diagnose
 diagnose copied to clipboard
diagnose copied to clipboard
Alternative `codespan-reporting` style formatting?
Thanks for your great library!
I use both Rust and Haskell, and have learned about error reporting libraries like ariadne and codespan-reporting for a while. Previously when working on a Rust project, I chose codespan-reporting because I preferred its formatting (formatting of ariadne is also beautiful, but a bit too fancy for me), given their interfaces are pretty similar. Is it possible to extend this library to have an alternative codespan-reporting-style formatting for the diagnostic messages? Or is there some design space to expose an API for custom report formatting?
FYI, here is a comparison of the said two styles (BTW it is amusing to see a more Haskell-like syntax for illustration in codespan-reporting the Rust library but a more Rust-like style here):
| Name | Illustration |
|---|---|
(current) ariadne-style |
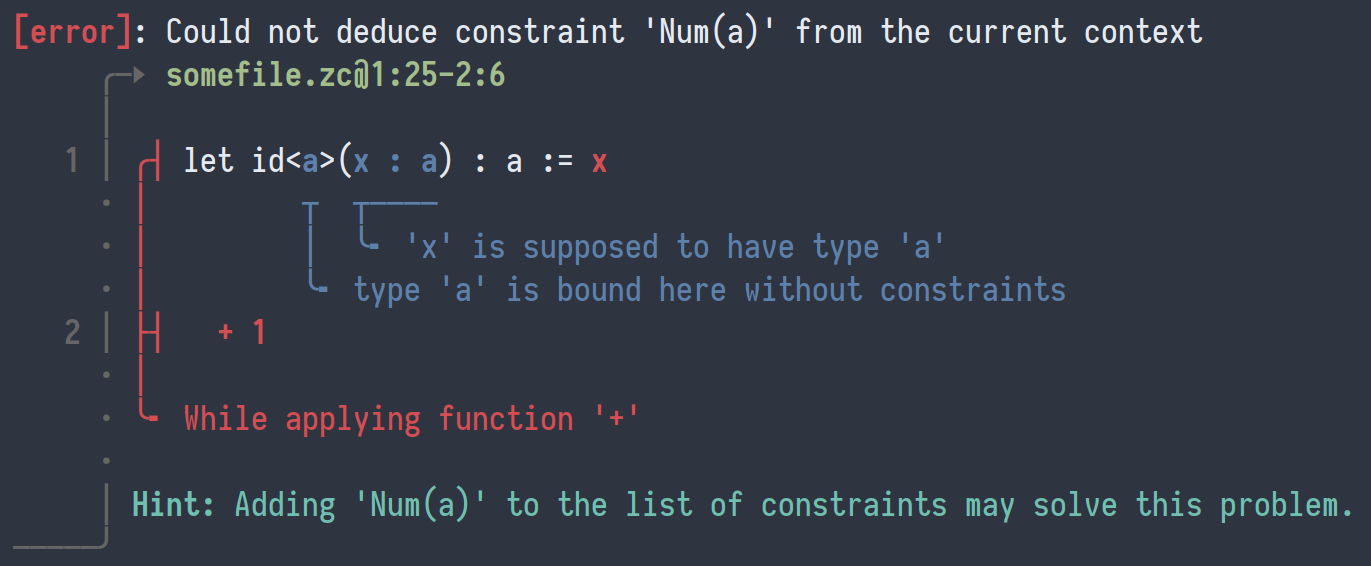 |
codespan-reporting-style |
 |
If this is deemed non-trivial, I am willing to work on this, in that case would you please provide some guidance?
One of the major setbacks would be the need to expose the internal definitions of e.g. reports, diagnostics, etc. (mainly all that is present in X.Internal modules which isn't exported by the X modules)
Either that or allowing to freely format markers (which seem like most of the differences there to me).
However, if we allow retrieving files from a given Diagnostic, then it would be quite “easy” to change the overall style of reports⁽¹⁾.
But only if writing a function Diagnostic msg -> Doc Annotation is not that much of a burden (which, believe me, it is).
