VkFFT
 VkFFT copied to clipboard
VkFFT copied to clipboard
2D C2C Convolution
Hi there,
Apologies in advance if this is not the proper platform for my question.
I'm trying to have vkfft perform a simple 2D C2C convolution and leverage the no-reorder and zero-padding optimizations. I'm confused by the documentation and all the examples that show some form of matrix x vector convolution.
In my application, the kernel is not padded (the circular convolution is desired), but the input data is. I haven't enabled zeropadding optimization yet, but instead pad the input data beforehand.
The kernel generation and actual convolution are done in 2 separate steps, by the same function: I re-use the same plan for kernel generation and convolution. This might be my first mistake?
The function sets up the dimension, sizes, FFT precision, C2C, the same way in both cases.
I have the following, pre-allocated, device buffers:
- VkBuffer devBuffer; // FFT buffer
- VkBuffer kerBuffer; // Kernel buffer
1. Kernel generation
configuration.kernelConvolution = true; configuration.coordinateFeatures = 1; configuration.buffer = &devBuffer;
performVulkanFFT(vkGPU, &app, &launchParams, -1, 1);
copyBuffer(devBuffer, kerBuffer);
2. Convolution
configuration.kernelConvolution = false; configuration.performConvolution = true; configuration.symmetricKernel = false; configuration.coordinateFeatures = 1; configuration.conjugateConvolution = 0; configuration.matrixConvolution = 0; configuration.crossPowerSpectrumNormalization = 0; configuration.numberKernels = 1;
configuration.buffer = &devBuffer; configuration.kernel = &kerBuffer;
resFFT = performVulkanFFT(vkGPU, &app, &launchParams, -1, 1);
Questions
Anything wrong with sharing the same plan for kernel generation and convolution? Could I enable zeropadding optimization without rebuilding the plan? (The input data would be half the size (in both dimensions) as the allocated buffer and the 0-padding would fill up the rest) Shouldn't I run performVulkanFFTiFFT, instead? Does VulkanFFT perform the inverse transfrom automatically when .performConvolution = true?
On a different note: any plan to support zero-padding around the data, instead of only before/after?
Hello,
kernel generation must be done with a separate plan, as the convolution kernel has all the code merged in one shader (last FFT pass, convolution, first IFFT pass). Same for the zero-padding - if it is not enabled during plan creation, there will be no corresponding to its lines of code generated to enable later on.
performVulkanFFTiFFT is a benchmark function that just does FFT + IFFT multiple times in a row. It is supposed to serve as an example, which you can just copy-paste and tune to your needs, as it is not licensed at all. (you can see its code here https://github.com/DTolm/VkFFT/blob/master/benchmark_scripts/vkFFT_scripts/src/utils_VkFFT.cpp)
Zero-padding is only a read-write optimization. You enable zero-padding for input data and produce FFT of a kernel with a separate plan without zero-padding.
No-reorder optimization is only used if you have sequences bigger than ~ 2^12 in x and 2^10 in y and z. Otherwise, there is no difference.
If you are concerned with plan creation overhead, you can store compiled kernels and reuse them afterward, provided the plan configuration hasn't changed.
On a different note: any plan to support zero-padding around the data, instead of only before/after?
so far supported modes are before/after or inside. It is indeed not that hard to add support for around the data padding, but I need to think about how to make it as general as possible (multiple zero parts of a sequence).
Feel free to ask other questions if something is not as clear!
Best regards, Dmitrii
Hello Dmitrii,
Thank you again for the very quick answer!
I indeed found out that I needed to re-generate de plan for the actual convolution. My updating the configuration did not update the actual VkFFTApplication. I am now destroying the kernel plan and creating a new plan for the actual convolution. It now “almost” produces the desired result. The data seems to be shifted by a few pixels compared to the convolution performed via normal FFT/IFFT, but I’ll figure it out :)
Best, Clement
On Thu, Mar 10, 2022 at 12:08 PM Tolmachev Dmitrii @.***> wrote:
Hello,
kernel generation must be done with a separate plan, as the convolution kernel has all the code merged in one shader (last FFT pass, convolution, first IFFT pass). Same for the zero-padding - if it is not enabled during plan creation, there will be no corresponding to its lines of code generated to enable later on.
performVulkanFFTiFFT is a benchmark function that just does FFT + IFFT multiple times in a row. It is supposed to serve as an example, which you can just copy-paste and tune to your needs, as it is not licensed at all. (you can see its code here https://github.com/DTolm/VkFFT/blob/master/benchmark_scripts/vkFFT_scripts/src/utils_VkFFT.cpp )
Zero-padding is only a read-write optimization. You enable zero-padding for input data and produce FFT of a kernel with a separate plan without zero-padding.
No-reorder optimization is only used if you have sequences bigger than ~ 2^12 in x and 2^10 in y and z. Otherwise, there is no difference.
If you are concerned with plan creation overhead, you can store compiled kernels and reuse them afterward, provided the plan configuration hasn't changed.
On a different note: any plan to support zero-padding around the data, instead of only before/after?
so far supported modes are before/after or inside. It is indeed not that hard to add support for around the data padding, but I need to think about how to make it as general as possible (multiple zero parts of a sequence).
Feel free to ask other questions if something is not as clear!
Best regards, Dmitrii
— Reply to this email directly, view it on GitHub https://github.com/DTolm/VkFFT/issues/66#issuecomment-1064458117, or unsubscribe https://github.com/notifications/unsubscribe-auth/ALUDRZIYD3NR2RZFJWJ4XCTU7JJEPANCNFSM5QNNQAEA . Triage notifications on the go with GitHub Mobile for iOS https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675 or Android https://play.google.com/store/apps/details?id=com.github.android&referrer=utm_campaign%3Dnotification-email%26utm_medium%3Demail%26utm_source%3Dgithub.
You are receiving this because you authored the thread.Message ID: @.***>
I get VKFFT_ERROR_FAILED_SHADER_PARSE error when trying to build my convolution application in FP16. I'm using config.halfPrecision = true; The kernel creation application is created just fine, however.
If I use halfPrecisionMemoryOnly I don't get the issue. In this mode, is the kernel expected to be generated in FP16, or in FP32?
Note: I get NaNs and Infs when trying to perform larger FFTs followed by IFFTs (say > 4096x2048) in FP16, with or without normalization. I can get around it by not using normalization and instead pre-scaling the data by 1/X before the IFFT and scaling the result again by 1/Y.
halfPrecisionMemoryOnly does only first read and last write to half-precision, rest is done in FP32. This may have an effect in multidimensional case, as there all intermediate reads/writes will be with additional memory and in FP32.
Honestly, I didn't do much of testing on half-precision as I was not satisfied with what the accuracy of such small data format provides (the 0,0,0 element is much bigger than everything else after FFT as it is a sum of them, so accuracy drop on it related to other elements is noticeable).
I am not sure why it produces VKFFT_ERROR_FAILED_SHADER_PARSE error though. It must print the failed shader code as well, can you send it here?
