Reinforcement-learning-with-tensorflow
 Reinforcement-learning-with-tensorflow copied to clipboard
Reinforcement-learning-with-tensorflow copied to clipboard
Published
20 hours ago •
 MorvanZhou
MorvanZhou
关于策略梯度和PPO中目标函数的几个问题。
莫烦您好,请教您下面几个问题:
- DPPO中关于PPO的伪代码
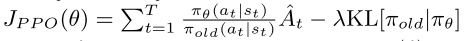 这一部分是计算从t=1到T新旧策略ratio的累加值。但是您代码中的实现是求得tf.reduce_mean,这应该是和这个目标函数相匹配:
这一部分是计算从t=1到T新旧策略ratio的累加值。但是您代码中的实现是求得tf.reduce_mean,这应该是和这个目标函数相匹配:
 我很困惑这两种目标函数到底哪个是正确的?或者说都正确,那么有什么区别?
我很困惑这两种目标函数到底哪个是正确的?或者说都正确,那么有什么区别? - 关于PG和PPO的目标函数。
这个问题和上个问题有点类似。下图是传统PG的目标函数:
 这是对轨迹求期望,所以计算t=1到T的累加值。但是PPO的目标函数如下:
这是对轨迹求期望,所以计算t=1到T的累加值。但是PPO的目标函数如下:
 这个是对action-state pair来求期望,我不太理解怎么从对轨迹求期望变换到对action-state pair求期望。
这个是对action-state pair来求期望,我不太理解怎么从对轨迹求期望变换到对action-state pair求期望。 - 关于PG本身的目标函数好像都有这两种写法:
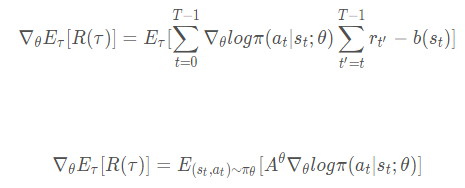 第一个绝对是对了,第二个我就不知道怎么理解了?
第一个绝对是对了,第二个我就不知道怎么理解了?
希望得到莫烦老师的帮助!