If this is a feature that is very much wanted, then there are a few changes that will need to be done:
- If we want the layout to be 100% customisable:
- First of all, the
printDiagnosticandprettyDiagnosticfunctions will need to take a “layout” function (of typePretty msg => Diagnostic msg -> Doc Annotation) which will be in charge of creating the to-be-renderedDocument - Once this is done, we need to refactor the current layout (under, e.g., a
Error.Diagnose.Layoutmodule). Then copy all the layouting work within the moduleError.Diagnose.Report.Internalto that module (or a submodule) - Afterwards, you should be able to freely define your own layout (we may create a simply type alias
type Layout msg = Diagnostic msg -> Doc Annotationfor shortness' sake) but this is the hardest part, as it means that all the internal logic must be reimplemented for your new layout (which is about 80-90% of the whole codebase, for the current layout). To facilitate creating new layouts, we may also expose helper functions which would compute extra information (for example, marker column offset in spaces or unicode codepoints)
- First of all, the
- if we only want to only minor tweaking of the overall layout (such as marker style):
- We should be able to pass very simple functions (within records, for example) which take specific information (for a marker, its line, column in unicode codepoints, computed length in number of spaces, and its style ─ error, warning, etc. ─) and output a part of a
Doc Annotation
- We should be able to pass very simple functions (within records, for example) which take specific information (for a marker, its line, column in unicode codepoints, computed length in number of spaces, and its style ─ error, warning, etc. ─) and output a part of a
I am much less confident in the 2nd alternative, even thought the 1st one is actually way harder to implement. So I am not quite sure what's the correct way to go. What do you think about this? Are there any other alternatives that I did not mention?
⁽¹⁾: we are already able to retrieve Reports from Diagnostics and Markers, Notes, etc. from Reports. The only missing piece of data is files to be included in the report itself.
Thanks for your reply! I am still learning my way in the code base, so I cannot comment about the proposed approaches yet. Actually, after submitting this issue, I pulled your repo down on my local Windows machine and encountered a link error, for which I believe wcwidth is to blame. There is already an unpublished fix in their GitHub repo (solidsnack/wcwidth#3), but it involves a package named rset which is not in stack LTS and also not updated for years. I believe the fix there could be improved by replacing the linear search logic (thus also get rid of the dependency on rset) with a binary search based on arrays, so I am currently preparing a PR for that package. I will come back in a few days after I finish that PR and get familiar with the code here.
I can take a look at how to structure that (and the best way to do it, although I may have an idea already) and maybe start working on it in a separate branch if you want me to. :)
As for the bug with wcwidth, I thought that the aforementioned fix was already published on Hackage, but looking back at the last update, it is not. This is definitely worthwhile to also work on this in order to make Diagnose usable on Windows.
I have just uploaded my changes to wcwidth here. I removed the dependency on rset and replaced it with a binary search based on array. I also added a test suite to verify my implementation is correct. It seems that the owner of wcwidth now has little interest in Haskell, and that is probably the reason why the Hackage package is still not updated.
And regarding Windows support, I have a bad news to tell: GHC's support for Unicode output through standard IO on Windows in general is still messy. I see a MR on GitLab that claims to fix it, but I cannot find the RTS switch --io-manager=native in GHC 9.0.2 (which is the latest GHC in stack LTS). A plain run of the test suite here results in a crash, and with with-utf8 the program stops crashing, but shows some question marks in the output:

Alright so there's basically nothing we can do regarding the Unicode + Windows combination, other than proposing alternative ASCII layouts (which is already the case for the default layout, although it looks less fancy that way). Not sure what to do about that issue. Haskell support on Windows is still rather poor, from all those years being mainly a Unix-favored language (this should be changing as we are speaking, but turns out this isn't quite fast-paced).
Sorry, I should have experimented more before posting the last comment. Stack did not recognize GHCRTS="--io-manager=native", so I assumed GHC 9.0.2 did not have this. But it turned out both GHCi (with ghci +RTS --io-manager=native) and the test-suite (I found the executable manually and fed it the same RTS argument) is working correctly (at least in my settings):

So GHC's Windows support is changing, and the current progress in fact looks quite promising.
(BTW, I should be using the latest release of stack, but it reported that the cabal file in this repo was generated by a newer version of hpack. Just out of curiosity, are you using a dev-build in your workflow?)
I absolutely hate the fact that everything is misaligned, and it looks like Windows is trying its best to render the unicode box characters but absolutely fails to do so with the correct width. But it's better than nothing I guess.
(BTW, I should be using the latest release of stack, but it reported that the cabal file in this repo was generated by a newer version of hpack. Just out of curiosity, are you using a dev-build in your workflow?)
I am not, so this is a bit weird.
$ stack --version 2.7.5 x86_64 hpack-0.34.7
But I don't remember which version I used to generate the .cabal file (might have been stack 2.7.3 at the time).
This is what I have, yet another peculiarity I guess:
$ stack --version
Version 2.7.5, Git revision ba147e6f59b2da75b1beb98b1888cce97f7032b1 x86_64 hpack-0.34.4
So stack is actually shipping officially the same version 2.7.5 with different hpack on different platforms ...