Here's the error I get:
User 23 - VkFFT C2C 2D convolution w/ zero-padding benchmark in fp16 (half) precision System Size Memory Time (msec) Bandwidth (GB/s) #version 450
#extension GL_EXT_shader_16bit_storage : require
layout (local_size_x = 32, local_size_y = 16, local_size_z = 1) in; const float loc_PI = 3.1415926535897932384626433832795f; const float loc_SQRT1_2 = 0.70710678118654752440084436210485f; layout(std430, binding = 0) buffer DataIn{ f16vec2 inputs[16384]; };
layout(std430, binding = 1) buffer DataOut{ f16vec2 outputs[16384]; };
layout(std430, binding = 2) buffer Kernel_FFT{ f16vec2 kernel_obj[16384]; };
uint sharedStride = 32; shared vec2 sdata[4096];
void main() { vec2 temp_0; temp_0.x=0; temp_0.y=0; vec2 temp_1; temp_1.x=0; temp_1.y=0; vec2 temp_2; temp_2.x=0; temp_2.y=0; vec2 temp_3; temp_3.x=0; temp_3.y=0; vec2 temp_4; temp_4.x=0; temp_4.y=0; vec2 temp_5; temp_5.x=0; temp_5.y=0; vec2 temp_6; temp_6.x=0; temp_6.y=0; vec2 temp_7; temp_7.x=0; temp_7.y=0; vec2 w; w.x=0; w.y=0; vec2 loc_0; loc_0.x=0; loc_0.y=0; vec2 iw; iw.x=0; iw.y=0; uint stageInvocationID=0; uint blockInvocationID=0; uint sdataID=0; uint combinedID=0; uint inoutID=0; float angle=0; if (((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128) < 128) { inoutID = (1 * (gl_LocalInvocationID.y + 0) + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128)); inoutID = ((gl_GlobalInvocationID.x) % (128)) + (inoutID) * 128; temp_0=vec2(inputs[inoutID]); inoutID = (1 * (gl_LocalInvocationID.y + 16) + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128)); inoutID = ((gl_GlobalInvocationID.x) % (128)) + (inoutID) * 128; temp_1=vec2(inputs[inoutID]); inoutID = (1 * (gl_LocalInvocationID.y + 32) + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128)); inoutID = ((gl_GlobalInvocationID.x) % (128)) + (inoutID) * 128; temp_2=vec2(inputs[inoutID]); inoutID = (1 * (gl_LocalInvocationID.y + 48) + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128)); inoutID = ((gl_GlobalInvocationID.x) % (128)) + (inoutID) * 128; temp_3=vec2(inputs[inoutID]); inoutID = (1 * (gl_LocalInvocationID.y + 64) + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128)); inoutID = ((gl_GlobalInvocationID.x) % (128)) + (inoutID) * 128; temp_4=vec2(inputs[inoutID]); inoutID = (1 * (gl_LocalInvocationID.y + 80) + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128)); inoutID = ((gl_GlobalInvocationID.x) % (128)) + (inoutID) * 128; temp_5=vec2(inputs[inoutID]); inoutID = (1 * (gl_LocalInvocationID.y + 96) + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128)); inoutID = ((gl_GlobalInvocationID.x) % (128)) + (inoutID) * 128; temp_6=vec2(inputs[inoutID]); inoutID = (1 * (gl_LocalInvocationID.y + 112) + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128)); inoutID = ((gl_GlobalInvocationID.x) % (128)) + (inoutID) * 128; temp_7=vec2(inputs[inoutID]); } if (((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128) < 128) { stageInvocationID = (gl_LocalInvocationID.y+ 0) % (1); angle = stageInvocationID * 3.14159265358979312e+00f; w.x = cos(angle); w.y = sin(angle); loc_0.x = temp_4.x * w.x - temp_4.y * w.y; loc_0.y = temp_4.y * w.x + temp_4.x * w.y; temp_4.x = temp_0.x - loc_0.x; temp_4.y = temp_0.y - loc_0.y; temp_0.x = temp_0.x + loc_0.x; temp_0.y = temp_0.y + loc_0.y; loc_0.x = temp_5.x * w.x - temp_5.y * w.y; loc_0.y = temp_5.y * w.x + temp_5.x * w.y; temp_5.x = temp_1.x - loc_0.x; temp_5.y = temp_1.y - loc_0.y; temp_1.x = temp_1.x + loc_0.x; temp_1.y = temp_1.y + loc_0.y; loc_0.x = temp_6.x * w.x - temp_6.y * w.y; loc_0.y = temp_6.y * w.x + temp_6.x * w.y; temp_6.x = temp_2.x - loc_0.x; temp_6.y = temp_2.y - loc_0.y; temp_2.x = temp_2.x + loc_0.x; temp_2.y = temp_2.y + loc_0.y; loc_0.x = temp_7.x * w.x - temp_7.y * w.y; loc_0.y = temp_7.y * w.x + temp_7.x * w.y; temp_7.x = temp_3.x - loc_0.x; temp_7.y = temp_3.y - loc_0.y; temp_3.x = temp_3.x + loc_0.x; temp_3.y = temp_3.y + loc_0.y; w.x = cos(0.5fangle); w.y = sin(0.5fangle); loc_0.x = temp_2.x * w.x - temp_2.y * w.y; loc_0.y = temp_2.y * w.x + temp_2.x * w.y; temp_2.x = temp_0.x - loc_0.x; temp_2.y = temp_0.y - loc_0.y; temp_0.x = temp_0.x + loc_0.x; temp_0.y = temp_0.y + loc_0.y; loc_0.x = temp_3.x * w.x - temp_3.y * w.y; loc_0.y = temp_3.y * w.x + temp_3.x * w.y; temp_3.x = temp_1.x - loc_0.x; temp_3.y = temp_1.y - loc_0.y; temp_1.x = temp_1.x + loc_0.x; temp_1.y = temp_1.y + loc_0.y; iw.x = -w.y; iw.y = w.x; loc_0.x = temp_6.x * iw.x - temp_6.y * iw.y; loc_0.y = temp_6.y * iw.x + temp_6.x * iw.y; temp_6.x = temp_4.x - loc_0.x; temp_6.y = temp_4.y - loc_0.y; temp_4.x = temp_4.x + loc_0.x; temp_4.y = temp_4.y + loc_0.y; loc_0.x = temp_7.x * iw.x - temp_7.y * iw.y; loc_0.y = temp_7.y * iw.x + temp_7.x * iw.y; temp_7.x = temp_5.x - loc_0.x; temp_7.y = temp_5.y - loc_0.y; temp_5.x = temp_5.x + loc_0.x; temp_5.y = temp_5.y + loc_0.y; w.x = cos(0.25fangle); w.y = sin(0.25fangle); loc_0.x = temp_1.x * w.x - temp_1.y * w.y; loc_0.y = temp_1.y * w.x + temp_1.x * w.y; temp_1.x = temp_0.x - loc_0.x; temp_1.y = temp_0.y - loc_0.y; temp_0.x = temp_0.x + loc_0.x; temp_0.y = temp_0.y + loc_0.y; iw.x = -w.y; iw.y = w.x; loc_0.x = temp_3.x * iw.x - temp_3.y * iw.y; loc_0.y = temp_3.y * iw.x + temp_3.x * iw.y; temp_3.x = temp_2.x - loc_0.x; temp_3.y = temp_2.y - loc_0.y; temp_2.x = temp_2.x + loc_0.x; temp_2.y = temp_2.y + loc_0.y; iw.x = w.x * loc_SQRT1_2 - w.y * loc_SQRT1_2; iw.y = w.y * loc_SQRT1_2 + w.x * loc_SQRT1_2;
loc_0.x = temp_5.x * iw.x - temp_5.y * iw.y;
loc_0.y = temp_5.y * iw.x + temp_5.x * iw.y;
temp_5.x = temp_4.x - loc_0.x;
temp_5.y = temp_4.y - loc_0.y;
temp_4.x = temp_4.x + loc_0.x;
temp_4.y = temp_4.y + loc_0.y;
w.x = -iw.y;
w.y = iw.x;
loc_0.x = temp_7.x * w.x - temp_7.y * w.y;
loc_0.y = temp_7.y * w.x + temp_7.x * w.y;
temp_7.x = temp_6.x - loc_0.x;
temp_7.y = temp_6.y - loc_0.y;
temp_6.x = temp_6.x + loc_0.x;
temp_6.y = temp_6.y + loc_0.y;
loc_0 = temp_1;
temp_1 = temp_4;
temp_4 = loc_0;
loc_0 = temp_3;
temp_3 = temp_6;
temp_6 = loc_0;
} sharedStride = 32; barrier();
if (((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128) < 128) {
stageInvocationID = gl_LocalInvocationID.y + 0;
blockInvocationID = stageInvocationID;
stageInvocationID = stageInvocationID % 1;
blockInvocationID = blockInvocationID - stageInvocationID;
inoutID = blockInvocationID * 8;
inoutID = inoutID + stageInvocationID;
sdataID = inoutID + 0;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
temp_0.x = temp_0.x * 7.81250000000000000e-03f;
temp_0.y = temp_0.y * 7.81250000000000000e-03f;
sdata[sdataID] = temp_0;
sdataID = inoutID + 1;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
temp_1.x = temp_1.x * 7.81250000000000000e-03f;
temp_1.y = temp_1.y * 7.81250000000000000e-03f;
sdata[sdataID] = temp_1;
sdataID = inoutID + 2;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
