BERTopic
 BERTopic copied to clipboard
BERTopic copied to clipboard
Inferior Performance without Stopwords Removal
Hi Martan,
First, I want to express my appreciation for your library and thank you for your effort to the community.
I'm a beginner in NLP :) and I'm going to read your paper after posting this issue. Even though you said in FAQ that "there is no need to preprocess the data." I found the model had an inferior performance without setting stopwords to "English" in CountVectorizer. This is what it looks like without stopwords removal:

This is what it looks like after stopwords removal:
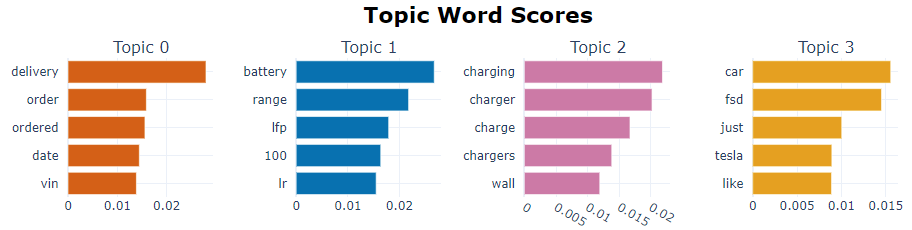
There are 13,000 replies consisting of only alphanumeric characters crawled from a forum thread. The thread is about Tesla model 3. Does this mean I need to manually remove modifiers like "the" and pronouns like "it" to get a reasonable result?
BTW, do you think it's feasible to create multiple topics in one document by dividing the document into sentences?
Thank you for your time answering my issue.
Best,
@MaartenGr will be able to be a lot more definitive, but I'll give it a go. So in terms of pre-processing the data it is a bit confusing when new to BERTopic. There are two discrete steps to creating a BERTopic topic model, the first is the embedding of the text - by default using BERT. There is no need, and it can be, probably is in fact, counter-productive to pre-process the data. BERT was developed to input text as it is written, so removing stop words etc. can easily remove information that BERT would otherwise use to embed the text.
Once the text is embedded it is reduced by UMAP to make it viable for clustering by HDBSCAN. HDBSCAN creates the clusters which form the basis for the topic model. Unlike the embedding process, the topic model essentially uses a "Bag Of Words" approach where all the documents comprising one topic are aggregated and then TFIDF is run on them to extract the significant words. In my experience the larger those topics are, the better the out-of-the-box word selection is. In your case you are getting a lot of words that don't contribute to the topic specifically - so you can, and in my opinion, should, add words to the stoplist of the CountVectorizer so that they are not included in your lists. In this way you 'cleaning' the text, but only after the BERT embeddings have been organized into topic clusters.
For me the trick with BERTopic is to understand that the underlying text and the topic model are two different entities. Of course there is hopefully a linkage between the semantics of the topic clusters and the resulting topic model, but that linkage can be arguably weak. I hope that helps and that I didn't get too much wrong in my description of how BERTopic works.
Thank you Dan. I find your explanation really helpful. It's a nice summary of how BERTopic works and it also solved my issue about stopwords removal :).
Thanks @drob-xx! The explanation definitely covers the most important aspects of this phenomenon. There is a small thing that I would like to add, namely the c-TF-IDF procedure. Although similar to the classical TF-IDF procedure, c-TF-IDF does a much better job in creating topic representations as it takes into account that there are topics instead of documents. It should not be confused with the traditional procedure as the results can differ quite a bit. Having said that, it does benefit from having many topics as that will give more information about potential stop words. I am currently working on some things that might help with that but it is in such an early stage that I cannot share anything definitive.
It's good to hear that you are going to make some improvements on the model. I Look forward to your new release in the near future.
@NanachiHub @MaartenGr @drob-xx There is a question that is not answered from the original topic.
"BTW, do you think it's feasible to create multiple topics in one document by dividing the document into sentences?"
I have the same question. If I have scraped data from a webpage. Will sentence splitting bring better performance than keeping the text as a paragraph (content in <p> tag).
Thank you for creating this awesome package!
"BTW, do you think it's feasible to create multiple topics in one document by dividing the document into sentences?"
It highly depends on the embedding model that you use but yes, in general, it is worthwhile to divide the document into sentences. When you use a package like SentenceTransformers, then the representations are generally better for sentences instead of longer documents as longer documents get truncated. Having said that, this might not necessarily be the case for all models as there are several models that do a much better job handling longer documents. All in all, if the text that you have is long and you are convinced that the text contains multiple topics, then splitting is likely to be worthwhile.
Due to inactivity and with the new release adding features to the topic extraction procedure, I'll be closing this for now. Let me know if you have any other questions related to this and I'll make sure to re-open the issue!