This shouldn't be a problem at all if your version of hpack managed to work correctly. :)
I started refactoring and moving code as per the first part of my first suggestion, in the branch custom-layouts.
For now, this is a simple move of the code which originally resided in the Error.Diagnose.Report.Internal package.
Note that I have isolated the ariadne-like layout inside its own package, in order to allow the user to choose which layout to use (if any at all, this is unnecessary when only the JSON backend is interesting).
Documentation has not been updated at all (there will be A LOT of places to update it), but all the rendering tests pass and give the same results as before.
As of now, we should try to see which parts of the code for the ariadne layout would be better off inside the Error.Diagnose.Layout module as helper functions (for example, the function to retrieve and colorize a line of code named getLine_).
I think this should be easier if multiple layouts are defined concurrently.
~~Also note that tests have been put in the diagnose-ariadne subpackage but they don't really belong there.~~
~~I'll move them later to somewhere else.~~
They have been moved to a global package within the repository.
I have just submitted solidsnack/wcwidth#6, but I am not very positive that wcwidth will be updated soon on Hackage. Given that the code there is just a bunch of Unicode data plus searching logic (which I have just reimplemented), I believe you can also copy-paste the relevant code here. (Especially so if you are okay with always using the Haskell implementation of wcwidth function.)
As of now, we should try to see which parts of the code for the ariadne layout would be better off inside the
Error.Diagnose.Layoutmodule as helper functions (for example, the function to retrieve and colorize a line of code namedgetLine_).
I have just started reading your code in the custom-layout branch. I guess I will try to write a prototype of codespan-reporting style layout based on the current ariadne layout, and then we will see which parts are common.
This shouldn't be a problem at all if your version of
hpackmanaged to work correctly. :)
Actually stack refused to regenerate the cabal file if the local hpack version is older than the one that was used to generated the current copy of cabal file. But I guess that is okay for now, I can just avoid editing package.yaml.
I have just submitted https://github.com/solidsnack/wcwidth/pull/6, but I am not very positive that
wcwidthwill be updated soon on Hackage. Given that the code there is just a bunch of Unicode data plus searching logic (which I have just reimplemented), I believe you can also copy-paste the relevant code here. (Especially so if you are okay with always using the Haskell implementation ofwcwidthfunction.)
If the pure Haskell implementation is fully compliant with the “original” C version, I am not that bothered by including it inside this library. It'd be much better though if this could be included within a new Hackage release of the wcwidth library, for reusability's sake.
Maybe we could somehow "hijack" the package by pushing updates ourselves (as long as the original author is okay with it)?
Not sure how all this works on Hackage.
Actually stack refused to regenerate the
cabalfile if the localhpackversion is older than the one that was used to generated the current copy ofcabalfile. But I guess that is okay for now, I can just avoid editingpackage.yaml.
Ah! I did not know that. You should not have to change any package.yaml in the two libraries (maybe only the tests, but you could just delete the diagnose-tests.cabal if you need to regenerate it, I don't think this is a real problem for a package not meant to be pushed anywhere).
I have just started reading your code in the
custom-layoutbranch. I guess I will try to write a prototype ofcodespan-reportingstyle layout based on the current ariadne layout, and then we will see which parts are common.
I also had the idea to create a few more layouts (e.g. GCC-like) just for the sake of it, sort of to demonstrate the capabilities of this library, and perhaps give more choice regarding the output format. I think this will also help seeing which parts will need to be common.
For now, if you need something from my code, feel free to copy-paste it, as it will make it easier to see what's in common later. :)
In the meantime, I went ahead and implemented a GCC-style layout (and style) for the library. Currently, this looks like this (this uses the same error as the one from the table of the issue):
- with Unicode characters:

- with plain ASCII characters:

I'll wait a bit to push it onto the branch, as I have done some changes to how the code is organised in other modules too (such as Error.Diagnose.Style).
Basically, I moved all the annotation generation and handling within specific Error.Diagnose.Style.XXX (where XXX is e.g. Ariadne or GCC) to where the layout are created.
This allows a better handling of annotations: for example, the GCC layout does not use the original annotation RuleColor (as there is no rule), so it uses its own annotation data type (where other minor tweaks have been performed too).