temp_2.x = temp_2.x * 7.81250000000000000e-03f;
temp_2.y = temp_2.y * 7.81250000000000000e-03f;
sdata[sdataID] = temp_2;
sdataID = inoutID + 3;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
temp_3.x = temp_3.x * 7.81250000000000000e-03f;
temp_3.y = temp_3.y * 7.81250000000000000e-03f;
sdata[sdataID] = temp_3;
sdataID = inoutID + 4;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
temp_4.x = temp_4.x * 7.81250000000000000e-03f;
temp_4.y = temp_4.y * 7.81250000000000000e-03f;
sdata[sdataID] = temp_4;
sdataID = inoutID + 5;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
temp_5.x = temp_5.x * 7.81250000000000000e-03f;
temp_5.y = temp_5.y * 7.81250000000000000e-03f;
sdata[sdataID] = temp_5;
sdataID = inoutID + 6;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
temp_6.x = temp_6.x * 7.81250000000000000e-03f;
temp_6.y = temp_6.y * 7.81250000000000000e-03f;
sdata[sdataID] = temp_6;
sdataID = inoutID + 7;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
temp_7.x = temp_7.x * 7.81250000000000000e-03f;
temp_7.y = temp_7.y * 7.81250000000000000e-03f;
sdata[sdataID] = temp_7;
} barrier();
if (((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128) < 128) {
stageInvocationID = (gl_LocalInvocationID.y+ 0) % (8);
angle = stageInvocationID * 3.92699081698724139e-01f;
temp_0 = sdata[sharedStride*(gl_LocalInvocationID.y+0)+gl_LocalInvocationID.x];
temp_1 = sdata[sharedStride*(gl_LocalInvocationID.y+16)+gl_LocalInvocationID.x];
temp_2 = sdata[sharedStride*(gl_LocalInvocationID.y+32)+gl_LocalInvocationID.x];
temp_3 = sdata[sharedStride*(gl_LocalInvocationID.y+48)+gl_LocalInvocationID.x];
temp_4 = sdata[sharedStride*(gl_LocalInvocationID.y+64)+gl_LocalInvocationID.x];
temp_5 = sdata[sharedStride*(gl_LocalInvocationID.y+80)+gl_LocalInvocationID.x];
temp_6 = sdata[sharedStride*(gl_LocalInvocationID.y+96)+gl_LocalInvocationID.x];
temp_7 = sdata[sharedStride*(gl_LocalInvocationID.y+112)+gl_LocalInvocationID.x];
w.x = cos(angle);
w.y = sin(angle);
loc_0.x = temp_4.x * w.x - temp_4.y * w.y;
loc_0.y = temp_4.y * w.x + temp_4.x * w.y;
temp_4.x = temp_0.x - loc_0.x;
temp_4.y = temp_0.y - loc_0.y;
temp_0.x = temp_0.x + loc_0.x;
temp_0.y = temp_0.y + loc_0.y;
loc_0.x = temp_5.x * w.x - temp_5.y * w.y;
loc_0.y = temp_5.y * w.x + temp_5.x * w.y;
temp_5.x = temp_1.x - loc_0.x;
temp_5.y = temp_1.y - loc_0.y;
temp_1.x = temp_1.x + loc_0.x;
temp_1.y = temp_1.y + loc_0.y;
loc_0.x = temp_6.x * w.x - temp_6.y * w.y;
loc_0.y = temp_6.y * w.x + temp_6.x * w.y;
temp_6.x = temp_2.x - loc_0.x;
temp_6.y = temp_2.y - loc_0.y;
temp_2.x = temp_2.x + loc_0.x;
temp_2.y = temp_2.y + loc_0.y;
loc_0.x = temp_7.x * w.x - temp_7.y * w.y;
loc_0.y = temp_7.y * w.x + temp_7.x * w.y;
temp_7.x = temp_3.x - loc_0.x;
temp_7.y = temp_3.y - loc_0.y;
temp_3.x = temp_3.x + loc_0.x;
temp_3.y = temp_3.y + loc_0.y;
w.x = cos(0.5f*angle);
w.y = sin(0.5f*angle);
loc_0.x = temp_2.x * w.x - temp_2.y * w.y;
loc_0.y = temp_2.y * w.x + temp_2.x * w.y;
temp_2.x = temp_0.x - loc_0.x;
temp_2.y = temp_0.y - loc_0.y;
temp_0.x = temp_0.x + loc_0.x;
temp_0.y = temp_0.y + loc_0.y;
loc_0.x = temp_3.x * w.x - temp_3.y * w.y;
loc_0.y = temp_3.y * w.x + temp_3.x * w.y;
temp_3.x = temp_1.x - loc_0.x;
temp_3.y = temp_1.y - loc_0.y;
temp_1.x = temp_1.x + loc_0.x;
temp_1.y = temp_1.y + loc_0.y;
iw.x = -w.y;
iw.y = w.x;
loc_0.x = temp_6.x * iw.x - temp_6.y * iw.y;
loc_0.y = temp_6.y * iw.x + temp_6.x * iw.y;
temp_6.x = temp_4.x - loc_0.x;
temp_6.y = temp_4.y - loc_0.y;
temp_4.x = temp_4.x + loc_0.x;
temp_4.y = temp_4.y + loc_0.y;
loc_0.x = temp_7.x * iw.x - temp_7.y * iw.y;
loc_0.y = temp_7.y * iw.x + temp_7.x * iw.y;
temp_7.x = temp_5.x - loc_0.x;
temp_7.y = temp_5.y - loc_0.y;
temp_5.x = temp_5.x + loc_0.x;
temp_5.y = temp_5.y + loc_0.y;
w.x = cos(0.25f*angle);
w.y = sin(0.25f*angle);
loc_0.x = temp_1.x * w.x - temp_1.y * w.y;
loc_0.y = temp_1.y * w.x + temp_1.x * w.y;
temp_1.x = temp_0.x - loc_0.x;
temp_1.y = temp_0.y - loc_0.y;
temp_0.x = temp_0.x + loc_0.x;
temp_0.y = temp_0.y + loc_0.y;
iw.x = -w.y;
iw.y = w.x;
loc_0.x = temp_3.x * iw.x - temp_3.y * iw.y;
loc_0.y = temp_3.y * iw.x + temp_3.x * iw.y;
temp_3.x = temp_2.x - loc_0.x;
temp_3.y = temp_2.y - loc_0.y;
temp_2.x = temp_2.x + loc_0.x;
temp_2.y = temp_2.y + loc_0.y;
iw.x = w.x * loc_SQRT1_2 - w.y * loc_SQRT1_2;
iw.y = w.y * loc_SQRT1_2 + w.x * loc_SQRT1_2;
loc_0.x = temp_5.x * iw.x - temp_5.y * iw.y;
loc_0.y = temp_5.y * iw.x + temp_5.x * iw.y;
temp_5.x = temp_4.x - loc_0.x;
temp_5.y = temp_4.y - loc_0.y;
temp_4.x = temp_4.x + loc_0.x;
temp_4.y = temp_4.y + loc_0.y;
w.x = -iw.y;
w.y = iw.x;
loc_0.x = temp_7.x * w.x - temp_7.y * w.y;
loc_0.y = temp_7.y * w.x + temp_7.x * w.y;
temp_7.x = temp_6.x - loc_0.x;
temp_7.y = temp_6.y - loc_0.y;
temp_6.x = temp_6.x + loc_0.x;
temp_6.y = temp_6.y + loc_0.y;
loc_0 = temp_1;
temp_1 = temp_4;
temp_4 = loc_0;
loc_0 = temp_3;
temp_3 = temp_6;
temp_6 = loc_0;
} barrier();
if (((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128) < 128) {
stageInvocationID = gl_LocalInvocationID.y + 0;
blockInvocationID = stageInvocationID;
stageInvocationID = stageInvocationID % 8;
blockInvocationID = blockInvocationID - stageInvocationID;
inoutID = blockInvocationID * 8;
inoutID = inoutID + stageInvocationID;
sdataID = inoutID + 0;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
sdata[sdataID] = temp_0;
sdataID = inoutID + 8;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
sdata[sdataID] = temp_1;
sdataID = inoutID + 16;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
sdata[sdataID] = temp_2;
sdataID = inoutID + 24;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
sdata[sdataID] = temp_3;
sdataID = inoutID + 32;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
sdata[sdataID] = temp_4;
sdataID = inoutID + 40;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
sdata[sdataID] = temp_5;
sdataID = inoutID + 48;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
sdata[sdataID] = temp_6;
sdataID = inoutID + 56;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
sdata[sdataID] = temp_7;
} barrier();
if (((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128) < 128) {
stageInvocationID = (gl_LocalInvocationID.y+ 0) % (64);
angle = stageInvocationID * 4.90873852123405174e-02f;
temp_0 = sdata[sharedStride*(gl_LocalInvocationID.y+0)+gl_LocalInvocationID.x];
temp_4 = sdata[sharedStride*(gl_LocalInvocationID.y+64)+gl_LocalInvocationID.x];
w.x = cos(angle);
w.y = sin(angle);
loc_0.x = temp_4.x * w.x - temp_4.y * w.y;
loc_0.y = temp_4.y * w.x + temp_4.x * w.y;
temp_4.x = temp_0.x - loc_0.x;
temp_4.y = temp_0.y - loc_0.y;
temp_0.x = temp_0.x + loc_0.x;
temp_0.y = temp_0.y + loc_0.y;
stageInvocationID = (gl_LocalInvocationID.y+ 16) % (64);
angle = stageInvocationID * 4.90873852123405174e-02f;
