit error message; perhaps suggesting this fix?
I also managed this issue using the following configuration.
module.exports = {
solidity: "0.8.4",
defaultNetwork: "kovan",
networks: {
hardhat: {},
kovan: {
url: API_URL,
accounts: [0x${PRIVATE_KEY}]
}
},
mocha: {
timeout: 400000000
},
etherscan: {
apiKey: ETHERSCAN_API_KEY
}
}
This issue was marked as stale because it didn't have any activity in the last 30 days. If you think it's still relevant, please leave a comment indicating so. Otherwise, it will be closed in 7 days.
On our internal backlog, I've bumped this up to the highest priority, so that if nothing else it will be discussed by the team. I can't make any promises about whether it'll stay at that priority, much less about when we might add it to our schedule, but once we've discussed it and made such some decision then I'll report back here.
If anyone wants to tackle this, take a look at https://github.com/NomicFoundation/hardhat/issues/3136