Thanks to that, the library is basically plug and play (given that the layout you want is already done) and can use different styles for different layouts (given that the style is bundled with the layout, but if the annotation type is exposed, one can also create its own style).
for example, the GCC layout does not use the original annotation
RuleColor(as there is no rule), so it uses its own annotation data type
I guess similar things happen in codespan-reporting style, too. Though of course most annotations should be reusable, so after I finish debugging my implementation I should probably come up with a way of code reuse other than copy-paste-modify.
I have been fighting with stack and GHC for debugging for a while, because the stack I use was built with GHC 8.10.4 and therefore has no support for --io-manager=native. Currently I go with producing the test suite executable and manually invoke them with appropriate RTS parameters. In the mean time I am also compiling stack with GHC 9, so either way I should hopefully be able to finish my prototype and share with you on GitHub in one or two days.
I guess similar things happen in
codespan-reportingstyle, too. Though of course most annotations should be reusable, so after I finish debugging my implementation I should probably come up with a way of code reuse other than copy-paste-modify.
Unfortunately, I don't think that reusability is doable here.
Annotations are pretty much dependent on the layout used: what's the point of e.g. RuleColor for a layout without rules? or any other annotation which does not make sense for whatever reason? and how to handle additional/modifications of annotations that do not make sense in other layouts (I have examples for these, such as the Angular 9 layout which changes the background color of line numbers)?
If we want to add or modify annotations on a per-layout basis, we shouldn't have to change the core of the library (basically Error.Diagnose.Style), hence why I moved them directly in each layout package.
This will introduce some sort of redundancy (well, not that much because everybody names their annotations however they want), I agree with that, but I don't think we can have only a common few annotations to describe every possible rendering layout.
EDIT: here are the changes I made related to the styling:
- In
Error.Diagnose.Style: (replacedAnnotationwith this)
type Style ann = IsAnnotation ann => Doc ann -> Doc AnsiStyle
-- | The class of annotation, allowing to map each to a given color style.
--
-- Every annotation used in a 'Style' must implemented this typeclass.
class IsAnnotation ann where
-- | To be used with 'reAnnotate'.
--
-- Transforms the custom annotations into color annotations as described by 'AnsiStyle'.
mkColor :: ann -> AnsiStyle
- In
Error.Diagnose.Diagnostic.Internal: (changed the types to useIsAnnotation)
type Layout msg ann = (IsAnnotation ann, Pretty msg) => Bool -> Int -> Diagnostic msg -> Doc ann
-- | Prints a 'Diagnostic' onto a specific 'Handle'.
printDiagnostic ::
(MonadIO m, Pretty msg, IsAnnotation ann) =>
-- | The handle onto which to output the diagnostic.
Handle ->
-- | Should we print with unicode characters?
Bool ->
-- | 'False' to disable colors.
Bool ->
-- | The number of spaces each TAB character will span.
Int ->
-- | The style in which to output the diagnostic.
Style ann ->
-- | The layout to use to render the diagnostic.
Layout msg ann ->
-- | The diagnostic to output.
Diagnostic msg ->
m ()
printDiagnostic handle withUnicode withColors tabSize style layout diag =
liftIO $ hPutDoc handle ((if withColors then style else unAnnotate) $ layout withUnicode tabSize diag)
{-# INLINE printDiagnostic #-}
I can push them whenever you need them.
so either way I should hopefully be able to finish my prototype and share with you on GitHub in one or two days.
Don't worry at all, take all the time you need! There's no deadline for this at all. :)
I have been fighting with stack and GHC for debugging for a while, because the stack I use was built with GHC 8.10.4 and therefore has no support for
--io-manager=native.
By the way, do you think this is worth mentioning in the documentation?
All the Unicode stuff on Windows, like the with-utf8 package, what to do with GHC 9+ (and possibly other stuff I overlooked, like the fact that you should call setLocale LC_ALL before using wcwidth), etc.
By the way, do you think this is worth mentioning in the documentation?
Yes, I think that would be very helpful for users of this library, especially Haskell newcomers or people who have not explicitly dealt with Unicode issues in the past. It could be in the README, the package documentation, or even a stand-alone tutorial if you wish.
All the Unicode stuff on Windows, like the
with-utf8package, what to do with GHC 9+ (and possibly other stuff I overlooked, like the fact that you should callsetLocale LC_ALLbefore usingwcwidth), etc.
In my experience, with-utf8 is especially helpful to prevent crashing; I believe by using the Main.Utf8.withUtf8 wrapper on main, the locale of standard I/O handles (stdin, stdout, stderr) are set to lenient versions, so they will not fail for invalid characters (that is, characters which cannot be encoded in the target encoding). However, it can still be overly defensive where some Unicode characters encodable in target encoding also get replaced by ? (like I showed in previous screenshots), possibly due to the fact that GHC is still using iconv (amd it somehow failed to detect the target encoding correctly) [^1].