temp_1 = sdata[sharedStride*(gl_LocalInvocationID.y+16)+gl_LocalInvocationID.x];
temp_5 = sdata[sharedStride*(gl_LocalInvocationID.y+80)+gl_LocalInvocationID.x];
w.x = cos(angle);
w.y = sin(angle);
loc_0.x = temp_5.x * w.x - temp_5.y * w.y;
loc_0.y = temp_5.y * w.x + temp_5.x * w.y;
temp_5.x = temp_1.x - loc_0.x;
temp_5.y = temp_1.y - loc_0.y;
temp_1.x = temp_1.x + loc_0.x;
temp_1.y = temp_1.y + loc_0.y;
stageInvocationID = (gl_LocalInvocationID.y+ 32) % (64);
angle = stageInvocationID * 4.90873852123405174e-02f;
temp_2 = sdata[sharedStride*(gl_LocalInvocationID.y+32)+gl_LocalInvocationID.x];
temp_6 = sdata[sharedStride*(gl_LocalInvocationID.y+96)+gl_LocalInvocationID.x];
w.x = cos(angle);
w.y = sin(angle);
loc_0.x = temp_6.x * w.x - temp_6.y * w.y;
loc_0.y = temp_6.y * w.x + temp_6.x * w.y;
temp_6.x = temp_2.x - loc_0.x;
temp_6.y = temp_2.y - loc_0.y;
temp_2.x = temp_2.x + loc_0.x;
temp_2.y = temp_2.y + loc_0.y;
stageInvocationID = (gl_LocalInvocationID.y+ 48) % (64);
angle = stageInvocationID * 4.90873852123405174e-02f;
temp_3 = sdata[sharedStride*(gl_LocalInvocationID.y+48)+gl_LocalInvocationID.x];
temp_7 = sdata[sharedStride*(gl_LocalInvocationID.y+112)+gl_LocalInvocationID.x];
w.x = cos(angle);
w.y = sin(angle);
loc_0.x = temp_7.x * w.x - temp_7.y * w.y;
loc_0.y = temp_7.y * w.x + temp_7.x * w.y;
temp_7.x = temp_3.x - loc_0.x;
temp_7.y = temp_3.y - loc_0.y;
temp_3.x = temp_3.x + loc_0.x;
temp_3.y = temp_3.y + loc_0.y;
} sharedStride = 32; if (((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128) < 128) { } if (((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128) < 128) { float temp_real0 = 0; float temp_imag0 = 0; inoutID = ((gl_GlobalInvocationID.x) % (128)) + ((gl_LocalInvocationID.y+0)+((gl_GlobalInvocationID.x)/128)%(1)+((gl_GlobalInvocationID.x)/128)(128)) * 128; temp_real0 += kernel_obj[inoutID+0].x * temp_0.x - kernel_obj[inoutID+0].y * temp_0.y; temp_imag0 += kernel_obj[inoutID+0].x * temp_0.y + kernel_obj[inoutID+0].y * temp_0.x; temp_0.x = temp_real0; temp_0.y = temp_imag0; temp_real0 = 0; temp_imag0 = 0; inoutID = ((gl_GlobalInvocationID.x) % (128)) + ((gl_LocalInvocationID.y+16)+((gl_GlobalInvocationID.x)/128)%(1)+((gl_GlobalInvocationID.x)/128)(128)) * 128; temp_real0 += kernel_obj[inoutID+0].x * temp_1.x - kernel_obj[inoutID+0].y * temp_1.y; temp_imag0 += kernel_obj[inoutID+0].x * temp_1.y + kernel_obj[inoutID+0].y * temp_1.x; temp_1.x = temp_real0; temp_1.y = temp_imag0; temp_real0 = 0; temp_imag0 = 0; inoutID = ((gl_GlobalInvocationID.x) % (128)) + ((gl_LocalInvocationID.y+32)+((gl_GlobalInvocationID.x)/128)%(1)+((gl_GlobalInvocationID.x)/128)(128)) * 128; temp_real0 += kernel_obj[inoutID+0].x * temp_2.x - kernel_obj[inoutID+0].y * temp_2.y; temp_imag0 += kernel_obj[inoutID+0].x * temp_2.y + kernel_obj[inoutID+0].y * temp_2.x; temp_2.x = temp_real0; temp_2.y = temp_imag0; temp_real0 = 0; temp_imag0 = 0; inoutID = ((gl_GlobalInvocationID.x) % (128)) + ((gl_LocalInvocationID.y+48)+((gl_GlobalInvocationID.x)/128)%(1)+((gl_GlobalInvocationID.x)/128)(128)) * 128; temp_real0 += kernel_obj[inoutID+0].x * temp_3.x - kernel_obj[inoutID+0].y * temp_3.y; temp_imag0 += kernel_obj[inoutID+0].x * temp_3.y + kernel_obj[inoutID+0].y * temp_3.x; temp_3.x = temp_real0; temp_3.y = temp_imag0; temp_real0 = 0; temp_imag0 = 0; inoutID = ((gl_GlobalInvocationID.x) % (128)) + ((gl_LocalInvocationID.y+64)+((gl_GlobalInvocationID.x)/128)%(1)+((gl_GlobalInvocationID.x)/128)(128)) * 128; temp_real0 += kernel_obj[inoutID+0].x * temp_4.x - kernel_obj[inoutID+0].y * temp_4.y; temp_imag0 += kernel_obj[inoutID+0].x * temp_4.y + kernel_obj[inoutID+0].y * temp_4.x; temp_4.x = temp_real0; temp_4.y = temp_imag0; temp_real0 = 0; temp_imag0 = 0; inoutID = ((gl_GlobalInvocationID.x) % (128)) + ((gl_LocalInvocationID.y+80)+((gl_GlobalInvocationID.x)/128)%(1)+((gl_GlobalInvocationID.x)/128)(128)) * 128; temp_real0 += kernel_obj[inoutID+0].x * temp_5.x - kernel_obj[inoutID+0].y * temp_5.y; temp_imag0 += kernel_obj[inoutID+0].x * temp_5.y + kernel_obj[inoutID+0].y * temp_5.x; temp_5.x = temp_real0; temp_5.y = temp_imag0; temp_real0 = 0; temp_imag0 = 0; inoutID = ((gl_GlobalInvocationID.x) % (128)) + ((gl_LocalInvocationID.y+96)+((gl_GlobalInvocationID.x)/128)%(1)+((gl_GlobalInvocationID.x)/128)(128)) * 128; temp_real0 += kernel_obj[inoutID+0].x * temp_6.x - kernel_obj[inoutID+0].y * temp_6.y; temp_imag0 += kernel_obj[inoutID+0].x * temp_6.y + kernel_obj[inoutID+0].y * temp_6.x; temp_6.x = temp_real0; temp_6.y = temp_imag0; temp_real0 = 0; temp_imag0 = 0; inoutID = ((gl_GlobalInvocationID.x) % (128)) + ((gl_LocalInvocationID.y+112)+((gl_GlobalInvocationID.x)/128)%(1)+((gl_GlobalInvocationID.x)/128)(128)) * 128; temp_real0 += kernel_obj[inoutID+0].x * temp_7.x - kernel_obj[inoutID+0].y * temp_7.y; temp_imag0 += kernel_obj[inoutID+0].x * temp_7.y + kernel_obj[inoutID+0].y * temp_7.x; temp_7.x = temp_real0; temp_7.y = temp_imag0; } barrier();
if (((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128) < 128) {
stageInvocationID = (gl_LocalInvocationID.y+ 0) % (1);
angle = stageInvocationID * 3.14159265358979312e+00f;
w.x = cos(angle);
w.y = sin(angle);
loc_0.x = temp_4.x * w.x - temp_4.y * w.y;
loc_0.y = temp_4.y * w.x + temp_4.x * w.y;
temp_4.x = temp_0.x - loc_0.x;
temp_4.y = temp_0.y - loc_0.y;
temp_0.x = temp_0.x + loc_0.x;
temp_0.y = temp_0.y + loc_0.y;
loc_0.x = temp_5.x * w.x - temp_5.y * w.y;
loc_0.y = temp_5.y * w.x + temp_5.x * w.y;
temp_5.x = temp_1.x - loc_0.x;
temp_5.y = temp_1.y - loc_0.y;
temp_1.x = temp_1.x + loc_0.x;
temp_1.y = temp_1.y + loc_0.y;
loc_0.x = temp_6.x * w.x - temp_6.y * w.y;
loc_0.y = temp_6.y * w.x + temp_6.x * w.y;
temp_6.x = temp_2.x - loc_0.x;
temp_6.y = temp_2.y - loc_0.y;
temp_2.x = temp_2.x + loc_0.x;
temp_2.y = temp_2.y + loc_0.y;
loc_0.x = temp_7.x * w.x - temp_7.y * w.y;
loc_0.y = temp_7.y * w.x + temp_7.x * w.y;
temp_7.x = temp_3.x - loc_0.x;
temp_7.y = temp_3.y - loc_0.y;
temp_3.x = temp_3.x + loc_0.x;
temp_3.y = temp_3.y + loc_0.y;
w.x = cos(0.5f*angle);
w.y = sin(0.5f*angle);
loc_0.x = temp_2.x * w.x - temp_2.y * w.y;
loc_0.y = temp_2.y * w.x + temp_2.x * w.y;
temp_2.x = temp_0.x - loc_0.x;
temp_2.y = temp_0.y - loc_0.y;
temp_0.x = temp_0.x + loc_0.x;
temp_0.y = temp_0.y + loc_0.y;
loc_0.x = temp_3.x * w.x - temp_3.y * w.y;
loc_0.y = temp_3.y * w.x + temp_3.x * w.y;
temp_3.x = temp_1.x - loc_0.x;
temp_3.y = temp_1.y - loc_0.y;
temp_1.x = temp_1.x + loc_0.x;
temp_1.y = temp_1.y + loc_0.y;
iw.x = -w.y;
iw.y = w.x;
loc_0.x = temp_6.x * iw.x - temp_6.y * iw.y;
loc_0.y = temp_6.y * iw.x + temp_6.x * iw.y;
temp_6.x = temp_4.x - loc_0.x;
temp_6.y = temp_4.y - loc_0.y;
temp_4.x = temp_4.x + loc_0.x;
temp_4.y = temp_4.y + loc_0.y;
loc_0.x = temp_7.x * iw.x - temp_7.y * iw.y;
loc_0.y = temp_7.y * iw.x + temp_7.x * iw.y;