[^1]: This is according to a GHC issue I read a while ago, which might be outdated now.
On the other hand, at least according to the tests I have done these days, the RTS option --io-manager=native (and yes, it is only available in GHC 9+) should fix the Unicode problem on its own, both preventing the crash and getting the correct output without replacements. Yet I would still use with-utf8 because I personally prefer to enforce UTF-8 encoding, and I believe you can't be too cautious on such things.
For wcwidth, I actually did not know about the LC_ALL thing. But the Haskell implementation (both the previous one and the one in my PR) should not depend on the locale, because it unconditionally uses the embedded Unicode database.
I can elaborate on these points later if you wish to include them in the doc.
For
wcwidth, I actually did not know about theLC_ALLthing. But the Haskell implementation (both the previous one and the one in my PR) should not depend on the locale, because it unconditionally uses the embedded Unicode database.
This is included in the documentation, but is needed only for the FFI wcwidth (I guess it would not work with some locales like LC_C, or at least not correctly).
This is indeed unneeded if it uses an embedded Unicode database (which is what you PRed there, which was already present but unpublished and worsely coded).
I can elaborate on these points later if you wish to include them in the doc.
I pretty much would like to include them in the docs, yes.
This would save some time for people who never got Unicode issues and also myself as I won't have to deal with issues about that.
A tutorial is already present in the Error.Diagnose module, and there's also a FAQ section in there. I guess we could insert new questions (with the Haskell errors when trying to print unicode characters) and answer them there!
I'm curious because I didn't know one could do that, but how did you make the little linkable footer at the end of your comment?
I'm curious because I didn't know one could do that, but how did you make the little linkable footer at the end of your comment?
I believe it is part of the extended Markdown syntax: use [^1] or [^longlabel] for where the marker should be placed, and write later (in a separate paragraph) [^1]: the actual footnote text. It doesn't matter what label you use (as long as they don't clash), nor where you place the footnote text: the marker will always be numbers starting from 1, and the footnotes will always go to the end of the comment.
Here is a GitHub blog that announced this syntax is supported on GitHub.
A quick update on wcwidth. It turns out the Haskell implementation is incorrect from the very beginning: all control characters (and according to the implementation, "control characters" also include the space character) are reported to have width -1 (perhaps to indicate an error). So this was the source of the "everything is misaligned" screenshot, instead of Windows Terminal. Now I believe I will have to validate the logic of that implementation myself and give it a patch or rewrite.
I see. That's a bit weird but I never really took a look at the Haskell implementation of wcwidth so I guess it makes sense.
The negative return codes should probably be handled in the getLine_ function (as of now, we don't, which causes some trouble when trying to print control characters because they also have a width of -1 according to the C implementation of wcwidth, if I understand the specification correctly).
RETURN VALUE The
wcwidth()function shall either return 0 (ifwcis a null wide-character code), or return the number of column positions to be occupied by the wide-character codewc, or return -1 (ifwcdoes not correspond to a printable wide-character code).
I hope you'll be able to figure all this out. Unfortunately, I don't see the original maintainer giving help on this as they don't seem to use Haskell anymore, but I hope you could take ownership of it? Nobody else seems to be quite interested in it though...
I have just discovered that the original pure Haskell implementation was based on this pure Python implementation. Maybe there's some stuff you could gather from it? (checking from the issue tab, there's only a few minor bugs, but it should work for most Unicode standard versions)
I was also searching on this topic, and found out there once was a char::width implementation in Rust's libstd, but it did not make it into stable Rust. This char::width and the Python implementation you mentioned both are based on Markus Kuhn's implementation (which dates back to 2007, Unicode 5.0). I actually quite like the Rust implementation, especially its signature: it returns an Option, which forces the user to explicitly handle the control characters.
Unfortunately, I don't see the original maintainer giving help on this as they don't seem to use Haskell anymore, but I hope you could take ownership of it? Nobody else seems to be quite interested in it though...
Yes, I also don't expect to receive help from the original maintainer. To be fair, the original package was essentially a thin wrapper around the C function wcwidth, so they probably did not expect the mess at all. Although I am not sure about taking ownership, partly because there is only one dependency on wcwidth on Stackage, and also because I am not familiar to maintaining packages on Hackage at all. Anyway, I will first prepare a patch. After that we can decide whether to include the implementation here or try to update the wcwidth package on Hackage.
And BTW, the bug for space character is due to these line:
https://github.com/solidsnack/wcwidth/blob/900e463d9472aba3620198d2f32987b7402be5b9/Data/Char/WCWidthHaskell.hs#L413-L417
The ranges is inclusive on both ends, because that is how the data is stored in UCD. But here apparently the 32 was intended to be exclusive (due to the use of < in the C implementation).
I will take some time to also check for other bugs before resubmitting the PR.
And regarding the width of control characters, I believe it is perfectly okay to just special case for tab, backspace, etc. and assume the width is 1 for the rest. Most terminal emulators also don't handle the control characters, and display them as solid rectangles (or whatever the "missing" glyph is in the font), which usually have width 1.
I actually quite like the Rust implementation, especially its signature: it returns an Option, which forces the user to explicitly handle the control characters.
I have to admit that I also quite like that! Definitely better.
Although I am not sure about taking ownership, partly because there is only one dependency on wcwidth on Stackage, and also because I am not familiar to maintaining packages on Hackage at all.
I think that the dependency count accounts only for package within stackage snapshots. For example, diagnose isn't, yet it depends on wcwidth (I think that chapelure also depends on it? Or they only planned on depending on it as mentioned by one of their maintainers in https://github.com/Mesabloo/diagnose/issues/1#issuecomment-1108754786). So I'm not quite sure how accurate this is.
And BTW, the bug for space character is due to these line: https://github.com/solidsnack/wcwidth/blob/900e463d9472aba3620198d2f32987b7402be5b9/Data/Char/WCWidthHaskell.hs#L413-L417 The ranges is inclusive on both ends, because that is how the data is stored in UCD. But here apparently the 32 was intended to be exclusive (due to the use of < in the C implementation).
I quickly took a look at your new implementation, and I was ready to leave a comment exactly at this exact line in your code, but I simply could not understand whether your binary search was inclusive or exclusive on the last number of each range. But I'm happy that you found the issue!
And regarding the width of control characters, I believe it is perfectly okay to just special case for tab, backspace, etc. and assume the width is 1 for the rest. Most terminal emulators also don't handle the control characters, and display them as solid rectangles (or whatever the "missing" glyph is in the font), which usually have width 1.
We already had a special case for the tab characters (so that you as the user choose how many spaces are used to render a tab character). I'm worried though that there will be many special cases for most of control characters. But if they are rendered anyway as single cell characters, then I guess it's fine to consider most of them as having a width of 1.
For the most part, WCWidth relies on the native wcwidth implementation, from wchar.h. On Linux, Mac OS, FreeBSD, &c, the WCWidthHaskell implementation is simply not used. Reading over @ruifengx's post, I see that he uses Windows; and this is the one platform where the Haskell implementation is used.
There is a mistake, on WCWidthHaskell.hs:415 -- 32 should be 31. This leads to ASCII whitespace being treated like a control character. This can be fixed easily.
@Mesabloo is correct that, per POSIX, wcwidth is supposed to return -1 for a wide variety of characters.
Please find attached, the ranges pulled from the native implementation on a recent Macintosh.
Oh hi there!
There is a mistake, on WCWidthHaskell.hs:415 --
32should be31. This leads to ASCII whitespace being treated like a control character. This can be fixed easily.
This is pretty much what @ruifengx figured in https://github.com/Mesabloo/diagnose/issues/11#issuecomment-1236337638. I believe that a fix will be coming your way in the next few days (along with a rewrite of the pure Haskell implementation for a better/more efficient search strategy).
@Mesabloo is correct that, per POSIX, wcwidth is supposed to return -1 for a wide variety of characters.
However, would it be ok to provide a more “Haskell-ish” way of handling -1 (which in the C world mostly mean “errors”) via a Maybe Int? Or we could add another function (like wcwidthMay :: Char -> Maybe Int which would act like wcwidth but return Nothing instead of -1) for this purpose, while still exposing the POSIX wcwidth?
What do you think about it @solidsnack?
It took me much longer than I expected, but anyway I have just finished a prototype of the codespan-reporting style. It definitely needs more fine-tuning, and I will need some time to merge your changes here. But the good news is it is working on all the test cases. Here are some screenshots:
| Test Case | Screenshot |
|---|---|
| Single-line markers |  |
| Multi-line markers |  |
| Unicode & Tab |  |
| Source line omitting |  |
Currently the placement of multi-line markers is not ideal:
| Current | Improvement (not yet) |
|---|---|
 |
 |
I have a plan of improvement and will rewrite this part soon.