temp_7.x = temp_5.x - loc_0.x;
temp_7.y = temp_5.y - loc_0.y;
temp_5.x = temp_5.x + loc_0.x;
temp_5.y = temp_5.y + loc_0.y;
w.x = cos(0.25f*angle);
w.y = sin(0.25f*angle);
loc_0.x = temp_1.x * w.x - temp_1.y * w.y;
loc_0.y = temp_1.y * w.x + temp_1.x * w.y;
temp_1.x = temp_0.x - loc_0.x;
temp_1.y = temp_0.y - loc_0.y;
temp_0.x = temp_0.x + loc_0.x;
temp_0.y = temp_0.y + loc_0.y;
iw.x = -w.y;
iw.y = w.x;
loc_0.x = temp_3.x * iw.x - temp_3.y * iw.y;
loc_0.y = temp_3.y * iw.x + temp_3.x * iw.y;
temp_3.x = temp_2.x - loc_0.x;
temp_3.y = temp_2.y - loc_0.y;
temp_2.x = temp_2.x + loc_0.x;
temp_2.y = temp_2.y + loc_0.y;
iw.x = w.x * loc_SQRT1_2 - w.y * loc_SQRT1_2;
iw.y = w.y * loc_SQRT1_2 + w.x * loc_SQRT1_2;
loc_0.x = temp_5.x * iw.x - temp_5.y * iw.y;
loc_0.y = temp_5.y * iw.x + temp_5.x * iw.y;
temp_5.x = temp_4.x - loc_0.x;
temp_5.y = temp_4.y - loc_0.y;
temp_4.x = temp_4.x + loc_0.x;
temp_4.y = temp_4.y + loc_0.y;
w.x = -iw.y;
w.y = iw.x;
loc_0.x = temp_7.x * w.x - temp_7.y * w.y;
loc_0.y = temp_7.y * w.x + temp_7.x * w.y;
temp_7.x = temp_6.x - loc_0.x;
temp_7.y = temp_6.y - loc_0.y;
temp_6.x = temp_6.x + loc_0.x;
temp_6.y = temp_6.y + loc_0.y;
loc_0 = temp_1;
temp_1 = temp_4;
temp_4 = loc_0;
loc_0 = temp_3;
temp_3 = temp_6;
temp_6 = loc_0;
} sharedStride = 32; barrier();
if (((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128) < 128) {
stageInvocationID = gl_LocalInvocationID.y + 0;
blockInvocationID = stageInvocationID;
stageInvocationID = stageInvocationID % 1;
blockInvocationID = blockInvocationID - stageInvocationID;
inoutID = blockInvocationID * 8;
inoutID = inoutID + stageInvocationID;
sdataID = inoutID + 0;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
temp_0.x = temp_0.x * 7.81250000000000000e-03f;
temp_0.y = temp_0.y * 7.81250000000000000e-03f;
sdata[sdataID] = temp_0;
sdataID = inoutID + 1;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
temp_1.x = temp_1.x * 7.81250000000000000e-03f;
temp_1.y = temp_1.y * 7.81250000000000000e-03f;
sdata[sdataID] = temp_1;
sdataID = inoutID + 2;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
temp_2.x = temp_2.x * 7.81250000000000000e-03f;
temp_2.y = temp_2.y * 7.81250000000000000e-03f;
sdata[sdataID] = temp_2;
sdataID = inoutID + 3;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
temp_3.x = temp_3.x * 7.81250000000000000e-03f;
temp_3.y = temp_3.y * 7.81250000000000000e-03f;
sdata[sdataID] = temp_3;
sdataID = inoutID + 4;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
temp_4.x = temp_4.x * 7.81250000000000000e-03f;
temp_4.y = temp_4.y * 7.81250000000000000e-03f;
sdata[sdataID] = temp_4;
sdataID = inoutID + 5;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
temp_5.x = temp_5.x * 7.81250000000000000e-03f;
temp_5.y = temp_5.y * 7.81250000000000000e-03f;
sdata[sdataID] = temp_5;
sdataID = inoutID + 6;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
temp_6.x = temp_6.x * 7.81250000000000000e-03f;
temp_6.y = temp_6.y * 7.81250000000000000e-03f;
sdata[sdataID] = temp_6;
sdataID = inoutID + 7;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
temp_7.x = temp_7.x * 7.81250000000000000e-03f;
temp_7.y = temp_7.y * 7.81250000000000000e-03f;
sdata[sdataID] = temp_7;
} barrier();
if (((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128) < 128) {
stageInvocationID = (gl_LocalInvocationID.y+ 0) % (8);
angle = stageInvocationID * 3.92699081698724139e-01f;
temp_0 = sdata[sharedStride*(gl_LocalInvocationID.y+0)+gl_LocalInvocationID.x];
temp_1 = sdata[sharedStride*(gl_LocalInvocationID.y+16)+gl_LocalInvocationID.x];
temp_2 = sdata[sharedStride*(gl_LocalInvocationID.y+32)+gl_LocalInvocationID.x];
temp_3 = sdata[sharedStride*(gl_LocalInvocationID.y+48)+gl_LocalInvocationID.x];
temp_4 = sdata[sharedStride*(gl_LocalInvocationID.y+64)+gl_LocalInvocationID.x];
temp_5 = sdata[sharedStride*(gl_LocalInvocationID.y+80)+gl_LocalInvocationID.x];
temp_6 = sdata[sharedStride*(gl_LocalInvocationID.y+96)+gl_LocalInvocationID.x];
temp_7 = sdata[sharedStride*(gl_LocalInvocationID.y+112)+gl_LocalInvocationID.x];
w.x = cos(angle);
w.y = sin(angle);
loc_0.x = temp_4.x * w.x - temp_4.y * w.y;
loc_0.y = temp_4.y * w.x + temp_4.x * w.y;
temp_4.x = temp_0.x - loc_0.x;
temp_4.y = temp_0.y - loc_0.y;
temp_0.x = temp_0.x + loc_0.x;
temp_0.y = temp_0.y + loc_0.y;
loc_0.x = temp_5.x * w.x - temp_5.y * w.y;
loc_0.y = temp_5.y * w.x + temp_5.x * w.y;
temp_5.x = temp_1.x - loc_0.x;
temp_5.y = temp_1.y - loc_0.y;
temp_1.x = temp_1.x + loc_0.x;
temp_1.y = temp_1.y + loc_0.y;
loc_0.x = temp_6.x * w.x - temp_6.y * w.y;
loc_0.y = temp_6.y * w.x + temp_6.x * w.y;
temp_6.x = temp_2.x - loc_0.x;
temp_6.y = temp_2.y - loc_0.y;
temp_2.x = temp_2.x + loc_0.x;
temp_2.y = temp_2.y + loc_0.y;
loc_0.x = temp_7.x * w.x - temp_7.y * w.y;
loc_0.y = temp_7.y * w.x + temp_7.x * w.y;
temp_7.x = temp_3.x - loc_0.x;
temp_7.y = temp_3.y - loc_0.y;
temp_3.x = temp_3.x + loc_0.x;
temp_3.y = temp_3.y + loc_0.y;
w.x = cos(0.5f*angle);
w.y = sin(0.5f*angle);
loc_0.x = temp_2.x * w.x - temp_2.y * w.y;
loc_0.y = temp_2.y * w.x + temp_2.x * w.y;
temp_2.x = temp_0.x - loc_0.x;
temp_2.y = temp_0.y - loc_0.y;
temp_0.x = temp_0.x + loc_0.x;
temp_0.y = temp_0.y + loc_0.y;
loc_0.x = temp_3.x * w.x - temp_3.y * w.y;
loc_0.y = temp_3.y * w.x + temp_3.x * w.y;
temp_3.x = temp_1.x - loc_0.x;
temp_3.y = temp_1.y - loc_0.y;
temp_1.x = temp_1.x + loc_0.x;
temp_1.y = temp_1.y + loc_0.y;
iw.x = -w.y;
iw.y = w.x;
loc_0.x = temp_6.x * iw.x - temp_6.y * iw.y;
loc_0.y = temp_6.y * iw.x + temp_6.x * iw.y;
temp_6.x = temp_4.x - loc_0.x;
temp_6.y = temp_4.y - loc_0.y;
temp_4.x = temp_4.x + loc_0.x;
temp_4.y = temp_4.y + loc_0.y;
loc_0.x = temp_7.x * iw.x - temp_7.y * iw.y;
loc_0.y = temp_7.y * iw.x + temp_7.x * iw.y;
temp_7.x = temp_5.x - loc_0.x;
temp_7.y = temp_5.y - loc_0.y;
temp_5.x = temp_5.x + loc_0.x;
temp_5.y = temp_5.y + loc_0.y;
w.x = cos(0.25f*angle);
w.y = sin(0.25f*angle);
loc_0.x = temp_1.x * w.x - temp_1.y * w.y;
loc_0.y = temp_1.y * w.x + temp_1.x * w.y;
temp_1.x = temp_0.x - loc_0.x;
temp_1.y = temp_0.y - loc_0.y;
temp_0.x = temp_0.x + loc_0.x;
temp_0.y = temp_0.y + loc_0.y;
iw.x = -w.y;
iw.y = w.x;
loc_0.x = temp_3.x * iw.x - temp_3.y * iw.y;
loc_0.y = temp_3.y * iw.x + temp_3.x * iw.y;
temp_3.x = temp_2.x - loc_0.x;
temp_3.y = temp_2.y - loc_0.y;
temp_2.x = temp_2.x + loc_0.x;
temp_2.y = temp_2.y + loc_0.y;
iw.x = w.x * loc_SQRT1_2 - w.y * loc_SQRT1_2;
iw.y = w.y * loc_SQRT1_2 + w.x * loc_SQRT1_2;
loc_0.x = temp_5.x * iw.x - temp_5.y * iw.y;
loc_0.y = temp_5.y * iw.x + temp_5.x * iw.y;
temp_5.x = temp_4.x - loc_0.x;
temp_5.y = temp_4.y - loc_0.y;
temp_4.x = temp_4.x + loc_0.x;
temp_4.y = temp_4.y + loc_0.y;
w.x = -iw.y;
w.y = iw.x;
loc_0.x = temp_7.x * w.x - temp_7.y * w.y;
loc_0.y = temp_7.y * w.x + temp_7.x * w.y;
temp_7.x = temp_6.x - loc_0.x;
temp_7.y = temp_6.y - loc_0.y;
temp_6.x = temp_6.x + loc_0.x;
temp_6.y = temp_6.y + loc_0.y;
loc_0 = temp_1;
temp_1 = temp_4;
temp_4 = loc_0;
loc_0 = temp_3;
temp_3 = temp_6;
temp_6 = loc_0;
} barrier();
if (((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128) < 128) {
stageInvocationID = gl_LocalInvocationID.y + 0;
blockInvocationID = stageInvocationID;
stageInvocationID = stageInvocationID % 8;
blockInvocationID = blockInvocationID - stageInvocationID;
inoutID = blockInvocationID * 8;
inoutID = inoutID + stageInvocationID;
sdataID = inoutID + 0;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
sdata[sdataID] = temp_0;
sdataID = inoutID + 8;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
sdata[sdataID] = temp_1;
sdataID = inoutID + 16;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
sdata[sdataID] = temp_2;
sdataID = inoutID + 24;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
sdata[sdataID] = temp_3;
sdataID = inoutID + 32;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
sdata[sdataID] = temp_4;
sdataID = inoutID + 40;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
sdata[sdataID] = temp_5;
sdataID = inoutID + 48;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
sdata[sdataID] = temp_6;
sdataID = inoutID + 56;
sdataID = sharedStride * sdataID;
sdataID = sdataID + gl_LocalInvocationID.x;
sdata[sdataID] = temp_7;
} barrier();
if (((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128) < 128) {
stageInvocationID = (gl_LocalInvocationID.y+ 0) % (64);
angle = stageInvocationID * 4.90873852123405174e-02f;
temp_0 = sdata[sharedStride*(gl_LocalInvocationID.y+0)+gl_LocalInvocationID.x];
temp_4 = sdata[sharedStride*(gl_LocalInvocationID.y+64)+gl_LocalInvocationID.x];
w.x = cos(angle);
w.y = sin(angle);
loc_0.x = temp_4.x * w.x - temp_4.y * w.y;
loc_0.y = temp_4.y * w.x + temp_4.x * w.y;
temp_4.x = temp_0.x - loc_0.x;
temp_4.y = temp_0.y - loc_0.y;
temp_0.x = temp_0.x + loc_0.x;
temp_0.y = temp_0.y + loc_0.y;
stageInvocationID = (gl_LocalInvocationID.y+ 16) % (64);
angle = stageInvocationID * 4.90873852123405174e-02f;
temp_1 = sdata[sharedStride*(gl_LocalInvocationID.y+16)+gl_LocalInvocationID.x];
temp_5 = sdata[sharedStride*(gl_LocalInvocationID.y+80)+gl_LocalInvocationID.x];
w.x = cos(angle);
w.y = sin(angle);
loc_0.x = temp_5.x * w.x - temp_5.y * w.y;
loc_0.y = temp_5.y * w.x + temp_5.x * w.y;
temp_5.x = temp_1.x - loc_0.x;
temp_5.y = temp_1.y - loc_0.y;
temp_1.x = temp_1.x + loc_0.x;
temp_1.y = temp_1.y + loc_0.y;
stageInvocationID = (gl_LocalInvocationID.y+ 32) % (64);
angle = stageInvocationID * 4.90873852123405174e-02f;
temp_2 = sdata[sharedStride*(gl_LocalInvocationID.y+32)+gl_LocalInvocationID.x];
temp_6 = sdata[sharedStride*(gl_LocalInvocationID.y+96)+gl_LocalInvocationID.x];
w.x = cos(angle);
w.y = sin(angle);
loc_0.x = temp_6.x * w.x - temp_6.y * w.y;
loc_0.y = temp_6.y * w.x + temp_6.x * w.y;
temp_6.x = temp_2.x - loc_0.x;
temp_6.y = temp_2.y - loc_0.y;
temp_2.x = temp_2.x + loc_0.x;
temp_2.y = temp_2.y + loc_0.y;
stageInvocationID = (gl_LocalInvocationID.y+ 48) % (64);
angle = stageInvocationID * 4.90873852123405174e-02f;
temp_3 = sdata[sharedStride*(gl_LocalInvocationID.y+48)+gl_LocalInvocationID.x];
temp_7 = sdata[sharedStride*(gl_LocalInvocationID.y+112)+gl_LocalInvocationID.x];
w.x = cos(angle);
w.y = sin(angle);
loc_0.x = temp_7.x * w.x - temp_7.y * w.y;
loc_0.y = temp_7.y * w.x + temp_7.x * w.y;
temp_7.x = temp_3.x - loc_0.x;
temp_7.y = temp_3.y - loc_0.y;
temp_3.x = temp_3.x + loc_0.x;
temp_3.y = temp_3.y + loc_0.y;
} sharedStride = 32; if (((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128) < 128) { } if (((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128) < 128) { inoutID = (gl_LocalInvocationID.y + 0) * 1 + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128); if((inoutID % 128 < 64)||(inoutID % 128 >= 128)){ inoutID = ((gl_GlobalInvocationID.x) % (128)) + (1 * (gl_LocalInvocationID.y + 0) + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128)) * 128; outputs[inoutID] = f16vec2(temp_0); } inoutID = (gl_LocalInvocationID.y + 16) * 1 + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128); if((inoutID % 128 < 64)||(inoutID % 128 >= 128)){ inoutID = ((gl_GlobalInvocationID.x) % (128)) + (1 * (gl_LocalInvocationID.y + 16) + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128)) * 128; outputs[inoutID] = f16vec2(temp_1); } inoutID = (gl_LocalInvocationID.y + 32) * 1 + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128); if((inoutID % 128 < 64)||(inoutID % 128 >= 128)){ inoutID = ((gl_GlobalInvocationID.x) % (128)) + (1 * (gl_LocalInvocationID.y + 32) + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128)) * 128; outputs[inoutID] = f16vec2(temp_2); } inoutID = (gl_LocalInvocationID.y + 48) * 1 + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128); if((inoutID % 128 < 64)||(inoutID % 128 >= 128)){ inoutID = ((gl_GlobalInvocationID.x) % (128)) + (1 * (gl_LocalInvocationID.y + 48) + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128)) * 128; outputs[inoutID] = f16vec2(temp_3); } inoutID = (gl_LocalInvocationID.y + 64) * 1 + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128); if((inoutID % 128 < 64)||(inoutID % 128 >= 128)){ inoutID = ((gl_GlobalInvocationID.x) % (128)) + (1 * (gl_LocalInvocationID.y + 64) + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128)) * 128; outputs[inoutID] = f16vec2(temp_4); } inoutID = (gl_LocalInvocationID.y + 80) * 1 + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128); if((inoutID % 128 < 64)||(inoutID % 128 >= 128)){ inoutID = ((gl_GlobalInvocationID.x) % (128)) + (1 * (gl_LocalInvocationID.y + 80) + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128)) * 128; outputs[inoutID] = f16vec2(temp_5); } inoutID = (gl_LocalInvocationID.y + 96) * 1 + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128); if((inoutID % 128 < 64)||(inoutID % 128 >= 128)){ inoutID = ((gl_GlobalInvocationID.x) % (128)) + (1 * (gl_LocalInvocationID.y + 96) + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128)) * 128; outputs[inoutID] = f16vec2(temp_6); } inoutID = (gl_LocalInvocationID.y + 112) * 1 + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128); if((inoutID % 128 < 64)||(inoutID % 128 >= 128)){ inoutID = ((gl_GlobalInvocationID.x) % (128)) + (1 * (gl_LocalInvocationID.y + 112) + ((gl_GlobalInvocationID.x) / 128) % (1)+((gl_GlobalInvocationID.x) / 128) * (128)) * 128; outputs[inoutID] = f16vec2(temp_7); } } }
ERROR: 0:447: '' : wrong operand types: no operation '' exists that takes a left-hand operand of type ' temp float16_t' and a right operand of type ' temp highp float' (or there is no acceptable conversion) ERROR: 0:447: '' : compilation terminated ERROR: 2 compilation errors. No code generated.