Below are some thoughts during the coding these days:
-
In
codespan-reportingthe crate, there are five different levels of severity. I coded theLayoutin such a way that all the five are allowed, but onlyErrorandWarningare actually used:data Severity = Bug | Error -- from `Err` | Warning -- from `Warn` | Help | Note deriving (Show, Eq, Ord)I don't know if it makes sense to add all these severities here, or to further parametrise the
Report(and thereforeDiagnostic) type by an additionalsevvariable. -
Similar things (but in the opposite way) for marker types.
codespan-reportingonly has primary and secondary labels, and we have four (This,Where,Maybe,Blank).Blankis very convenient for including source lines in the report without making other visual differences, which I hopecodespan-reportinghad in the beginning. We will have to decide what to do with the styling forWhereandMaybe. Currently I just assigned the colour for secondary labels to both of them, which is not ideal. The solution would be to pick one more colour to distinguish between them, or (again) to parametrise theReport(and thereforeDiagnostic) type by an additionallblvariable. -
The code it is around ~370 lines, and unfortunately I have not (yet) add enough comments to make the logic clear (the naming there could probably be improved, too). The logic follows
codespan_reporting::term::renderer(the comments there are really helpful). You can find the current version of my implementation in my fork. I can submit a draft PR if you prefer. -
I ended up rewriting most of the rendering logic because it was easier to follow the original logic. However, there is one function worth mentioning that I reused (and changed a bit):
replaceLinesWith :: Doc ann -> (Doc ann -> Doc ann) -> Doc ann -> Doc ann replaceLinesWith repl t = go where go Line = repl go Fail = Fail go Empty = Empty go (Char '\n') = repl go (Char c) = Char c go (Text _ s) = mconcat $ intersperse repl $ map t $ uncurry Text . (T.length &&& id) <$> T.split (== '\n') s go (FlatAlt f d) = FlatAlt (go f) (go d) go (Cat c d) = Cat (go c) (go d) go (Nest n d) = Nest n (go d) go (Union c d) = Union (go c) (go d) go (Column f) = Column (go . f) go (Nesting f) = Nesting (go . f) go (Annotated ann doc) = Annotated ann (go doc) go (WithPageWidth f) = WithPageWidth (go . f)This function is critical for supporting multi-line messages. I added an additional parameter
t :: Doc ann -> Doc ann, this transformation is applied to every line of the inputDocseparately, so thatrepldoes not get affected by the annotation on the inputDoc. -
I am not 100% sure whether the source range in the report should be a closed range or right half-open. I assumed it to be a closed range, but the rendering looks weird for some test cases.
This already looks nice! Although is it me or do the single-line This markers have an extra caret when going until EOL?
- In codespan-reporting the crate, there are five different levels of severity. [...] I don't know if it makes sense to add all these severities here, or to further parametrise the Report (and therefore Diagnostic) type by an additional sev variable.
- Similar things (but in the opposite way) for marker types. [...]
I don't want to give a definitive answer yet, but:
- The
HelpandNoteseverities are already handled by theNotedata type, aren't they? Unless they mean something else Bugis just a more critical version orError. Is it really that useful to have it in practice, or can one only rely onError?- If we were to include all those new severities as parts of
Report, we'd need colors etc. for every other layout (currently: the ariadne-like, a GCC-like and a typescript-like) + additional ways to format them (perhaps differently?) I have not quite found a usecase for bothHelpandNotethough: I usually am satisfied byWhere
- The code it is around ~370 lines, and unfortunately I have not (yet) add enough comments to make the logic clear (the naming there could probably be improved, too). [...]
I don't think code length is really an issue, unless it leads to very poor performances (which is not that huge of an issue because rendering is usually done only once in the pipeline). My code for the ariadne-layout is also quite big. Don't forget that we'll refactor the common functions later on!
- I ended up rewriting most of the rendering logic because it was easier to follow the original logic. [...]
No problem here.
It's a shame that we need to have this replaceLinesWith function. Ideally, prettyprinter would allow us to specify “prefixes” to put when breaking lines (instead of just whitespaces).
In the mean time, I quite like how you rewrote it. Definitely better than my original one!
I am not 100% sure whether the source range in the report should be a closed range or right half-open. I assumed it to be a closed range, but the rendering looks weird for some test cases.
I don't think I understood. In some of the tests cases (which were borrowed from a few of my projects, namely nstar and zilch), the positions are put in weird positions (my original lexer/parser combination used to give positions which go “too far” into the stream). However, those tests cases opened a few bugs in the implementation of the ariadne-layout. This is why I kept them in the test suite. If this not what you meant, then I definitely did not understand, please pardon me.