VkFFT shader type: 1
I have another problem with zero padding and convolution mode, in FP32 this time.
My code that performs 2D C2C convolution works just fine in FP32 when I don't use zero padding optimization.
However, as soon as I enable the optimization, I get the input image replicated many times (like an infinity mirror), in the proper location (lower right quadrant - I pad the beginning of the input sequence), instead of the expected blurred image.
The only difference in code is enabling zero padding, versus not:
fwdConfig.performZeropadding[0] = true; fwdConfig.performZeropadding[1] = true; fwdConfig.performZeropadding[2] = false; fwdConfig.fft_zeropad_left[0] = 0; fwdConfig.fft_zeropad_left[1] = 0; fwdConfig.fft_zeropad_right[0] = config_.size[0] / 2; fwdConfig.fft_zeropad_right[1] = config_.size[1] / 2;
I tested zero padding and no-reorder optimization in forward FFT only and the results are as expected. I only get the problem in convolution mode.
Enabling/disabling padding for the kernel generation works fine, which confirms the above. I even tested adding noise to the padded region of the kernel, to confirm it is not used by vkfft when enabling zero-padding: it produces the expected results.
In all cases, the input images are the full extent (= padding is applied by the calling application, in this case MATLAB).
Here's the full initialization code:
`VkFFTResult VkFFTContext::init(bool isGlslangInitialized) { VkFFTResult resFFT = VKFFT_SUCCESS; VkResult res = VK_SUCCESS;
uint64_t elems = std::accumulate(dims_.cbegin(), dims_.cend(), 1, std::multiplies<uint64_t>());
FFTPrecision bufferPrecision = precision_;
FFTPrecision kernelPrecision = bufferPrecision;
// Allocate input buffer (device)
bufferSize_ = 2 * typeSize[bufferPrecision] * elems;
resFFT = allocateExternalBuffer(gpu_,
&devBuffer_,
&devMem_,
VK_BUFFER_USAGE_STORAGE_BUFFER_BIT | VK_BUFFER_USAGE_TRANSFER_SRC_BIT | VK_BUFFER_USAGE_TRANSFER_DST_BIT,
VK_MEMORY_HEAP_DEVICE_LOCAL_BIT,
getDefaultMemHandleType(),
bufferSize_);
if (resFFT != VKFFT_SUCCESS)
{
mexErrMsgTxt("Could not allocate device buffer!");
return resFFT;
}
// Allocate kernel buffer (device)
kernelSize_ = 2 * typeSize[kernelPrecision] * elems;
resFFT = allocateExternalBuffer(gpu_,
&kerBuffer_,
&kerMem_,
VK_BUFFER_USAGE_STORAGE_BUFFER_BIT | VK_BUFFER_USAGE_TRANSFER_SRC_BIT | VK_BUFFER_USAGE_TRANSFER_DST_BIT,
VK_MEMORY_HEAP_DEVICE_LOCAL_BIT,
getDefaultMemHandleType(),
kernelSize_);
if (resFFT != VKFFT_SUCCESS)
{
mexErrMsgTxt("Could not allocate kernel buffer!");
return resFFT;
}
// Setup VkFFTConfiguration
config_.device = &gpu_->device;
config_.queue = &gpu_->queue;
config_.fence = &gpu_->fence;
config_.commandPool = &gpu_->commandPool;
config_.physicalDevice = &gpu_->physicalDevice;
config_.isCompilerInitialized = isGlslangInitialized;
config_.FFTdim = std::count_if(dims_.cbegin(), dims_.cend(), [](auto s) {return s > 1; });
config_.size[0] = dims_[0];
config_.size[1] = dims_[1];
config_.size[2] = dims_[2];
config_.doublePrecision = (bufferPrecision == FFT_PRECISION_DOUBLE);
config_.halfPrecisionMemoryOnly = (bufferPrecision == FFT_PRECISION_HALF);
//config_.halfPrecision = (bufferPrecision == FFT_PRECISION_HALF);
config_.performR2C = 0;
config_.normalize = 0;
config_.buffer = &devBuffer_;
config_.bufferSize = &bufferSize_;
config_.kernel = &kerBuffer_;
config_.kernelSize = &kernelSize_;
config_.numberKernels = 1;
config_.matrixConvolution = 0;
// Create staging buffer (host<>device transfers)
stagingSize_ = std::max(bufferSize_, kernelSize_);
resFFT = allocateBuffer(gpu_,
&stagingBuffer_,
&stagingMem_,
VK_BUFFER_USAGE_TRANSFER_SRC_BIT | VK_BUFFER_USAGE_TRANSFER_DST_BIT,
VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT | VK_MEMORY_PROPERTY_HOST_COHERENT_BIT | VK_MEMORY_PROPERTY_HOST_CACHED_BIT,
stagingSize_);
if (resFFT != VKFFT_SUCCESS)
{
mexErrMsgTxt("Could not allocate staging buffer!");
return resFFT;
}
res = vkMapMemory(gpu_->device, stagingMem_, 0, stagingSize_, 0, &stagingPtr_);
if (resFFT != VKFFT_SUCCESS) return resFFT;
// Init CUDA launch config
const int device = 0;
cudaDeviceProp prop = {};
checkCudaErrors(cudaSetDevice(device));
checkCudaErrors(cudaGetDeviceProperties(&prop, device));
threads_ = prop.warpSize;
// Import Vulkan device buffers into CUDA for gpuArray support
importCudaExternalMemory((void **)&cudaDevPtr_, cudaDevMem_, devMem_, bufferSize_, getDefaultMemHandleType());
importCudaExternalMemory((void **)&cudaKerPtr_, cudaKerMem_, kerMem_, kernelSize_, getDefaultMemHandleType());
if (cudaDevPtr_ != nullptr && cudaKerPtr_ != nullptr)
{
// Create CUDA I/O event and stream
checkCudaErrors(cudaStreamCreate(&streamIO_));
checkCudaErrors(cudaEventCreate(&transferComplete_));
}
else
{
return VKFFT_ERROR_FAILED_TO_FIND_MEMORY;
}
// Initialize applications .
// Kernel generation
VkFFTConfiguration kerConfig = config_;
kerConfig.kernelConvolution = true;
//kerConfig.halfPrecision = (kernelPrecision == FFT_PRECISION_HALF);
kerConfig.halfPrecisionMemoryOnly = (kernelPrecision == FFT_PRECISION_HALF);
kerConfig.coordinateFeatures = 1;
kerConfig.buffer = &kerBuffer_;
kerConfig.bufferSize = &kernelSize_;
kerConfig.kernel = 0;
kerConfig.kernelSize = 0;
resFFT = initializeVkFFT(&kernelApp_, kerConfig);
if (resFFT != VKFFT_SUCCESS)
{
mexErrMsgIdAndTxt("vkfft:PlanCreationError", "Could not create kernel VkFFT plan (%d)!", resFFT);
return resFFT;
}
// Forward transform
VkFFTConfiguration fwdConfig = config_;
fwdConfig.kernelConvolution = false;
fwdConfig.performConvolution = true;
fwdConfig.symmetricKernel = false;
fwdConfig.coordinateFeatures = 1;
fwdConfig.conjugateConvolution = 0;
fwdConfig.crossPowerSpectrumNormalization = 0;
fwdConfig.performZeropadding[0] = true;
fwdConfig.performZeropadding[1] = true;
fwdConfig.performZeropadding[2] = false;
fwdConfig.fft_zeropad_left[0] = 0;
fwdConfig.fft_zeropad_left[1] = 0;
fwdConfig.fft_zeropad_right[0] = config_.size[0] / 2;
fwdConfig.fft_zeropad_right[1] = config_.size[1] / 2;
resFFT = initializeVkFFT(&fwdApp_, fwdConfig);
if (resFFT != VKFFT_SUCCESS)
{
mexErrMsgIdAndTxt("vkfft:PlanCreationError", "Could not create forward VkFFT plan (%d)!", resFFT);
return resFFT;
}
return resFFT;
}`
Hello,
some of the issues should be resolved (namely half-precsision compile errors). As for the beginning of sequence padding - in my tests it also worked now, however, I am not sure if they are similar to yours, so please check it.
Best regards, Dmitrii
Hello Dmitrii,
I confirm the convolution application can be created successfully in fp16 now, thank you! The problem of precision still persists, though, and I can't use it with the FFT size I need (> 3k x 2k), unfortunately. I think if you scale the output of the FFT stage by 1/size[0], do the multiplication, the IFFT and then scale again by 1/size[1] we might get meaningful results out of it. If we could control the scaling post FFT and post IFFT separately, we could potentially use fp16 in more applications.
I tested the convolution mode with 0-padding and came to the following conclusion: it works correctly for FFT sizes < 2048 x 2048, but I get the same "infinity mirror" type of result for sizes > 2k. I assume it has something to do with the .disableReorderFourStep optimization that is enabled for bigger sizes? I don't have the issue if I do a normal FFT / IFFT with 0-padding enabled and disableReorderFourStep enabled. Something is different in convolution mode.
Thank you for all your efforts! Best, Clement
Dear Clement,
I assume it has something to do with the .disableReorderFourStep optimization that is enabled for bigger sizes?
Yes, the issue was that zero-padding code was inserted at incorrect places in some complicated cases. The issue is that the kernel code and logic get extremely tangled and complex when multiple algorithms are used together, like zero-padding, convolution and multi-upload FFTs. Some of the combinations are still not implemented fully (like Bluestein FFT for big primes + convolutions). I try to fix the issues as soon as they are reported, so thank you for the help in this regard. It should be working for your systems now.
I think if you scale the output of the FFT stage by 1/size[0], do the multiplication, the IFFT and then scale again by 1/size[1] we might get meaningful results out of it.
Unfortunately, this won't help, as the ratio between the 0-corner element (which is the sum of all inputs) and other elements gets out of the dynamic range of FP16 for your system sizes, and this issue is not solvable by uniform scaling.
Best regards, Dmitrii
Dear Dmitrii,
Your newest version works better now, but it seems like it is computing more samples than it should in the vertical direction (which, coming from a MATLAB array, corresponds to the first dimension). While I'm expecting 1/4 of the 2D window to have meaningful data, I get ~25% extra data vertically :) As a result, the computations take 25% longer than the equivalent FFT + IFFT with same padding and disabled four step.
We're almost there! :)
Best, Clement
While I'm expecting 1/4 of the 2D window to have meaningful data, I get ~25% extra data vertically :)
This is intended. The initial first axis zero-padding works only for the first dimension - after that frequency data takes full length, so the next axis can't use zero-padding assumption. This is also the reasoning behind VkFFT modifying some of the memory areas that were zero during convolution. So the second quadrant will always be modified by VkFFT in your case.
As a result, the computations take 25% longer than the equivalent FFT + IFFT with same padding and disabled four step.
I am not sure on how you did the comparison - convolution calculation also has memory transfers taken by kernel upload to chip, which are non-negligible.
Best regards, Dmitrii
This is intended. The initial first axis zero-padding works only for the first dimension - after that frequency data takes full length, so the next axis can't use zero-padding assumption. This is also the reasoning behind VkFFT modifying some of the memory areas that were zero during convolution. So the second quadrant will always be modified by VkFFT in your case.
For reference, the padding is the first half of both X and Y axes (2D transform).
The previous versions (up to 1.2.22) do produce a 1/4 image when using either the convolution or manually performing FFT + IFFT with 0-padding and disableReorderFourStep enable. Of course, the result for the convolution mode is wrong in that version, but the ROI is the same (as established above).
1.2.22 : FFT + IFFT w/ zero-padding and disableReorderFourStep optimizations
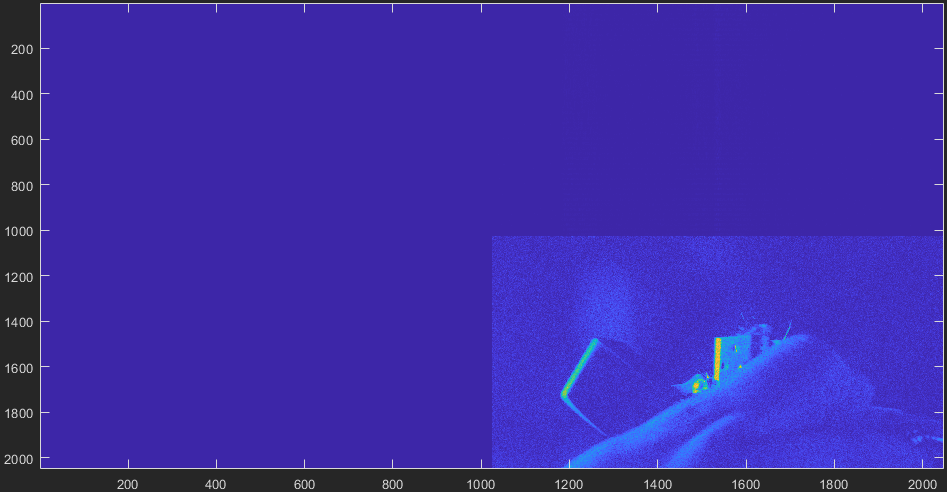
1.2.23 : convolution mode or FFT + IFFT w/ same optimizations
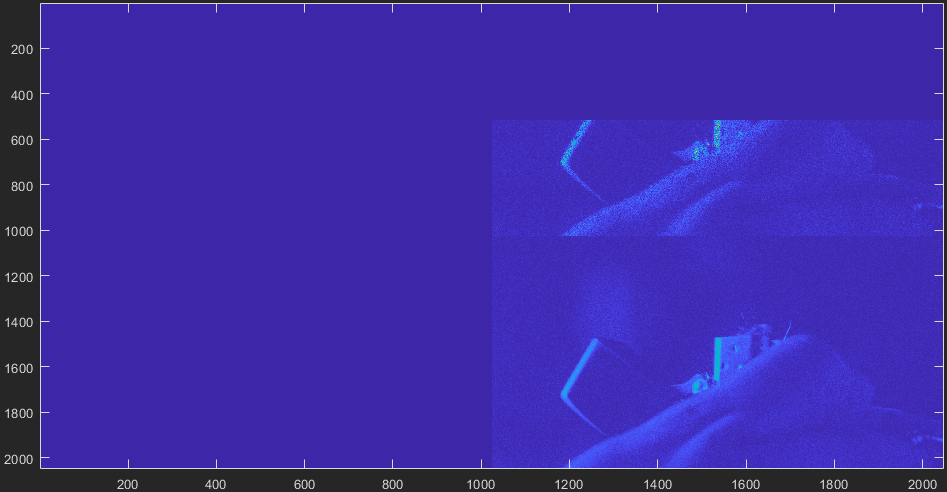
With 1.2.23, both FFT + IFFT and convolution do produce > 1/4 image of useful data.
1.2.22 does the convolution in 2.144 msec, while 1.2.23 does it in 2.82 msec.
@Clemasteredge can you post the shaders code printed during execution with keepShaderCode enabled for both images? It will speed up finding out the issue. Thanks!
I'm a bit confused by the shader printing. One of my application (FFT benchmark) generates shader prints that are way longer than my MATLAB application. Also, the MATLAB application does not generate anything in convolution mode... I'll look into it, but for now here's what is generated by my MATLAB application (that produced the 2 images above). v10222_4kx4k_zeropad_disableFourStep.txt v10223_4kx4k_zeropad_disableFourStep.txt
@Clemasteredge I have identified and fixed the issue, thanks! As for shader printing - if enabled it will print all the kernels encountered during execution, which is why it may be long in actual applications. And convolution kernels are pretty long themselves.
Nailed it! Thank you so much for your efforts :)
I'll try to get fp16 convolution working (applying scaling before multiplication/IFFT) now. If only Visual Studio didn't crash when stepping through fftw (there's a known problem with large files that M$ doesn't care to fix...).