Regarding the current output: it looks like it uses half unicode half ASCII. Do you intend it to be that way? Also, will you provide unicode-free alternatives? If not, then I think that deciding whether to provide Unicode+ASCII or just Unicode or just ASCII should be left to the implementor of the layout, hence moved outside of the core library. What do you think about it?
Although is it me or do the single-line
Thismarkers have an extra caret when going until EOL?
This is why I asked whether the source ranges should be closed or half-open (that is, should the larger end-point be inclusive or exclusive). I am currently assuming them to be inclusive on both ends, and I coded the rendering in such a way to allow "off-by-one" markers (pointing at technically where '\n' would be).
The
HelpandNoteseverities are already handled by theNotedata type, aren't they? Unless they mean something else.
AFAIK, in codespan-reporting the crate, it is possible to produce a diagnostic whose severity is "note" or "help". Such diagnostics are not attached to another "error" or "warning". I don't actually see a concrete use case for such stand-alone "note" or "help" diagnostics, but this is the status quo there, so I thought perhaps they have their own reasoning.
Regarding the current output: it looks like it uses half unicode half ASCII. Do you intend it to be that way?
I should have clarified this in the previous comment. All the screenshots are for the Unicode output (rendering style of codespan-reporting is somewhat simplistic). I picked the Unicode version because it looks prettier than the ASCII version. Anyway, here is a screenshot for the ASCII rendering for your information:

For switching between Unicode and ASCII, I followed the approach in the original crate. Instead of passing around a useUnicode boolean flag, I packed all marker characters/strings into a Chars record. In the Layout, I then switch between unicodeChars and asciiChars according to the useUnicode flag.
This is why I asked whether the source ranges should be closed or half-open (that is, should the larger end-point be inclusive or exclusive). I am currently assuming them to be inclusive on both ends, and I coded the rendering in such a way to allow "off-by-one" markers (pointing at technically where
'\n'would be).
Initially, the ranges were meant to be inclusive on both ends. However, every layout is free to handle ranges howeevr they want to, as long as this behavior is coherent within the layout, I guess.
AFAIK, in codespan-reporting the crate, it is possible to produce a diagnostic whose severity is "note" or "help". Such diagnostics are not attached to another "error" or "warning". I don't actually see a concrete use case for such stand-alone "note" or "help" diagnostics, but this is the status quo there, so I thought perhaps they have their own reasoning.
I see. I'm quite unsure how useful that is (usually, "notes"/"helps" are used to provide context/potential fixes for the current error/warning. Having standalone "notes"/"helps" seems weird in that setting: what are they adding context to then? Not sure if that's really useful...
I should have clarified this in the previous comment. All the screenshots are for the Unicode output (rendering style of codespan-reporting is somewhat simplistic). I picked the Unicode version because it looks prettier than the ASCII version. Anyway, here is a screenshot for the ASCII rendering for your information:
Looks great!
For switching between Unicode and ASCII, I followed the approach in the original crate. Instead of passing around a
useUnicodeboolean flag, I packed all marker characters/strings into aCharsrecord. In theLayout, I then switch betweenunicodeCharsandasciiCharsaccording to theuseUnicodeflag.
That's actually a very good idea. This makes the code more readable (instead of my usual long ugly ifs). That might be something worth pushing in the core of the library.
I think now I kind of know why Help etc. is made to be a stand-alone severity. Consider the following message produced by rustc:
error[E0106]: missing lifetime specifier
--> <source>:1:18
|
1 | pub fn test() -> &str {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime
|
1 | pub fn test() -> &'static str {
| +++++++
Note how the "help" is allowed to have its own markers. I agree that helps and notes should always be attached to some major error/warning, but my current implementation cannot produce the same output.
I want the new codespan-reporting style to be able to render the above diagnostic. One easy way out is to extend the severities. Or we could allow nested Report in note/help section. However, given the current API here, I can think of another possible way: to repurpose the Where/Maybe marker, so that e.g. This/Where markers correspond to primary/secondary markers, and Maybe markers are gathered separately for use in the help section (it would still be unclear which help they should attach to, if multiple helps are provided; I think a good-enough heuristic is to attach all those markers to the last help). The naming of these markers would become a bit unfortunate, but I guess it is not really a big deal.
After implementing this feature, the overall visual effects should look satisfactory to me. I will comment here again when I finish the implementation, and perhaps we can start working on eliminating the code duplication and aim at a merge.